Стоимость токенов в enterprise AI: почему счёт за LLM растёт
Разбор TechCrunch, FinOps Foundation и arXiv: почему token spend стал управленческой проблемой, где горят токены и какие метрики нужны CTO и FinOps.
Проверено 6 июня 2026 года. Стоимость токенов в enterprise AI — это переменная стоимость инференса и API-вызовов LLM, которую компания должна считать по командам, продуктовым функциям и бизнес-результату, а не только по общему счёту провайдера. Пока пилот живёт в Slack-канале или у пары разработчиков, этот расход кажется мелочью. Когда агентные сценарии попадают в разработку, поддержку, поиск по знаниям и внутренние ассистенты, токены быстро превращаются в новый облачный счёт.
Повод для разговора жёсткий. TechCrunch 5 июня 2026 года описал, как крупные компании начали упираться в AI-расходы: Uber, по данным издания, израсходовал годовой бюджет на AI coding уже к апрелю, Microsoft отзывала у разработчиков лицензии Claude Code, а сотрудник Priceline рассказал о продлении Cursor в 4-5 раз дороже прежнего контракта. Польза LLM в бизнесе никуда не исчезла, но вопрос сменился. После этапа «дайте всем лучшие модели» компании спрашивают, кто сжигает токены, за какой результат и почему счёт растёт быстрее, чем производительность.
Если вы только выбираете сценарии внедрения, начните с соседнего разбора LLM в бизнесе в 2026 году. Здесь фокус уже другой: как жить после того, как LLM перестала быть экспериментом и стала регулярной статьёй расходов.
Почему токены стали управленческой проблемой
У облака есть привычные единицы: виртуальные машины, гигабайты, сетевой трафик, GPU-часы. У enterprise AI видимая единица проще — токен. Но экономически он менее понятен. Один запрос может включать системный промпт, историю диалога, найденные документы, описание инструментов, промежуточные рассуждения, повторные вызовы и финальный ответ. Пользователь видит одну кнопку, а внутри может пройти десятки LLM-вызовов.
FinOps Foundation в материале Token Economics: The Atomic Unit of AI Value описывает token economics как расширение FinOps на AI-слой: токены становятся единицей потребления, которую нужно связывать не только с ценой, но и с ценностью результата. Там же перечислены типовые источники расхода: системные инструкции, контекст и память, выбор модели, длина ответа, повторы и оркестрация.
TechCrunch приводит две показательные цифры из Jellyfish: инженеры с самым активным использованием AI были примерно вдвое продуктивнее коллег, но тратили в 10 раз больше токенов; per-developer consumption, по словам Nicholas Arcolano из Jellyfish, вырос примерно в 18,6 раза за девять месяцев. Такой разрыв и делает token spend управленческой задачей: рост потребления может быть оправдан, но только если компания видит ценность результата.
Главная ловушка в том, что цена за миллион токенов может снижаться, а общий счёт всё равно растёт. Команды добавляют длинный контекст, RAG, агентные шаги, tool calls, проверки качества и автоматические повторы. В итоге экономия на единице не перекрывает рост потребления.
Где сгорают токены
Разумный контроль начинается не с запрета на дорогие модели, а с карты расхода. В enterprise-среде один и тот же счёт Anthropic, OpenAI, Google или OpenRouter может смешивать эксперименты, production-функции, внутренние инструменты и агентные цепочки. Без атрибуции CFO видит сумму, CTO видит недовольные команды, а продукт не видит cost-per-outcome.
