FlashKDA: Moonshot открыла ядра Kimi Delta Attention для H20
Moonshot выложила FlashKDA под MIT и показала ускорение 1,85-2,31x на H20. Разбираем, почему это новость про ядра инференса, а не про очередную модель.
Проверено 1 мая 2026 года. Moonshot выложила FlashKDA под лицензией MIT и показала, что её CUTLASS-ядра для Kimi Delta Attention дают на NVIDIA H20 ускорение примерно от 1,85x до 2,31x против fla_chunk_kda из flash-linear-attention. На бумаге это выглядит как узкая инженерная новость. На деле сигнал сильнее: гонка open-source ИИ всё чаще уходит ниже уровня весов моделей, к ядрам инференса и оптимизациям слоя исполнения.
Если коротко, Moonshot открыла не новую модель Kimi и не очередной чат-интерфейс. Компания открыла слой, который помогает быстрее крутить уже существующую attention-архитектуру. Для разработчиков это важнее пресс-релизной риторики: такие релизы проще встраивать в рабочий стек, чем абстрактные обещания про «прорывной интеллект».
Что именно открыла Moonshot
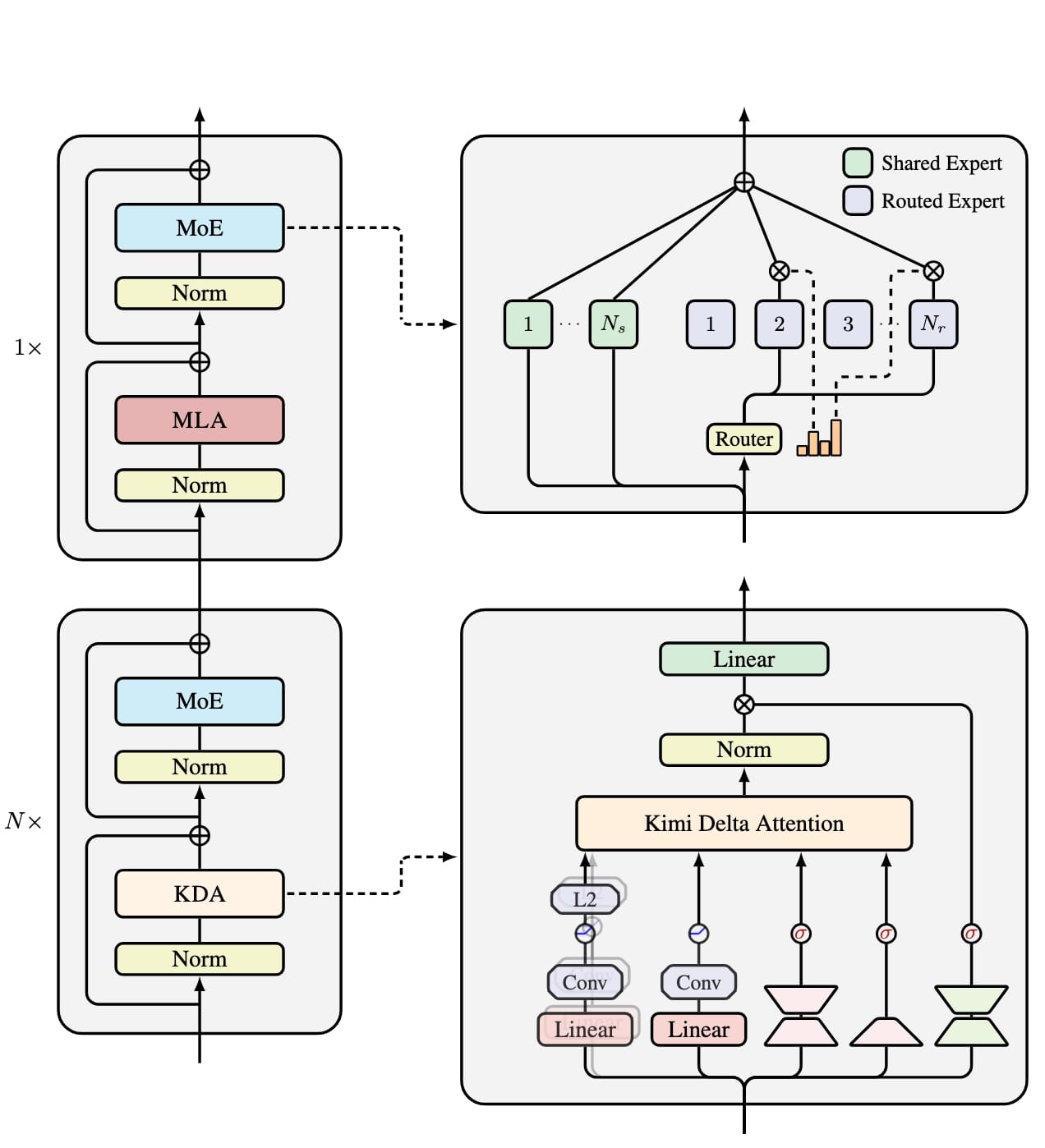
В официальном репозитории MoonshotAI/FlashKDA проект описан как Flash Kimi Delta Attention и как высокопроизводительные KDA-ядра, построенные на CUTLASS. Это сразу ставит рамку: речь не о новой модели, а о низкоуровневой реализации attention-механизма, который Moonshot использует в семействе Kimi Linear.
