NVIDIA Nemotron-Labs Diffusion: как диффузия ускоряет LLM
NVIDIA Nemotron-Labs Diffusion — разбор релиза NVIDIA: три режима генерации, цифры ускорения, SGLang и ограничения для LLM inference.

Проверено 27 мая 2026 года. NVIDIA Nemotron-Labs Diffusion — новая линейка языковых моделей NVIDIA, которая пытается ускорить генерацию не за счёт ещё одного кэша или более хитрой квантовки, а через другой режим декодирования. Обычные autoregressive LLM выдают текст слева направо: один токен, один полный проход модели, потом следующий токен. Nemotron-Labs Diffusion добавляет режим, где модель генерирует блоки токенов параллельно и уточняет их за несколько шагов.
Главная интрига не в слове diffusion само по себе. NVIDIA сделала один checkpoint с тремя режимами: autoregressive, diffusion и self-speculation. Поэтому модель можно использовать как обычную LLM для совместимости, как диффузионную модель для параллельной генерации или как self-speculation схему, где diffusion-часть набрасывает кандидаты, а autoregressive-часть проверяет их внутри той же модели.
Что выпустила NVIDIA
NVIDIA Research опубликовала страницу работы 19 мая 2026 года, а 23 мая NVIDIA подробно описала релиз в блоге Hugging Face. В линейке есть текстовые модели 3B, 8B и 14B, base- и instruct-варианты, а также 8B vision-language модель. Текстовые модели опубликованы под NVIDIA Nemotron Open Model License; по странице лицензии NVIDIA такие работы можно использовать коммерчески, но это не Apache/MIT, поэтому юридические ограничения всё равно надо читать отдельно.
По данным NVIDIA, обучение строилось вокруг joint AR-diffusion objective: модель сохраняет привычное левостороннее языковое поведение autoregressive LLM, но получает diffusion-режим с block-wise attention. В блоге указаны два больших этапа данных: 1,3 трлн токенов pretraining из NVIDIA Nemotron Pretraining datasets и 45 млрд токенов supervised fine-tuning из Nemotron Post-training datasets.
| Параметр | Что заявлено | Почему это важно |
|---|---|---|
| Размеры | 3B, 8B и 14B; отдельно 8B VLM | Линейка закрывает не только лабораторный 8B-демо, но и несколько весовых классов |
| Режимы | AR, diffusion, self-speculation | Один checkpoint можно запускать разными способами без смены семейства моделей |
| Лицензия | NVIDIA Nemotron Open Model License для текстовых моделей | Коммерческое использование возможно по условиям NVIDIA, это не стандартная open-source лицензия |
| Инференс | Transformers сейчас; SGLang поддержка идёт через upstream PR | Production-стек ещё надо проверять, особенно если нужен не демо-запуск, а сервис |
Эта работа ложится в тот же практический кластер, что и другие способы ускорить декодирование LLM. Раньше мы разбирали, как ускорение декодирования LLM можно получить минимальным изменением в вычислениях, и отдельно смотрели ускорение инференса на H20 через FlashKDA. Nemotron-Labs Diffusion интересен тем, что меняет не только реализацию, но и сам способ получать следующие токены.
Три режима в одной модели
Autoregressive mode нужен как точка совместимости: модель ведёт себя как обычная LLM и генерирует текст слева направо. Diffusion mode работает иначе: модель заполняет блок токенов и постепенно уточняет его. В статье NVIDIA для SGLang описан пример с 32-токенным блоком и порогом уверенности, который решает, какие токены уже можно зафиксировать.
Self-speculation mode объединяет оба подхода. Diffusion-часть быстро предлагает блок кандидатов, autoregressive-часть проверяет, какой префикс можно принять, и общий KV cache не надо строить заново для отдельной draft-модели. Это близко по идее к speculative decoding, но без второй модели-драфтера: черновик и проверка живут в одном checkpoint.
