RMA: как AI-агенты подошли к исследовательской математике
RMA заявляет 8 успешных решений из 10 на First Proof. Что это говорит об AI-агентах для математики и почему результат пока нельзя читать как замену экспертам.
Проверено 27 мая 2026 года. RMA AI-агенты для исследовательской математики — свежая работа с arXiv, где авторы из Georgia Tech проверяют агентную систему для длинных доказательств, а не решатель школьных задач. Препринт RMA: an Agentic System for Research-Level Mathematical Problems был отправлен 20 мая 2026 года. Главная заявка звучит жёстко: на First Proof система получила 8 успешных решений из 10 по консервативной экспертной оценке.
Вывод тут аккуратнее, чем звучит в заголовках про «ИИ закрыл математику». RMA хорошо показывает, сколько инженерии нужно, чтобы языковая модель перестала просто писать убедительный текст и начала выдерживать проверку математиков.
| Факт | Что проверено | Источник |
|---|---|---|
| Публикация | arXiv:2605.22875, submitted 20 May 2026; авторы Zelin Zhao, Bo Yuan, Jaemoo Choi, Yongxin Chen. | arXiv RMA |
| Бенчмарк | First Proof состоит из 10 исследовательских математических задач, предложенных экспертами. | arXiv First Proof |
| Результат RMA | В таблице RMA: 8 корректных, 1 неопределённая и 1 неверная задача из 10. | arXiv RMA |
| Ограничение | Авторы пишут, что решения и реализация будут открыты после принятия статьи; на 27 мая 2026 года код не был публичным артефактом работы. | arXiv RMA |
Что такое RMA
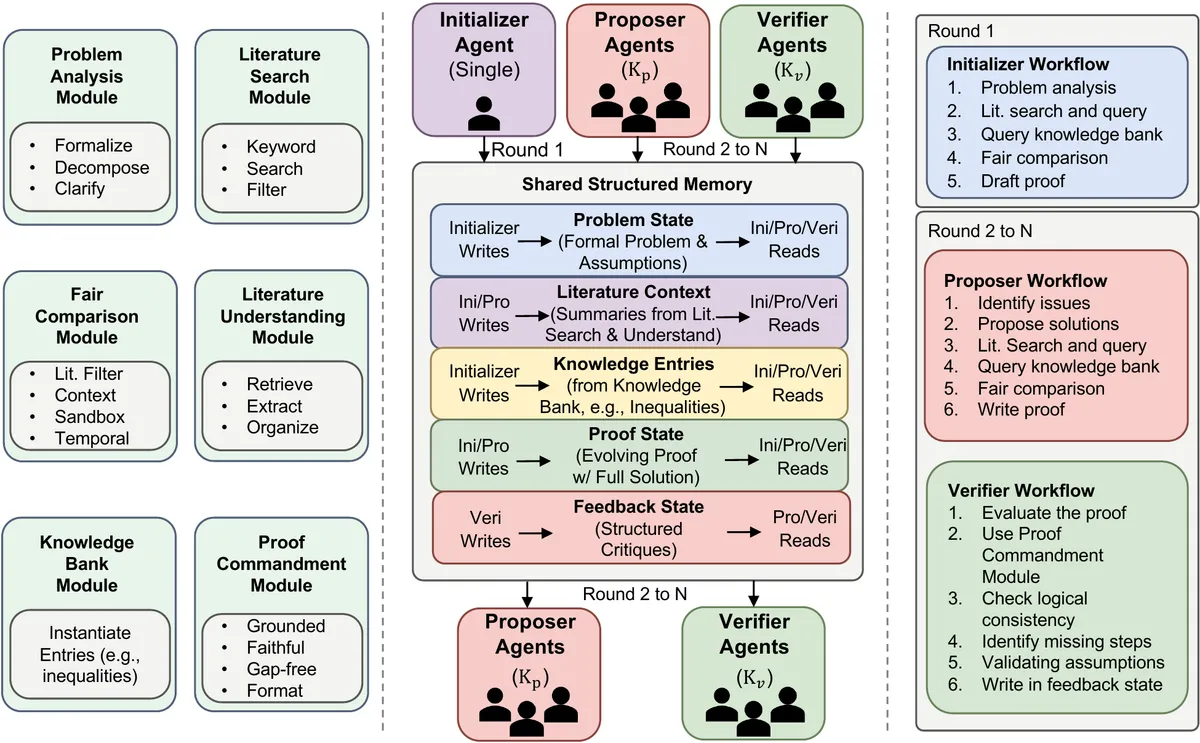
RMA расшифровывается как Research Math Agents. В статье это агентная надстройка над моделью, которая раскладывает доказательство на несколько рабочих циклов: анализ задачи, поиск литературы, отбор релевантных результатов, банк математических заготовок и проверку доказательства.