По состоянию на 1 мая 2026 года в README у проекта зафиксированы жёсткие требования: SM90+, CUDA 12.9+ и PyTorch 2.4+. После установки FlashKDA автоматически подхватывается из flash-linear-attention как бэкенд для chunk_kda. Если нужно вернуться на старый путь, Moonshot прямо указывает переменную FLA_FLASH_KDA=0. Это хорошая инженерная деталь: проект сразу сделан не как отдельное демо, а как встраиваемый бэкенд.
Есть и ещё один практический маркер зрелости. Pull request #852 в flash-linear-attention уже влит, то есть FlashKDA не висит в воздухе как исследовательский код без точки входа. Для разработчика это означает понятный маршрут внедрения: обновить flash-linear-attention, установить FlashKDA и проверить, попадает ли ваш вызов chunk_kda в новый бэкенд.
На фоне новостей про DeepSeek V4 Pro и Flash это выглядит как другой тип открытости. Там в центре релиза стояли веса и модельный ряд. Здесь в центр вынесен кусок стека инференса, который влияет на скорость работы уже выбранной архитектуры.
Что показывают H20-бенчмарки
Moonshot вынесла отдельный файл BENCHMARK_H20.md и зафиксировала в нём дату генерации: 22 апреля 2026 года. Там же указаны настройки прогона: warmup=30, iters=200, repeats=5. Это важно, потому что без таких деталей любые красивые цифры превращаются в маркетинг.
| Конфигурация | Сценарий | Ускорение vs chunk_kda |
Ускорение vs gdn |
|---|---|---|---|
T=8192, H=96, D=128 |
Fixed | 1,85x | 1,22x |
T=8192, H=96, D=128 |
Varlen, seq_lens=[1300, 547, 2048, 963, 271, 3063] | 2,06x | 1,30x |
T=8192, H=96, D=128 |
Varlen, 1024 x 8 |
2,29x | 1,43x |
T=8192, H=64, D=128 |
Fixed | 1,95x | 1,24x |
T=8192, H=64, D=128 |
Varlen, seq_lens=[1300, 547, 2048, 963, 271, 3063] | 1,91x | 1,17x |
T=8192, H=64, D=128 |
Varlen, 1024 x 8 |
2,31x | 1,40x |
Самая интересная часть здесь не только в максимуме 2,31x. Репозиторий отдельно показывает сценарии с пакетами переменной длины. Это уже похоже на попытку говорить на языке реального инференса, а не только на языке ровных синтетических прогонов. Если коротко, Moonshot демонстрирует, что выигрыш держится не в одном красивом фиксированном кейсе, а и в более неровных последовательностях.
