ChatGPT помог решить 60-летнюю задачу Эрдеша
Лиам Прайс получил от GPT-5.4 Pro рабочий ход для задачи Эрдеша #1196, а математики проверили, упростили и формализовали доказательство.

ChatGPT помог решить 60-летнюю задачу Эрдеша. История важна по вполне практической причине: GPT-5.4 Pro подсказала рабочий ход для проблемы, на которой сильные люди много лет шли по неудачной траектории. Потом математики проверили идею, упростили её и встроили в нормальное человеческое доказательство.
Речь идёт о задаче Эрдеша #1196 про primitive sets, то есть множества натуральных чисел, где ни одно число не делится на другое. На странице erdosproblems.com по состоянию на 26 апреля 2026 года стоит статус PROVED (LEAN), а сама формулировка требует показать, что для примитивных множеств далеко на числовой прямой сумма Эрдёша становится не больше 1 + o(1).
ChatGPT не выдала готовое доказательство в журнальном виде. Куда важнее сам маршрут. Scientific American пишет, что 23-летний Лиам Прайс получил решение от GPT-5.4 Pro одним запросом, а Теренс Тао и Джаред Дьюкер Лихтман затем увидели в нём новый заход: модель применила к задаче формулу, знакомую в соседних участках математики, но раньше её не пытались использовать именно здесь.
Что произошло и почему вокруг этого столько шума
Историю удобно разложить на три даты. 5 марта 2026 года OpenAI выпустила GPT-5.4 и GPT-5.4 Pro как свои самые сильные модели для сложной профессиональной работы. В середине апреля на странице задачи Эрдеша #1196 появилось решение и статус PROVED (LEAN). А 24 апреля Scientific American вынесла кейс в массовую научпоп-повестку, потому что здесь сошлись сразу три редких вещи: сильная открытая математическая проблема, новый метод и признание со стороны людей уровня Тао.
| Дата | Что подтверждено | Почему это важно |
|---|---|---|
| 5 марта 2026 | OpenAI выводит GPT-5.4 и GPT-5.4 Pro в ChatGPT, API и Codex | У Прайса был доступ не к старой массовой модели, а к актуальной флагманской модели рассуждений OpenAI. |
| 15 апреля 2026 | Страница Erdős Problem #1196 обновлена со статусом PROVED (LEAN) |
Речь идёт не о слухе из соцсетей, а о зафиксированном результате на профильной площадке. |
| 24 апреля 2026 | Scientific American публикует разбор кейса Прайса, Тао и Лихтмана | История выходит за пределы узкого математического круга и становится тестом для разговора о больших языковых моделях в науке. |
Подобные истории про ИИ вокруг задач Эрдеша всплывают не впервые. Но сами математики давно предупреждают, что такие кейсы нельзя складывать в одну корзину. Задачи сильно отличаются по глубине, а многие прежние истории оказывались либо менее оригинальными, чем казалось сначала, либо просто слабым тестом для серьёзного разговора о математике.
В истории с #1196 планка выше. На странице проблемы прямо сказано, что Джаред Дьюкер Лихтман раньше доказал лишь более слабую верхнюю оценку. А новый апрельский результат даёт именно ту форму, которую хотели увидеть в задаче Эрдеша: для примитивных множеств хвост суммы оказывается не хуже 1 + O(1 / log x).