Архитектура держится на трёх ролях. Initializer готовит первичный черновик и память задачи. Proposer-агенты ищут дыры, предлагают новые ходы и переписывают доказательство. Verifier-агенты проверяют шаги по набору правил: обоснованность, верность исходной постановке, отсутствие пропусков, конструктивность там, где она нужна, и корректный LaTeX-формат.

Ключевая деталь — общая структурированная память. Система хранит состояние задачи, выдержки из литературы, записи knowledge bank, текущий proof state и отзывы verifier-агентов раздельно. Это делает процесс более проверяемым, чем один длинный ответ модели: можно смотреть, какой шаг откуда взялся и что именно критиковал verifier.
В этом RMA ближе к практической архитектуре агентного ИИ с tool use и памятью, чем к привычному «чат-боту для математики». Если упрощать, авторы пытаются собрать рабочее место для доказательства: поиск, заметки, черновики, ревью и контроль за источниками в одном цикле.
Почему First Proof сложнее олимпиадной математики
Ценность First Proof не в количестве задач. Их всего десять, и это как раз проблема для статистики. Важен тип задач: они взяты из реальной исследовательской работы математиков, а ответы должны быть доказательствами, которые сейчас проверяются людьми, а не точным числом в конце строки.
В препринте First Proof авторы прямо разводят этот формат с олимпиадными и учебными бенчмарками: такие задачи требуют длинного аргумента, понимания специализированных определений и проверки неочевидных промежуточных лемм. OpenAI в своём разборе First Proof submissions тоже подчёркивала, что корректность здесь трудно установить без экспертного ревью.
Эта разница полезна для русскоязычного читателя Toolarium. В истории про ChatGPT и 60-летнюю задачу Эрдеша модель была частью человеческого исследовательского процесса. RMA проверяет другой сценарий: может ли агентная система сама пройти значимую часть пути от постановки до proof draft, который выдержит независимое чтение.
Что означает результат 8 из 10
В таблице RMA авторы сравнивают систему с GPT-5.2R, Aletheia, Agentic Researcher, Deep Research-подобными системами и базовой работой Claude Opus 4.6 в CLI-среде. По их консервативной агрегации RMA закрывает 8 задач из 10. GPT-5.2R в этой же таблице получает 3 из 10, AgenticR — 3 из 10, Aletheia — 5 корректных, 1 неопределённую и 4 без успешного вывода.
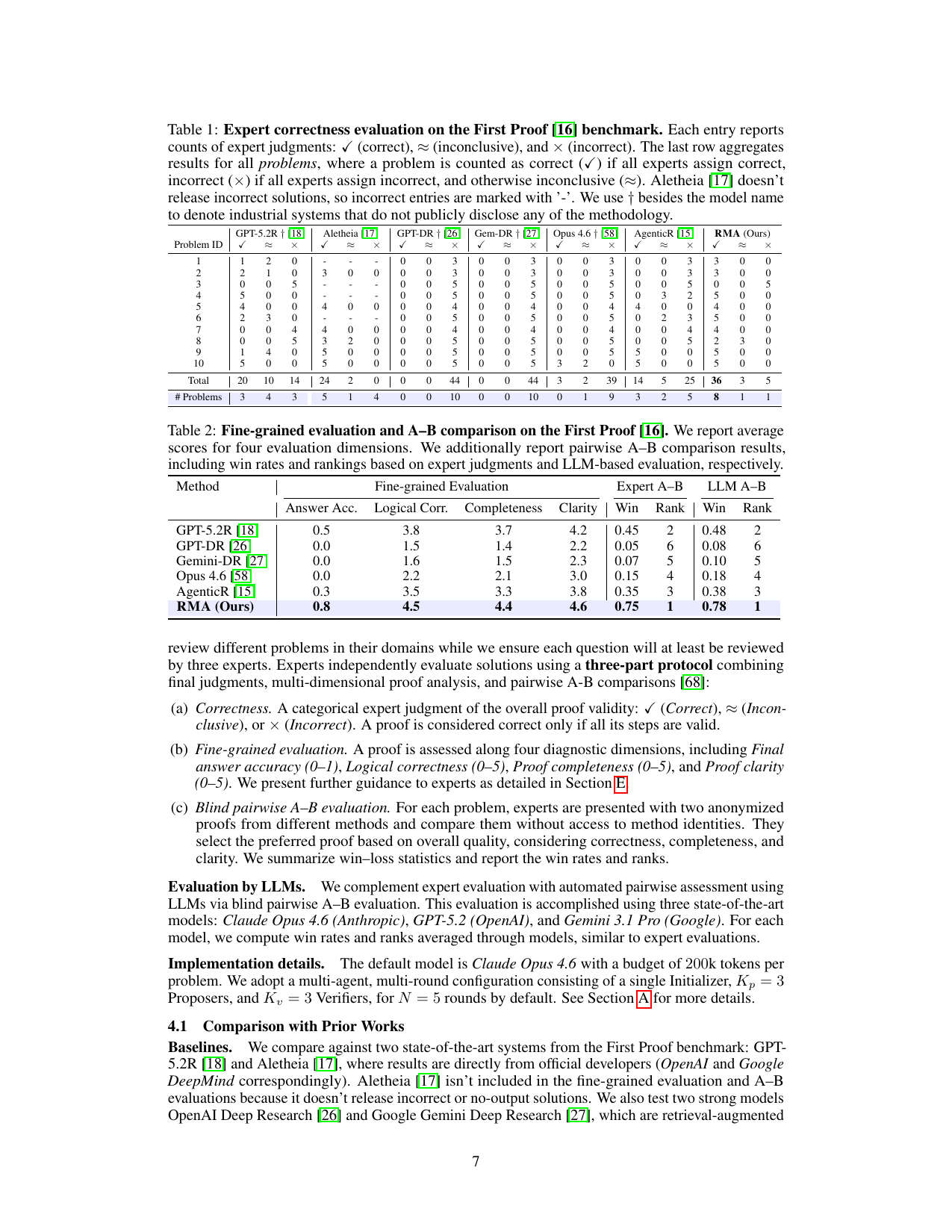
Здесь есть важная оговорка. У Aletheia есть собственный препринт Aletheia tackles FirstProof autonomously, где заявлено 6 решённых задач из 10 по majority expert assessments, а по Problem 8 эксперты не были единогласны. RMA считает строже: задача попадает в «correct», только если все эксперты отметили решение как корректное. Поэтому цифры 6/10 и 5/10 не обязательно противоречат друг другу, они отвечают на разные правила подсчёта.