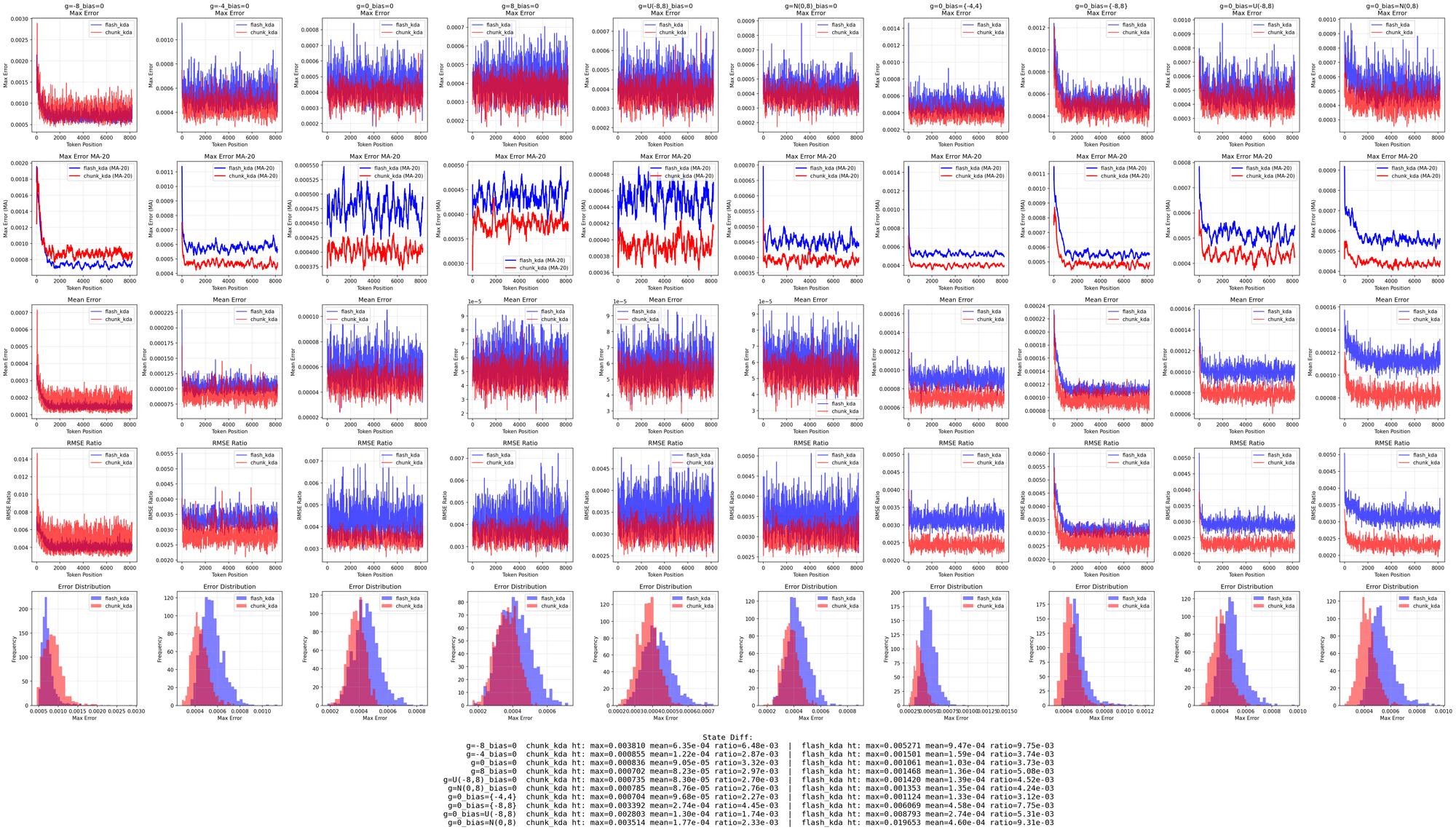
fla_chunk_kda на разных входных случаях. Источник: MoonshotAI/FlashKDA.Почему это новость про инфраструктуру, а не про очередную модель
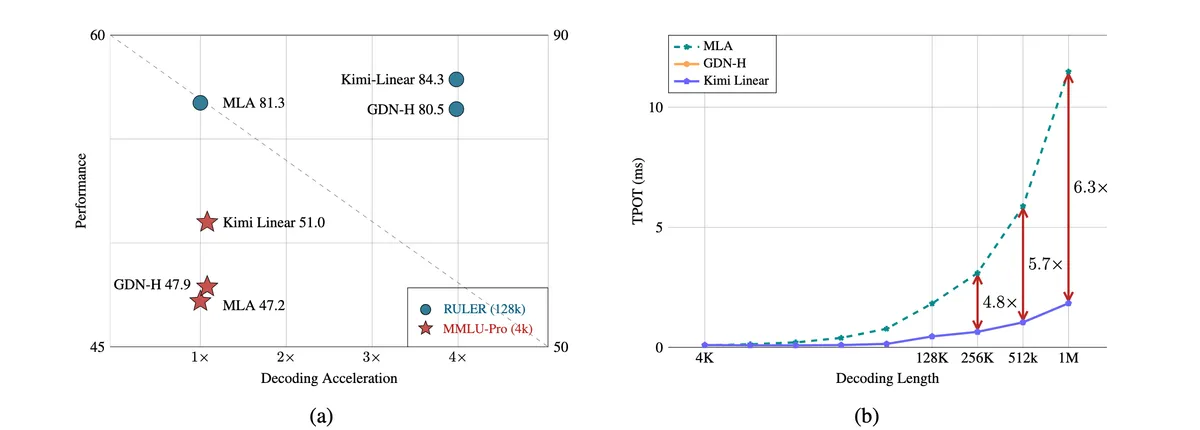
Чтобы понять смысл релиза, полезно вернуться к репозиторию Kimi Linear и исходной статье на arXiv. Там Moonshot описывает Kimi Delta Attention как refinement of Gated DeltaNet и связывает её с гибридной attention-архитектурой, где KDA сочетается с глобальной MLA. В README проекта компания утверждает, что такая схема даёт до 75% экономии по KV cache и до 6,3x faster TPOT на контексте до 1M токенов.