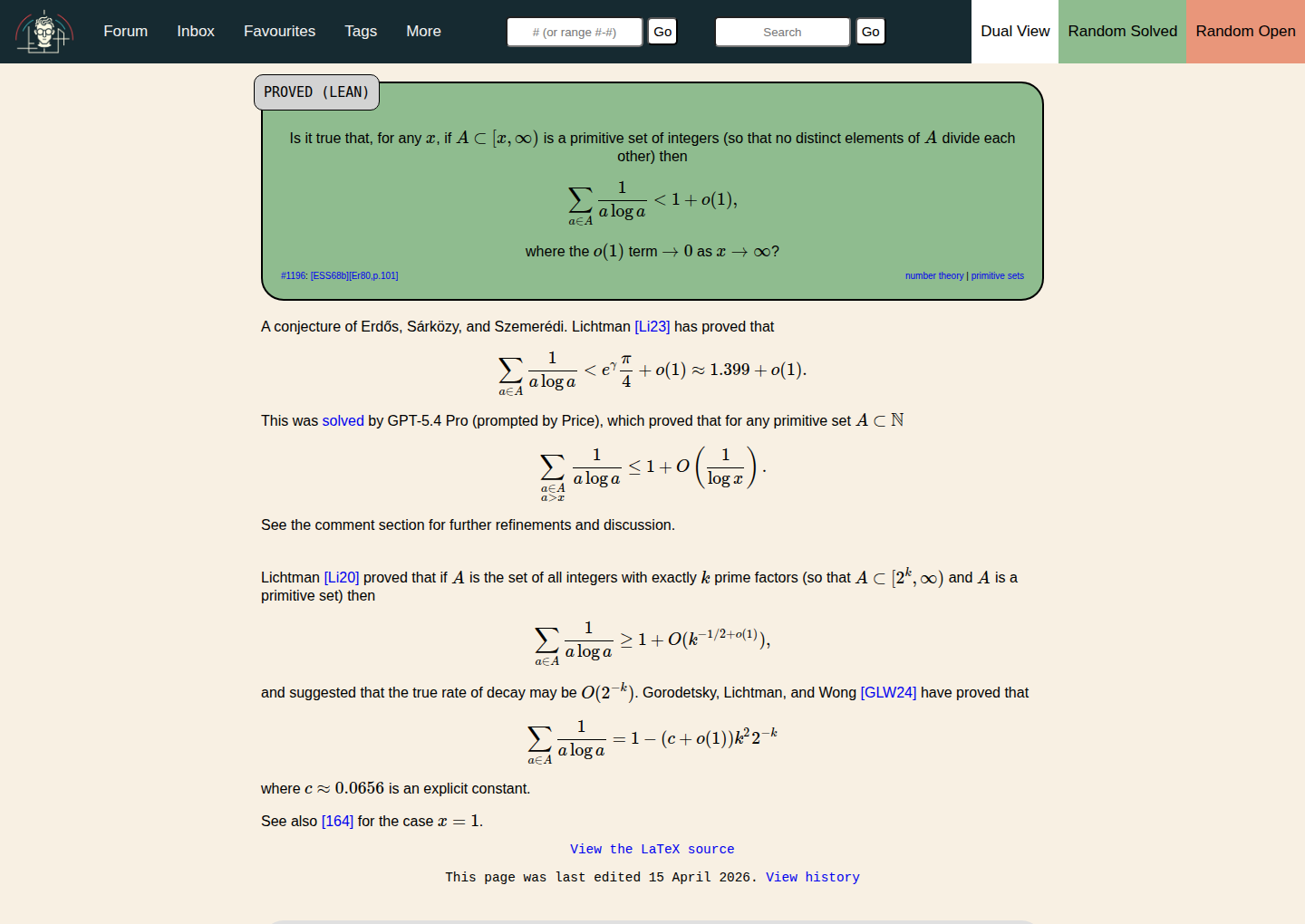
PROVED (LEAN), формулировка задачи и явная пометка, что решение получено с помощью GPT-5.4 Pro по запросу Прайса. Источник: erdosproblems.com.Почему это не история про «ChatGPT решила всё сама»
Самая важная деталь в материале Scientific American звучит почти буднично: сырой вывод ChatGPT был плохим по качеству. Лихтман говорит прямо, что эксперту пришлось разбирать этот текст, чтобы понять, к чему модель вообще ведёт. После этого он и Тао уже переписали доказательство в более короткой и понятной форме.
То есть реальная цепочка выглядела так: Прайс получает кандидатное решение, люди видят, что в нём есть сильная идея, затем эту идею очищают от мусора, проверяют, соотносят с предыдущими работами и формализуют. Это больше похоже на новую форму исследовательского инструмента, чем на автономную замену математика.
Заголовок уровня «ИИ решила задачу Эрдеша» здесь был бы редакционной ошибкой. Кейс важен сменой роли больших языковых моделей: такая система уже не только пересказывает известное, но и может выводить людей на перспективный ход там, где сообщество долго думало по инерции.
Эта рамка хорошо стыкуется с нашим недавним материалом про AI-агентов для peer review и работы с научными фигурами. И там, и здесь видно одно и то же: ценность модели появляется не в вакууме, а внутри контура проверки, где кто-то ещё должен оценить, что результат вообще стоит времени.
Что именно нового увидели математики
Если отбросить внешний шум, математическая новость тут довольно конкретна. Ulam note от 15 апреля 2026 года систематизирует обсуждение вокруг задачи #1196 и описывает три шага, через которые прошёл апрельский тред. Сначала Лиам Прайс дал короткое доказательство через нисходящую цепь делимости и веса фон Мангольдта. Затем Тао, Will Sawin и другие участники перевели эту идею в более чистую схему через канонический инвариантный вес ν. А Джаред Дьюкер Лихтман отдельно отметил, что вероятностная интуиция как таковая уже встречалась раньше, но именно арифметическая формулировка с весами фон Мангольдта оказалась новым шагом.