За цифрой стоит набор инженерных ограничений. Для внутренних запусков авторы задают лимит 200 тысяч токенов на задачу и 6 часов реального времени на один запуск решения, используют одного initializer, трёх proposer-агентов, трёх verifier-агентов и 5 раундов рассуждения. Источники с известными решениями First Proof блокируются, а граница обучающих данных базовой модели указана как август 2025 года, до публикации First Proof в феврале 2026-го.
Где у работы слабые места
Первое слабое место — размер. Десять задач не дают устойчивой статистики, и сами авторы пишут, что такой benchmark дорог именно потому, что каждое решение читают математики. Поэтому 8/10 стоит воспринимать как сильный сигнал на маленькой выборке, а не как универсальную оценку «ИИ решает 80% исследовательской математики».
Второе — экспертная проверка. Она лучше автоматического совпадения ответа, но всё равно остаётся человеческим суждением по длинным неформальным доказательствам. RMA смягчает это blind evaluation, несколькими экспертами на задачу и A/B-сравнениями. Машинной гарантии уровня Lean здесь нет.
Третье — сравнение с внешними системами. Для GPT-5.2R и Aletheia авторы RMA используют публично выпущенные решения, потому что исходные промпты, tool access, sampling и бюджеты этих запусков раскрыты не полностью. Это нормальная честная оговорка, но она ограничивает силу прямого рейтинга.
Наконец, код RMA и полные решения обещаны после принятия статьи. Пока это препринт с архитектурой, таблицами и методологией, а не воспроизводимый инструмент, который можно скачать, прогнать на своей задаче и сравнить с другой системой.
Почему это важно для AI-агентов в науке
RMA попадает в более широкий сдвиг: AI-агенты начинают работать как исследовательские процессы, а не просто как интерфейс к модели. В OpenArx и AI-native инфраструктуре для науки похожая логика видна на уровне данных, поиска и R&D-операций. В Qiushi Discovery Engine — на уровне цикла от гипотезы к физическому эксперименту. RMA показывает математическую версию того же движения: управляемый цикл «черновик — критика — исправление».
Для исследовательской математики это особенно чувствительная область. Ошибка в одной лемме может разрушить весь результат, а убедительный стиль письма часто мешает заметить дыру. Поэтому RMA сейчас лучше читать как помощника: он быстро строит варианты доказательства, собирает литературу, явно показывает предположения и оставляет человеку финальное право сказать, доказано или нет.
Что смотреть дальше: откроют ли авторы код и логи, как RMA пройдёт повторную проверку на следующей партии First Proof, появятся ли доверительные интервалы на большем наборе задач и сможет ли система связаться с формальными проверщиками. Пока RMA остаётся сильным исследовательским сигналом. После воспроизводимого релиза она может стать практическим шаблоном для научных AI-агентов.
Источники
- RMA: an Agentic System for Research-Level Mathematical Problems, arXiv:2605.22875.
- First Proof, arXiv:2602.05192.
- First Proof Project: Second Batch Announcement.
- OpenAI: Our First Proof submissions.
- Aletheia tackles FirstProof autonomously, arXiv:2602.21201.