| Где сгорают токены | Что контролировать | Какая метрика нужна |
|---|---|---|
| AI-агенты | Число шагов, tool calls, проверки и повторные попытки | Стоимость успешной задачи, а не стоимость одного запроса |
| RAG и поиск по знаниям | Сколько документов попадает в контекст и сколько из них реально полезны | Стоимость ответа с подтверждённым источником |
| Длинный контекст | Историю диалога, вложенные файлы, системные инструкции и память | Входные токены на одну завершённую операцию |
| Retries и eval-петли | Повторы из-за ошибок инструмента, плохого промпта или слабой валидации | Доля токенов, потраченных на неудачные попытки |
| Tool calls | Размер схем инструментов и повторную отправку одних и тех же описаний | Токены на один полезный вызов инструмента |
| Batch jobs | Модель, размер пакета, кэширование, время запуска и допустимую задержку | Стоимость обработки одного документа или записи |
Этот список полезен тем, что переводит разговор из «модель дорогая» в «какой участок процесса сжигает бюджет». Иногда проблема в Opus или GPT-5.1, иногда в том, что агент на каждом шаге заново получает огромный набор инструкций и инструментов.
AI-агенты усиливают расход сильнее обычного чата
Агентные workflow расходуют больше токенов, чем обычный чат, потому что один пользовательский запрос превращается в планирование, чтение контекста, вызовы инструментов, проверку результата и повторные попытки. Это особенно заметно в разработке: агенту часто нужно понять репозиторий, найти файлы, написать код, запустить проверки, прочитать ошибку и исправить её.
Исследование arXiv:2604.22750, поданное 24 апреля 2026 года и обновлённое 29 апреля, анализирует траектории восьми frontier LLM на SWE-bench Verified. Авторы пишут, что agentic coding tasks потребляют примерно в 1000 раз больше токенов, чем code reasoning и code chat; при повторном запуске одной и той же задачи расход может отличаться до 30 раз; рост расхода не гарантирует рост точности. Это исследование не даёт универсальную норму для всех enterprise-сценариев, зато хорошо показывает риск для команд, которые оценивают агента по цене одного пользовательского сообщения.
Для архитектуры AI-агентов это означает простую вещь: счёт надо считать по завершённой задаче, а не по одному API-вызову. Если нужен технический фон по тому, как устроены такие цепочки, см. материал про агентный ИИ, ReAct и tool use.
Рынок отвечает инструментами для AI FinOps