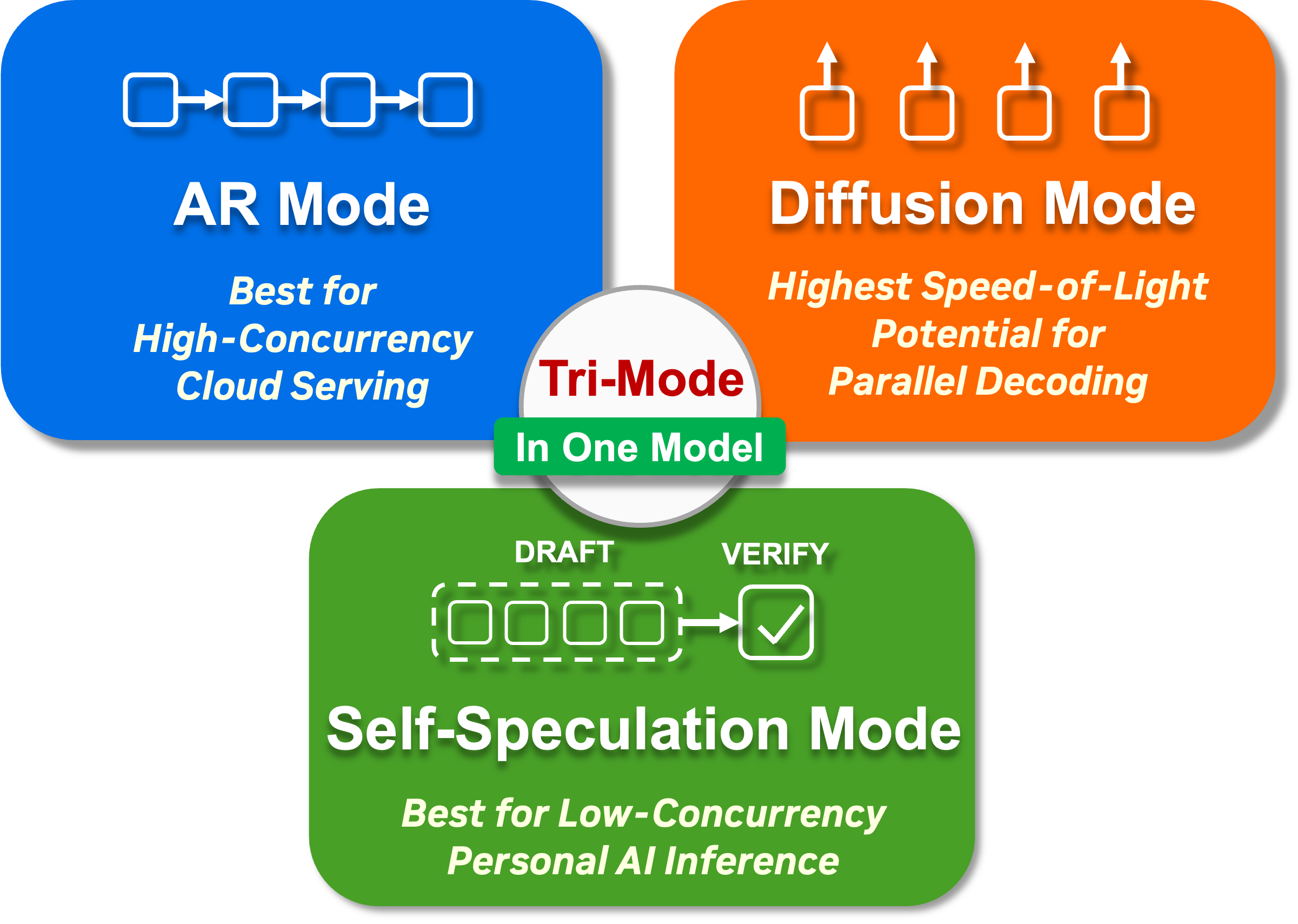
Для разработчика это удобная идея, но не бесплатная магия. В low-batch или single-user сценариях autoregressive декодирование часто упирается в память: веса модели нужно читать снова и снова ради каждого нового токена. Diffusion и self-speculation пытаются перекинуть часть работы в вычисления, где современные GPU чувствуют себя лучше. В высоконагруженном batch-serving выигрыш может быть другим, потому что классические AR-серверы уже неплохо насыщают GPU большим числом одновременных запросов.
Где взялись цифры 2,6x, 5,9x и 4x
С цифрами здесь легко переборщить, поэтому их стоит держать привязанными к источнику и тесту. В блоге Hugging Face NVIDIA пишет, что Nemotron-Labs Diffusion 8B показывает на 1,2 процентного пункта выше average accuracy по сравнению с Qwen3 8B в их наборе задач. По tokens per forward diffusion-режим даёт 2,6x относительно AR-моделей, linear self-speculation — 6x, quadratic self-speculation — 6,4x при сопоставимой точности.