Звучит узко, но смысл понятен и без докторской степени. Модель не открыла новую вселенную. Она взяла формулу, известную в смежном контексте, и применила её к задаче, где люди исторически шли другим путём. Иногда именно такой перенос и даёт настоящий прогресс: не новая кирпичная стена текста, а новый угол входа.
На форуме Erdős Problems Project это видно и по реакции участников. Тао пишет, что прежние исследователи коллективно делали «чуть неверный поворот уже на первом ходу». А в дискуссии позже появляется ещё один важный вывод: получив рабочую асимптотику для инвариантной меры, можно описывать задачу не как разовый трюк, а как более общий язык для рассуждений о больших числах и делимости.
Отсюда и осторожный оптимизм. Тао не обещает, что мы завтра увидим лавину новых доказательств в том же стиле. Но он прямо говорит, что это хорошее достижение и что долгосрочная значимость метода пока ещё определяется. Этого достаточно, чтобы уверенно говорить о факте и механике, но не превращать кейс в сказку про мгновенную математическую сингулярность.
Где здесь GPT-5.4 Pro, а где человеческая работа
Отдельная линия истории касается самой модели. OpenAI 5 марта 2026 года вывела GPT-5.4 в ChatGPT, API и Codex, а GPT-5.4 Pro описала как вариант для самых сложных задач. Это важно, потому что кейс Прайса связан не с абстрактным «ChatGPT вообще», а с конкретным поколением моделей рассуждений, заточенных под длинные цепочки вывода и работу с инструментами.
Но и здесь нельзя уходить в маркетинг. Связка «современная модель рассуждений + сильный доменный эксперт» пока выглядит убедительнее, чем идея полностью самостоятельного ИИ-математика. Прайс сам не выдаёт историю за магию: он подал задачу модели, распознал, что ответ похож на правильный, и передал его людям, которые способны отделить перспективную идею от красивой галлюцинации.
В этом смысле история хорошо дополняет наш разбор GPT-5.4 от OpenAI. Там ключевой вопрос был в мощности модели и её агентном контуре. Здесь вопрос другой: что происходит, когда такая модель попадает в руки человека, который не обязан сам доводить доказательство до журнального стандарта, но умеет задавать правильный вопрос и быстро проверять, стоит ли ответ дальнейшего внимания.
Почему формальная верификация теперь не факультатив
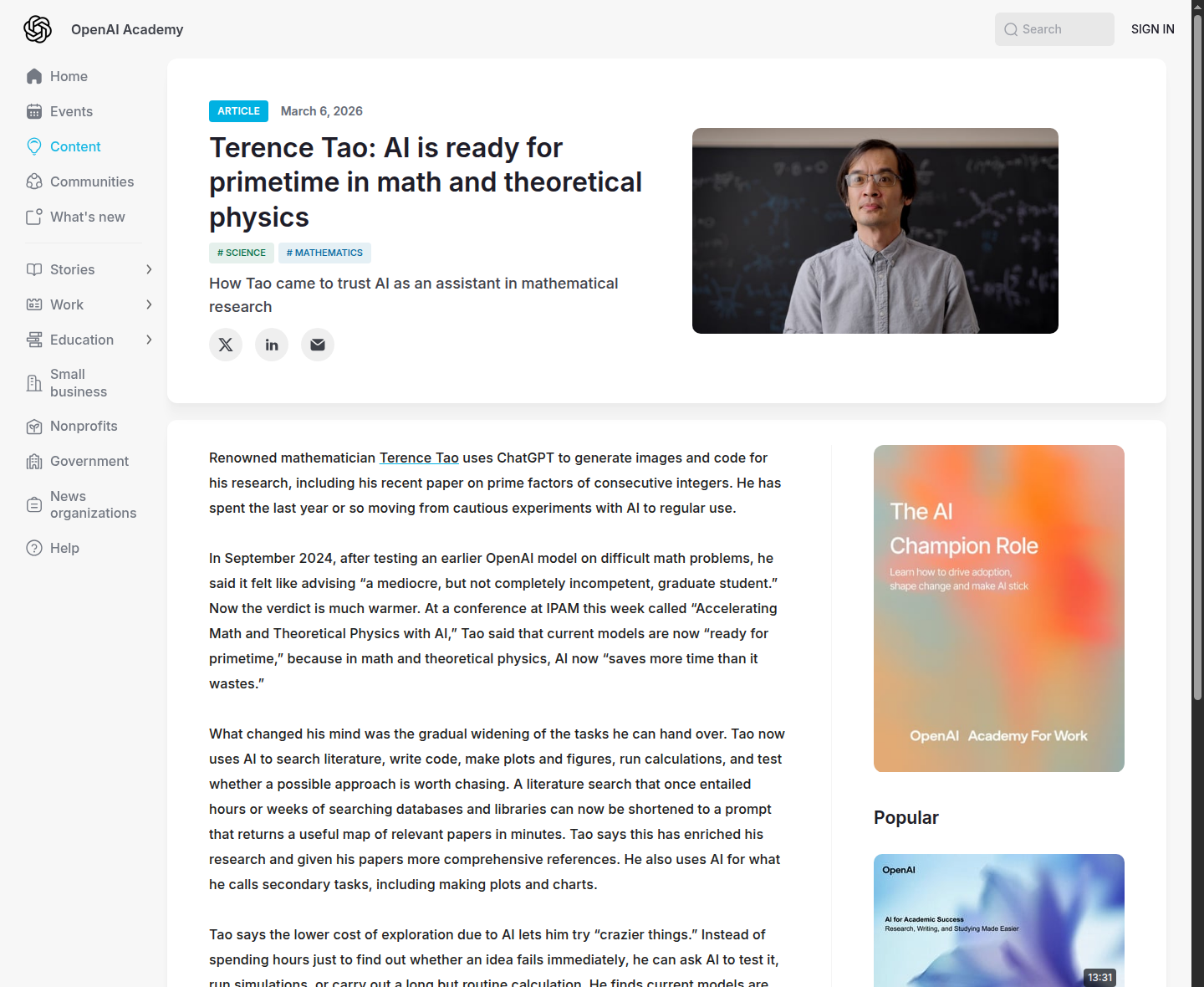
