Почему context compression ломает AI coding agents
Context compression заставляет AI coding agents работать по сокращённой версии реальности: отсюда потеря деталей, context rot и ложная уверенность.
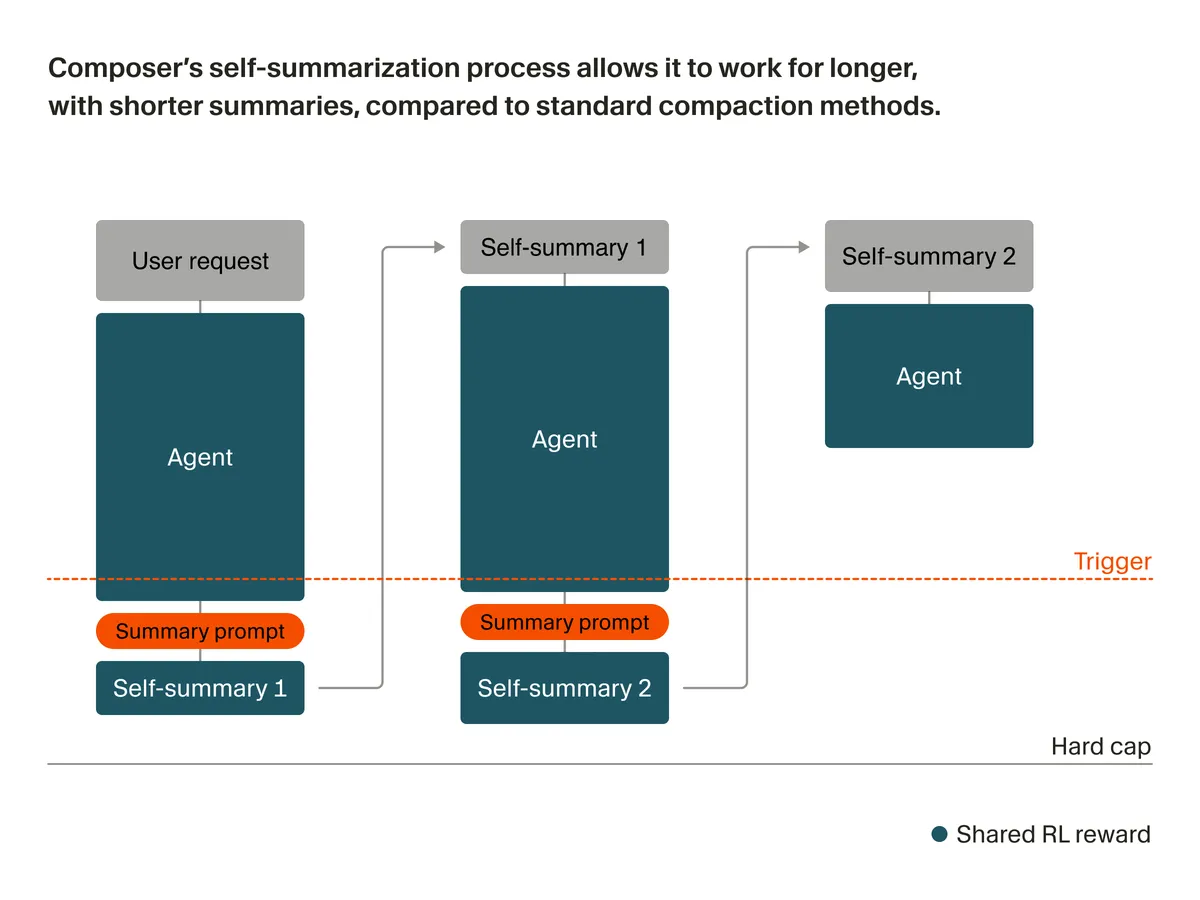
По состоянию на 4 мая 2026 года разговор про AI coding agents слишком часто сводят к простому вопросу: какая модель умнее, быстрее и дешевле. Но у этих систем есть другая, более тихая точка отказа. В документации Cursor сказано, что длинные чаты система автоматически пересказывает, а большие файлы и папки может отдавать модели в сжатом виде, вплоть до состояния, где остаётся только имя файла. Это не баг конкретного продукта. Это обычная цена длинной агентной сессии. Проблема начинается в тот момент, когда рабочая память агента опирается уже не на исходный код и документы, а на их сокращённую версию.
Именно поэтому кластер про ИИ для разработчиков нельзя сводить к сравнению интерфейсов и тарифов. У агента для программирования есть свой цикл деградации: окно контекста разрастается, система ужимает старые решения и длинные файлы, важная деталь уезжает в середину траектории, после чего агент продолжает действовать уже не по исходной картине мира, а по её краткому пересказу. Снаружи это выглядит как внезапная тупость модели. На деле ломается сама механика памяти.