TechCrunch пишет, что вокруг этой боли уже формируется рынок: Pay-i, Paid, Jellyfish, Waydev, Faros AI, Datadog, New Relic и Ramp добавляют инструменты для cost management, token-level observability и мониторинга AI-инфраструктуры. Смысл категории не в красивом дашборде, а в связке трёх данных: кто потратил, на какую модель и какой результат получил.
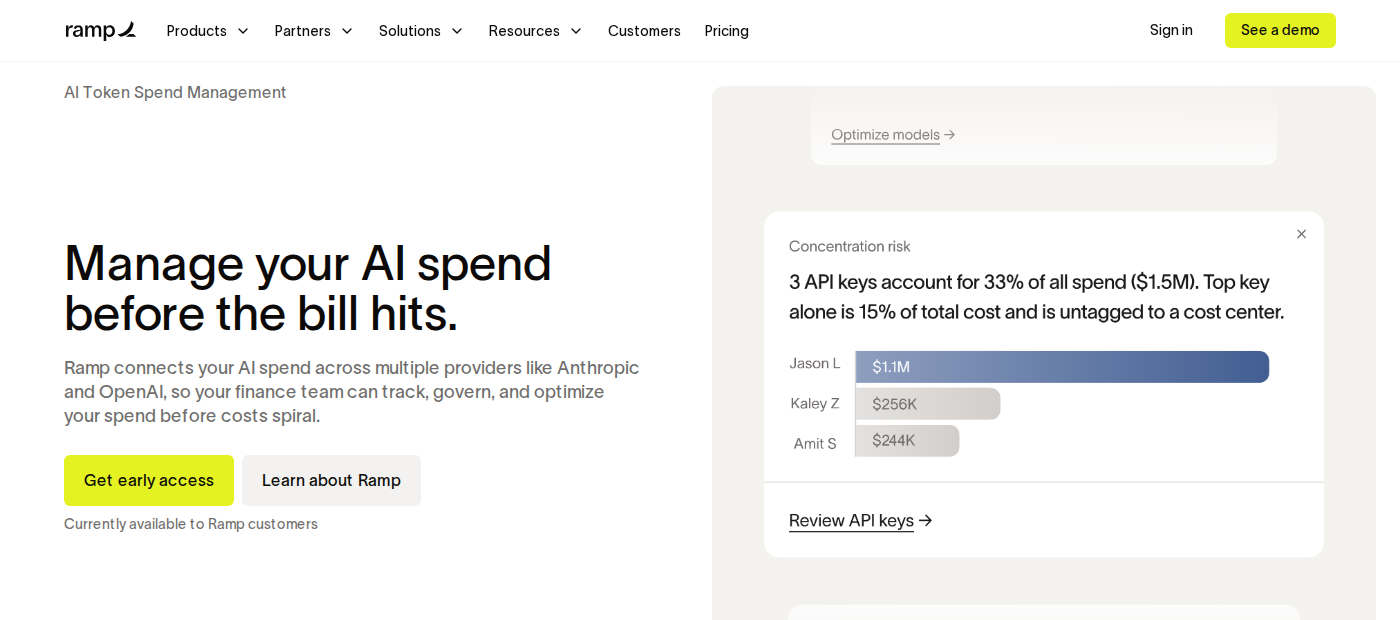
У Ramp отдельная страница AI Token Spend Management описывает продукт как способ видеть AI-расходы по провайдерам вроде Anthropic и OpenAI, отслеживать команды, тренды и аномалии. В справке Ramp также перечислены подключения к Claude Enterprise, OpenAI Platform, ChatGPT Enterprise и GCP/Gemini; синхронизация данных заявлена ежедневная, обычно с лагом T-1.
Linux Foundation 3 июня 2026 года объявила о намерении запустить Tokenomics Foundation. Заявленная цель — открытые стандарты, бенчмарки и практики для экономики AI-инфраструктуры. В пресс-релизе говорится, что фонд будет работать вместе с FinOps Foundation и расширять дисциплину переменных технологических расходов на эпоху token-based AI. Там же приведён прогноз Goldman Sachs: глобальное использование токенов может вырасти в 24 раза между 2026 и 2030 годами, до 120 квадриллионов токенов в месяц.
Что считать вместо общего счёта за LLM
Один общий счёт за LLM полезен только для бухгалтерии. Для управления нужны метрики ниже уровнем.
- Стоимость успешной задачи: сколько токенов ушло на результат, который прошёл проверку и был принят пользователем или системой.
- Стоимость функции: расход по конкретной продуктовой возможности, а не по всей организации.
- Token yield: доля сгенерированных токенов, которые привели к бизнес-действию, а не к черновику, повтору или отклонённому ответу.
- Доля retry-токенов: сколько бюджета уходит на повторы после ошибок, невалидных tool calls и слабой валидации.
- Cost-per-team и cost-per-user: кто потребляет ресурс и есть ли у потребления объяснимый результат.
- Model mix: какие задачи уходят в дорогие reasoning-модели, а какие можно маршрутизировать в более дешёвые модели.
FinOps Foundation в State of FinOps 2026 пишет, что 98% практиков уже управляют AI-расходами, а AI cost management стал самым востребованным навыком для FinOps-команд. Это важный сдвиг: тема вышла за пределы инженерного любопытства и стала частью регулярного управления технологической ценностью.
Практический минимум для CTO и FinOps
Если компания уже платит за LLM и агентные инструменты, базовый контроль можно начать без большой платформенной перестройки.
- Разнести расходы по командам, продуктам и средам: production, staging, эксперименты, evals.
- Ввести лимиты на ключи API, пользователей и классы задач. Лимит должен быть виден до того, как бюджет сгорел.