Самый практичный вывод из этой истории связан даже не с ChatGPT, а с проверкой. На странице задачи стоит пометка PROVED (LEAN), а в мартовском материале OpenAI Academy Тао отдельно объясняет, почему формальная верификация становится важнее. Если большая языковая модель умеет быстро производить правдоподобные доказательства и набрасывать новые маршруты, то слабым местом оказывается уже не генерация текста, а гарантия того, что в этом тексте не спряталась локальная ошибка.
Это ровно тот тип риска, который мы уже разбирали в материале про формальную верификацию и сбой в Lean 4. Когда доказательство или программа выглядят аккуратно, у человека возникает ложное чувство завершённости. Формальные инструменты нужны не потому, что математики перестали доверять себе, а потому, что теперь в цикл вошёл генератор идей, который умеет быть очень убедительным и очень неровным одновременно.
Для науки это может быть хорошей новостью. Если раньше часть времени уходила на долгий перебор тупиковых ходов, то теперь модель может ускорить именно раннюю фазу поиска. Но это работает только при одном условии: у исследователя остаётся жёсткий фильтр на проверку и переписывание результата в форму, пригодную для остальных людей.
Что этот кейс говорит о будущем больших языковых моделей в математике
Главное в истории Прайса — новая организация труда. Большая языковая модель становится не судьёй и не автором в традиционном смысле, а странным соавтором-эвристиком: она быстро предлагает ходы, иногда заходит в тупик, иногда выбрасывает мусор, но временами находит комбинацию, которую люди пропускали из-за инерции собственного стиля мышления.
Поэтому ближайший сценарий выглядит не как серия заголовков «ИИ решил X». Скорее мы увидим больше гибридных историй, где модель помогает с первым ходом, поиском эквивалентной формулировки, перебором инвариантов или переносом метода между соседними задачами, а люди закрывают вопрос строгости, понятности и воспроизводимости.
Если этот режим закрепится, самым дефицитным навыком станет не механическое доведение выкладок, а умение выбрать хорошую проблему, распознать в ответе модели нетривиальное зерно и быстро встроить его в нормальный исследовательский контур. Именно об этом Тао говорит в своём мартовском тексте: ИИ уже забирает рутинную часть работы, а ценность человека смещается в сторону постановки задачи, дизайна процесса и контроля качества.
История с задачей Эрдеша хороша тем, что здесь это видно без рекламного тумана. ChatGPT не победила математику и не отменила роль эксперта. Зато она, похоже, помогла сломать коллективную привычку думать о конкретной задаче только одним способом. Для 2026 года это уже достаточно большая новость.