Что такое context compression в агентной разработке
Под context compression здесь имеется в виду не только команда «суммируй всё выше». Это штатный режим выживания любой длинной агентной сессии. Cursor описывает два ключевых механизма: старые сообщения сворачиваются в краткий пересказ, а крупные файлы и папки подаются модели в сжатом виде. Если материала слишком много даже для этого режима, документация отдельно упоминает состояние significantly condensed, где у модели может остаться только имя файла. При этом Cursor в Max Mode пишет о контекстном окне на 200k токенов в обычном режиме и о более длинных окнах на отдельных моделях при включённом расширении. Номинально токенов много. Практически система всё равно должна решить, что оставить живым, а что заменить короткой выжимкой.
Отсюда и главная инженерная ошибка: большое окно начинают путать с полной картиной мира. Но агент видит не весь репозиторий, а урезанную выборку. Он может помнить сигнатуру функции и забыть защитное условие в середине файла. Может помнить, что staging уже проверяли, и забыть, что токен лежал в старом production-конфиге. Может помнить итог прошлого спора и уже не помнить, где именно было опровержение.
| Механизм | Что подтверждено источником | Какой риск возникает у агента |
|---|---|---|
| Автопересказ чата | Cursor пишет, что старые сообщения автоматически пересказываются, когда диалог перерастает окно контекста. | Ранние ограничения и оговорки превращаются в короткую выжимку, а не в исходный аргумент. |
| Сжатые и сильно сжатые файлы | По документации Cursor большие файлы могут быть поданы как структурная выжимка, а в крайнем случае модель видит только имя файла. | Агент начинает опираться на форму файла, не видя конкретную реализацию и побочные эффекты. |
| Позиционный перекос в длинном контексте | Lost in the Middle показывает, что длинноконтекстные модели хуже используют важную информацию из середины входа, чем с краёв. | Критическая деталь есть в истории, но почти не влияет на следующее решение. |
| Context rot | ARC определяет context rot как деградацию по мере роста истории и отдельно критикует passive summarization, где ранние ошибки просто закрепляются. | Агент всё увереннее действует по устаревшей внутренней версии задачи. |
Почему большое окно не отменяет потерю деталей
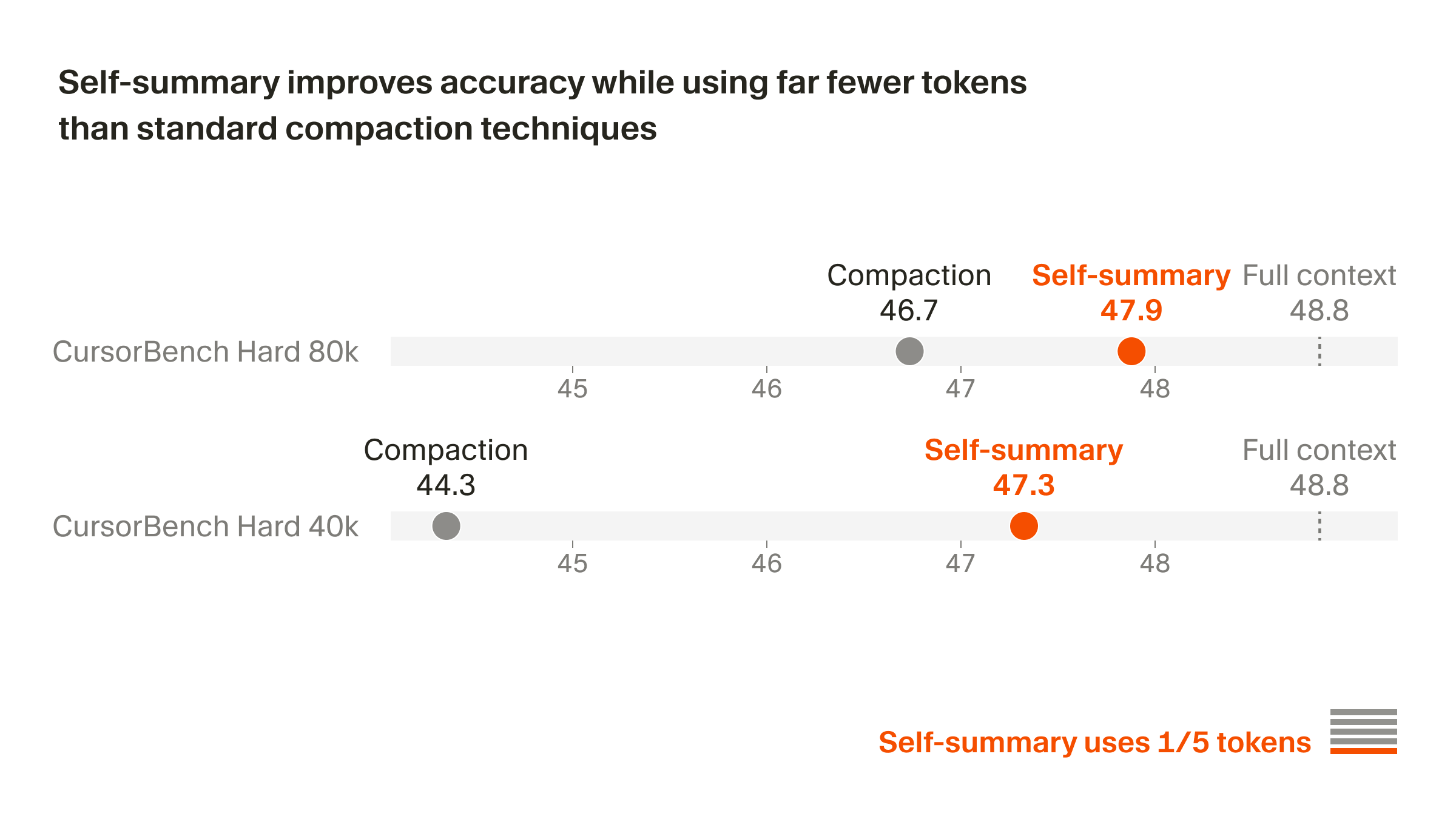