- Считать стоимость успешного результата. Для поддержки это решённое обращение, для RAG — ответ с подтверждённым источником, для coding agent — принятый pull request или закрытая задача.
- Поставить model routing: простые задачи отправлять в дешёвые модели, тяжёлые — в reasoning/frontier-класс только по необходимости. Соседний материал о выборе языковой модели под задачу помогает разложить этот выбор по классам задач.
- Урезать контекст: не отправлять весь репозиторий, всю историю и все схемы инструментов, если задаче нужен узкий кусок данных.
- Отдельно считать retries, eval runs и batch jobs. Эти строки часто выглядят техническими, но именно они превращают пилот в неожиданный счёт.
Самая опасная управленческая ошибка — мерить только экономию. Дешёвая модель, которая даёт непригодный ответ и запускает три повторные попытки, может быть дороже дорогой модели, которая закрывает задачу с первого раза. Нужна не минимальная цена токена, а минимальная стоимость приемлемого результата.
FAQ
Чем token spend отличается от cloud spend?
Cloud spend обычно привязан к инфраструктурным ресурсам: машинам, дискам, сети, GPU-часам. Token spend привязан к действиям AI-системы: входному контексту, ответам, tool calls, повторам и агентной оркестрации. Он более гранулярный и чаще смешивает продуктовую работу, эксперименты и внутренние инструменты.
Почему AI-агенты дороже обычного чата?
Потому что агент делает больше скрытой работы. Он планирует, читает контекст, вызывает инструменты, проверяет результат и повторяет шаги при ошибке. Пользователь видит одну задачу, а биллинг видит цепочку вызовов.
Что такое AI FinOps простыми словами?
AI FinOps — это управление AI-расходами так, чтобы токены, модели, инфраструктура и бизнес-результат были связаны в одной системе. Команда должна понимать не только сколько заплатила провайдеру, но и какие функции, команды и сценарии дали ценность за эти деньги.
Вывод
Стоимость токенов в enterprise AI стала проблемой не потому, что LLM внезапно перестали быть полезными. Наоборот: расход растёт там, где компании действительно переводят AI из пилотов в рабочие процессы. Но агентные сценарии, длинный контекст, RAG и автоматические повторы делают этот расход нелинейным.
Поэтому новый управленческий слой выглядит так: считать токены по функциям и командам, связывать их с результатом, ставить лимиты, маршрутизировать модели и регулярно сверять счета провайдеров с внутренними метриками. Без этого enterprise AI остаётся красивым пилотом с плохо предсказуемым счётом. С этим контролем у компании появляется шанс масштабировать LLM не по инерции, а по экономике.
Читайте также
- LLM в бизнесе в 2026: 4 сценария с быстрым запуском и как выбрать стек
- Агентный ИИ: архитектуры AI-агентов, ReAct и tool use
- Как выбрать языковую модель под задачу в 2026 году
Источники и дата проверки
Факты, даты, цифры и изображения проверены 6 июня 2026 года. Быстро меняющиеся данные о продуктах, ценах и доступности AI-инструментов могли измениться после этой даты.
- TechCrunch, 5 июня 2026 года — основной новостной повод: enterprise token spend, Uber, Microsoft, Priceline, Jellyfish, Faros, Tokenomics Foundation и рынок AI spend management.
- Linux Foundation, 3 июня 2026 года — объявление о намерении запустить Tokenomics Foundation и данные о прогнозе Goldman Sachs.
- FinOps Foundation: Token Economics — определение token economics, источники расхода и метрики связи токенов с ценностью.
- FinOps Foundation: FinOps for AI и State of FinOps 2026 — контекст по AI cost management как части FinOps-практики.
- Ramp AI Token Spend Management и Ramp Help Center — пример продуктовой категории для атрибуции AI-расходов.
- arXiv:2604.22750 — исследование расхода токенов в агентных задачах программирования.