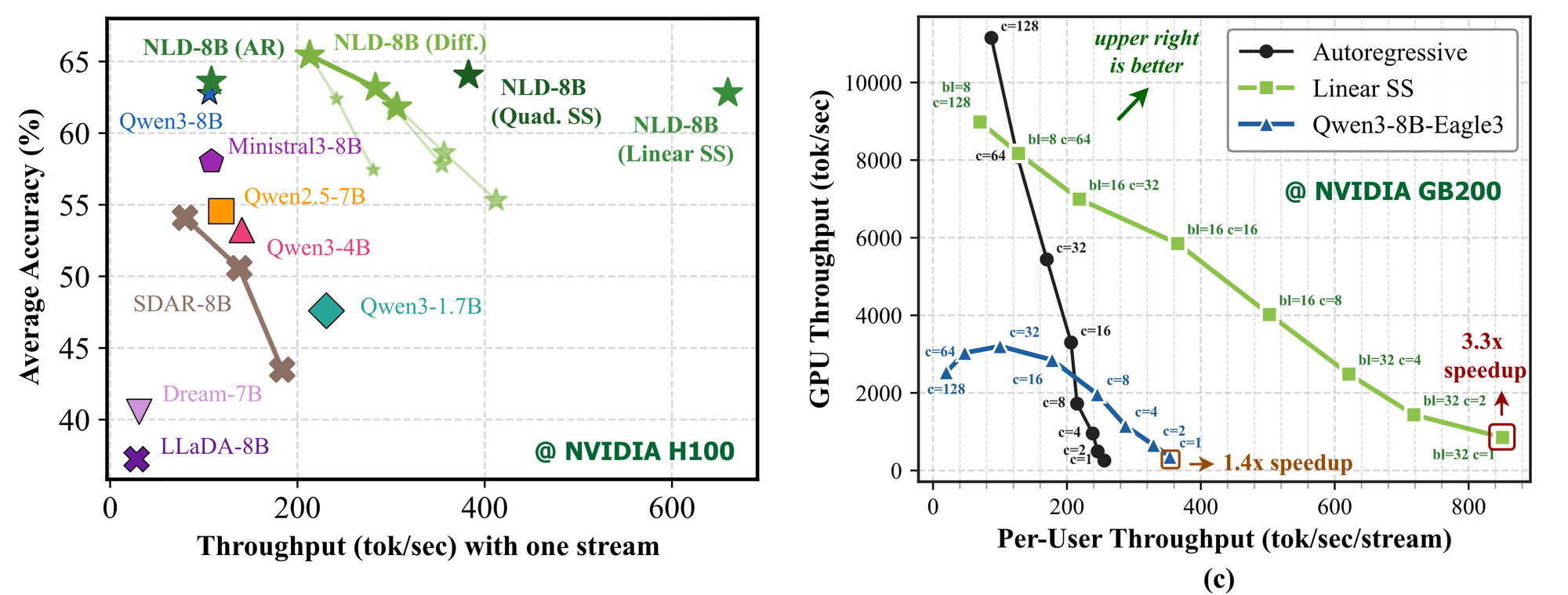
Страница NVIDIA Research формулирует другой срез: Nemotron-Labs-Diffusion-8B декодирует в 5,9x больше tokens per forward, чем Qwen3-8B, при лучшей точности, а на SPEED-Bench через SGLang на GB200 это переводится примерно в 4x throughput. Модельная карточка 8B даёт ещё более прикладные числа: на DGX Spark при concurrency 1 — 112 tok/sec против 41,8 tok/sec у AR; на GB200 — 850 tok/sec против 253 tok/sec у AR и 360 tok/sec у Eagle3, а с кастомными CUDA kernels — 1015 tok/sec.
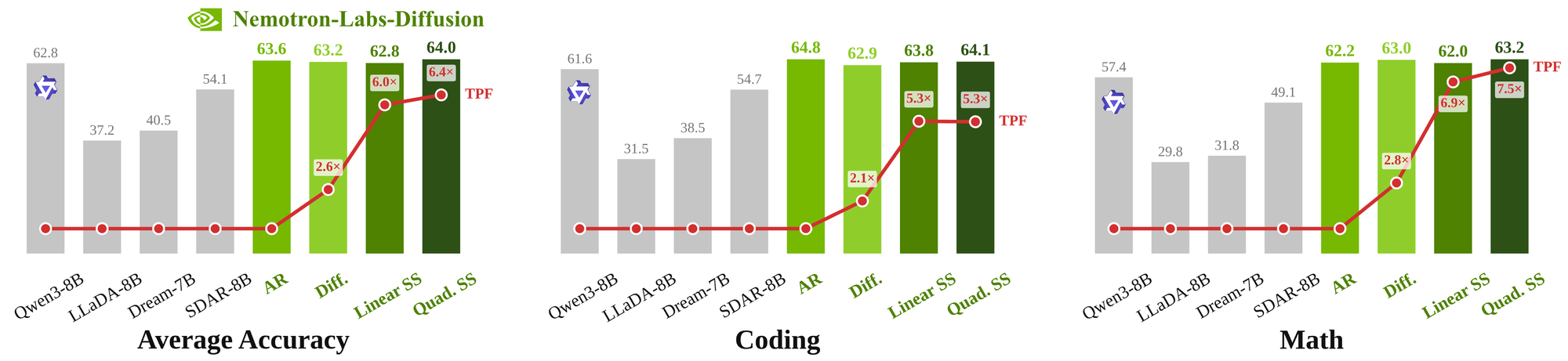
Эти числа не означают, что любая LLM внезапно станет в четыре или шесть раз быстрее. Они относятся к конкретной модели, режиму, benchmark, железу, настройкам SGLang и типу нагрузки. Корректный вывод осторожнее: NVIDIA показала, что diffusion-декодирование может снять часть ограничений token-by-token генерации, особенно там, где latency и small batch важнее максимальной плотности большого облачного batch.