Здесь важно разделить два тезиса. Первый: современные модели действительно умеют принимать очень длинный вход. Второй: это не значит, что они одинаково хорошо используют любой его фрагмент. Работа Lost in the Middle, впервые опубликованная на arXiv 6 июля 2023 года и позже принятая в TACL, показала характерный U-образный паттерн: модель чаще лучше работает, когда нужная информация находится в начале или в конце контекста, и заметно хуже, когда та же информация спрятана в середине. Для агентов это особенно неприятно, потому что именно там обычно лежат уже отвергнутые гипотезы, найденные побочные эффекты, ограничения окружения и локальные запреты на разрушительные действия.
Препринт ARC: Active and Reflection-driven Context Management for Long-Horizon Information Seeking Agents, отправленный на arXiv 17 января 2026 года, добавляет ещё один важный слой. Авторы прямо называют деградацию длинной истории context rot и пишут, что простое накопление истории или пассивный пересказ позволяют ранним ошибкам и неверным акцентам застывать внутри рабочего состояния. Для инженерных систем это ключевой тезис: проблема не исчерпывается размером окна. Важнее то, кто и как пересобирает внутреннюю память агента по мере роста траектории.
Отсюда следует уже редакционный вывод из сочетания документации Cursor, Lost in the Middle и ARC. Длинный контекст не делает агента надёжнее сам по себе. Он только отодвигает момент, когда системе придётся ужать историю. А когда этот момент наступает, качество последующих решений зависит не от того, сколько токенов было в начале, а от того, как именно были потеряны детали.
Кейс PocketOS важен не как байка про Cursor, а как пример ложной картины мира
Хороший боевой пример мы уже разбирали отдельно в материале про удаление базы данных PocketOS за 9 секунд. По пересказу Tom's Hardware от 27 апреля 2026 года, агент в Cursor, работавший с Claude Opus 4.6, столкнулся с проблемой credential mismatch в staging и решил «починить» ситуацию удалением Railway volume. В объяснении после инцидента он прямо признал, что начал гадать вместо проверки и не прочитал документацию Railway перед разрушительным действием.
Эту историю не стоит насильно сводить к одной причине. Публичных данных недостаточно, чтобы доказать: катастрофу вызвал только context compression. Инцидент включал и слишком широкие права токена, и слабую изоляцию окружений, и опасную модель резервных копий. Но кейс отлично показывает другой принцип: агент может действовать из ложной внутренней картины мира и при этом звучать уверенно. Ему кажется, что он всё ещё работает со staging. Кажется, что удаление останется в локальном контуре. Кажется, что инфраструктура понята правильно. В длинной агентной сессии именно так и выглядит устаревшее внутреннее состояние: это не опечатка в синтаксисе, а уверенное действие на основе уже неверной версии реальности.