Именно здесь FlashKDA становится интересной не только фанатам Moonshot. Если лаборатория открывает слой вычислительных ядер для своей attention-архитектуры, она делает ставку на воспроизводимость и внедрение. Это уже не жанр «смотрите, у нас есть paper». Это жанр «вот код, вот ограничения, вот бенчмарк, вот путь интеграции». Разница огромная.
Поэтому новость логично читать рядом с нашим материалом про точечное ускорение декодирования LLM без потери качества. Рынок всё чаще выигрывает не одной большой модельной ставкой, а цепочкой более приземлённых оптимизаций: квантование, память, пакетирование, вычислительные ядра и маршрутизация нагрузки. FlashKDA укладывается ровно в этот слой.
Где ограничения прямо сейчас
Перехваливать FlashKDA не стоит. В официальном README ограничения перечислены довольно прямо. Репозиторий требует SM90+, то есть это не история про универсальное ускорение на любом парке GPU. Кроме того, текущее API ядра работает с условием K = V = 128, а бенчмарк, который Moonshot показывает публично, относится к сценарию прямого прохода на Hopper/H20.
Есть и ещё одна деталь из deep-dive отчёта. В версии v1 Moonshot сознательно выбрала CHUNK = 16, а не 64, как в Flash Linear Attention. В документе компания объясняет это проще, чем обычно пишут в research-постах: так легче уложиться в bf16 по числовому диапазону, дешевле инвертировать матрицу 16 x 16 и проще держать реализацию переносимой без слишком специфичных аппаратных зависимостей. Плюс разделение вычисления на два отдельных ядра, по словам Moonshot, дало минимум 15% end-to-end speedup против более раннего single-kernel prototype.
Для читателя это означает простую вещь. FlashKDA не «ускоряет все LLM» и не отменяет существующие компромиссы. Она ускоряет конкретный attention-путь в конкретном стеке при конкретных требованиях. Но именно так и выглядят полезные инфраструктурные релизы: не магия, а хорошо очерченная зона выигрыша.
Что это меняет для разработчиков
Если ваша команда уже смотрит в сторону Hopper/H20-класса GPU и крутит модели через flash-linear-attention, FlashKDA даёт понятный эксперимент: можно проверить, сколько скорости вы выигрываете в KDA-сценарии без полного переписывания стека инференса. Это редкий случай, когда новость про низкоуровневые ядра превращается в действие, которое разработчик действительно может повторить.
Есть и более широкий рыночный вывод. Китайские лаборатории всё чаще публикуют не только веса, но и инфраструктурные куски вокруг них. В этом смысле FlashKDA хорошо рифмуется с нашим разбором китайского AI-стека вокруг DeepSeek и Huawei Ascend. Конкуренция идёт уже не только за «лучшую модель», но и за то, кто быстрее соберёт вокруг неё рабочий, воспроизводимый и относительно открытый контур исполнения.
Дополнительные материалы из исследовательской подборки про OAuth для MCP-серверов и agentic UI здесь полезны только как фон. Они показывают ту же общую тенденцию: прикладной ИИ взрослеет через инфраструктуру. Но главный герой этой истории всё равно не gateway и не интерфейс, а оптимизация на уровне вычислительных ядер, которую можно потрогать руками уже сейчас.
Итог
FlashKDA важна не потому, что Moonshot снова напомнила о бренде Kimi. Она важна потому, что компания открыла инженерный слой с понятными ограничениями, интеграцией в существующий стек и измеримыми H20-бенчмарками. В 2026 году это всё чаще и есть настоящая новость: не громче всех назвать модель, а быстрее остальных выложить полезный кусок инфраструктуры.
Если этот тренд сохранится, спор про open-source ИИ будет всё меньше крутиться вокруг лозунгов и всё больше вокруг конкретных вещей: расход памяти, TPOT, пакетирование, вычислительные ядра и цена внедрения. FlashKDA как раз из этой категории.
Источники и дата проверки
Факты, ограничения, бенчмарк-числа, даты и детали интеграции в этом материале проверены 1 мая 2026 года по официальным источникам Moonshot: репозиторию FlashKDA, файлу BENCHMARK_H20.md, deep-dive отчёту FlashKDA v1: A Deep Dive, pull request #852 в flash-linear-attention, статье Kimi Linear: An Expressive, Efficient Attention Architecture и репозиторию MoonshotAI/Kimi-Linear. Быстро меняющиеся данные о производительности и поддерживаемых конфигурациях могут измениться после этой даты.