Почему SGLang важен
Для исследовательского релиза можно ограничиться Transformers-кодом из карточки модели. Для продакшна этого мало: нужны scheduler, KV pool, CUDA graph, батчинг, мониторинг задержек и нормальная интеграция с OpenAI-compatible API. Поэтому SGLang в этой истории не второстепенная деталь, а путь от «модель запустилась» к «модель можно обслуживать».
По состоянию на 27 мая 2026 года pull request sgl-project/sglang#25803 открыт. В нём добавляются DiffEncoderModel, NemotronLabsDiffusionModel, FastDiffuser, LinearSpec, scheduler- и CUDA graph-изменения, а также target compatibility для публичной модели nvidia/Nemotron-Labs-Diffusion-8B. Это хороший сигнал зрелости, но не повод считать поддержку уже полностью приземлённой в mainline production stack.
Если вы уже разворачиваете self-hosted модели, полезно сравнить эту историю с обычным LLM-сервером на vLLM. В vLLM-подходе основной выигрыш часто лежит в батчинге и KV-cache management. У Nemotron-Labs Diffusion вопрос другой: можно ли за один forward pass получить больше полезных токенов и не потерять качество.
Что это меняет для LLM inference
До сих пор основная industrial-логика LLM-инференса была вокруг autoregressive моделей: ускоряем attention, оптимизируем KV cache, добавляем speculative decoding, сжимаем веса, подбираем batch size. Nemotron-Labs Diffusion добавляет более радикальный вариант: модель сама умеет работать не только как left-to-right генератор.
Самые понятные сценарии — персональные ассистенты, агентные инструменты, редакторы кода и локальные inference-сервисы, где пользователь ждёт один ответ, а не обслуживается в большом батче. Там токены за один forward pass и latency на первом пользователе могут быть важнее средней стоимости миллиона токенов в крупном дата-центре.
Есть и ограничения. Диффузионное декодирование сложнее объяснять, сложнее отлаживать и сложнее переносить в уже настроенные serving-пайплайны. Для temperature 0 NVIDIA отдельно подчёркивает lossless-поведение self-speculation относительно AR в описанном SGLang-сценарии, но для sampling, длинных агентных цепочек и разных доменов нужны независимые тесты. Пока это сильный исследовательский и инженерный сигнал, а не готовый аргумент «заменяем все AR-модели».
Что проверять перед внедрением
Если вы хотите попробовать NVIDIA Nemotron-Labs Diffusion в своём стеке, начните не с обещанной кратности ускорения, а с узкого теста. Возьмите один сценарий с реальной нагрузкой: автодополнение кода, генерация коротких ответов, агентные tool calls или редактирование текста. Запустите AR baseline, diffusion mode и self-speculation на одинаковом железе, с одинаковыми промптами и лимитами.
Сравнивайте четыре вещи: latency p50/p95, tokens/sec, долю ошибок в ответах и стоимость обслуживания одного запроса. Отдельно проверьте, как модель ведёт себя на русском языке и в доменных терминах, потому что vendor benchmark обычно не отвечает на вопрос, будет ли модель стабильно писать ваш формат отчёта или код на вашем фреймворке.
Релиз NVIDIA важен не потому, что завтра «убьёт autoregressive LLM». Он показывает, что ускорение инференса LLM снова стало архитектурной темой, а не только задачей runtime-оптимизации. Если SGLang-интеграция дойдёт до зрелого состояния и независимые тесты подтвердят числа на разных workload, diffusion language models могут стать реальным вариантом для low-latency inference.
Источники и дата проверки
Факты проверены 27 мая 2026 года по блогу Hugging Face / NVIDIA, странице NVIDIA Research, модельной карточке Nemotron-Labs-Diffusion-8B, коллекции моделей на Hugging Face, SGLang PR #25803, рецептам Megatron-Bridge и NVIDIA Nemotron Open Model License.