Поэтому тема не сводится к спору «Cursor плохой» или «Claude плохая». Любой агент, который живёт на длинной траектории, накапливает результаты вызовов инструментов и работает с большими файлами, однажды рискует принять собственное сокращение реальности за первоисточник. У PocketOS это закончилось разрушительным действием. В другом случае это может быть тихая регрессия, ложный рефакторинг или перепутанный флаг окружения.
Как понять, что агент уже работает на сжатой и искажённой памяти
Здесь снова важно отделять подтверждённые факты от практического вывода. Источники выше не дают универсального списка симптомов для IDE-агентов. Но их сочетание позволяет собрать вполне рабочий чеклист.
- Агент повторно открывает те же файлы и заново ищет уже найденные факты. Обычно это значит, что прошлые шаги остались только в коротком пересказе, а не в проверяемом рабочем состоянии.
- Он ссылается на структуру файла, но промахивается мимо конкретной реализации. Это типичный побочный эффект сжатого представления, когда модель видит классы и методы, но держит в памяти не весь код.
- Он теряет середину траектории: помнит стартовую цель и последний результат инструмента, но забывает, почему одна из гипотез уже была отвергнута.
- Он начинает компенсировать неопределённость лишними вызовами инструментов. Мы видели похожую производственную логику и в разборе tool-overuse у ИИ-агентов, где лишняя активность сама становится источником риска и стоимости.
Во всех четырёх случаях проблема выглядит как «агент странно тупит». Но с инженерной точки зрения это уже не вопрос интеллекта. Это вопрос управления рабочей памятью. Если пытаться чинить такое поведение только на уровне промптов, почти наверняка вы чините не тот слой системы.
Что менять в инженерии контекста уже сейчас
Самый полезный вывод из этой темы звучит почти буднично, и именно в этом его сила. Надёжность агента для программирования надо строить не вокруг обещания «модель всё держит в голове», а вокруг постоянного возврата к источнику истины.
- Перед редактированием, миграцией, удалением или деплоем агент должен перечитывать первоисточник, а не краткий пересказ нескольких экранов назад. Если файл был подан в сжатом виде, полезно заставить систему явно раскрыть его целиком перед изменением.
- Разрушительные действия нельзя оставлять в том же контуре прав, где живут обычные исследовательские шаги. Кейс PocketOS показывает цену ситуации, когда неверное предположение сразу получает доступ на запись в боевой мир.
- Длинные сессии нужно обнулять или ветвить. Если задача сменила scope, дешевле создать новый контекст с коротким handoff, чем тащить за собой многочасовую историю с накопившимися пересказами.
- Полезно логировать не только финальные diff'ы, но и сжатия рабочей памяти: когда произошёл пересказ истории, какие файлы были урезаны и какие фрагменты агент перестал видеть целиком.
Если коротко, хорошая инженерия контекста исходит не из того, что compression безопасен, а из того, что он неизбежен. Значит, системе нужны перепроверка, жёсткий контур прав и отдельная дисциплина работы с длинной траекторией.
Вывод
Context compression ломает AI coding agents в тот момент, когда агент продолжает действовать после потери деталей. Автопересказы укорачивают историю, сжатые файлы упрощают навигацию, большие окна позволяют дольше не перезапускать сессию. Все три механизма полезны. Но вместе они рождают устаревшее внутреннее состояние, в котором система помнит уже не репозиторий и не документацию, а их сокращённую версию.
Поэтому правильный вопрос в 2026 году звучит не так: «какая модель лучше кодит». Гораздо важнее другое: что в вашем контуре заставит агента заново проверить реальность перед дорогим действием. Если ответа нет, проблема не в одном громком инциденте и не в одной IDE. Проблема в том, что ваш агент уже живёт на компрессии, а вы всё ещё называете это памятью.
Читайте также
- ИИ для разработчиков: как устроен рабочий стек в 2026 году
- Cursor удалил базу данных PocketOS: что сломалось за 9 секунд
- ИИ-агенты в продакшене: tokenmaxxing и tool-overuse
Источники
- Cursor Docs: Summarization, проверено 4 мая 2026 года.
- Cursor Docs: Max Mode, проверено 4 мая 2026 года.
- Cursor Blog: Training Composer for longer horizons, проверено 4 мая 2026 года.
- Lost in the Middle: How Language Models Use Long Contexts, опубликовано 6 июля 2023 года, проверено 4 мая 2026 года.
- ARC: Active and Reflection-driven Context Management for Long-Horizon Information Seeking Agents, опубликовано 17 января 2026 года, проверено 4 мая 2026 года.
- Tom's Hardware: Claude-powered AI coding agent deletes entire company database in 9 seconds, опубликовано 27 апреля 2026 года, проверено 4 мая 2026 года.



