Repo-level code localization: где AI-агенты ловят keyword shortcut
Repo-level code localization кажется сильнее, чем есть: новый paper показывает роль keyword shortcut и объясняет, что меняют KA-LogicQuery и LogicLoc.
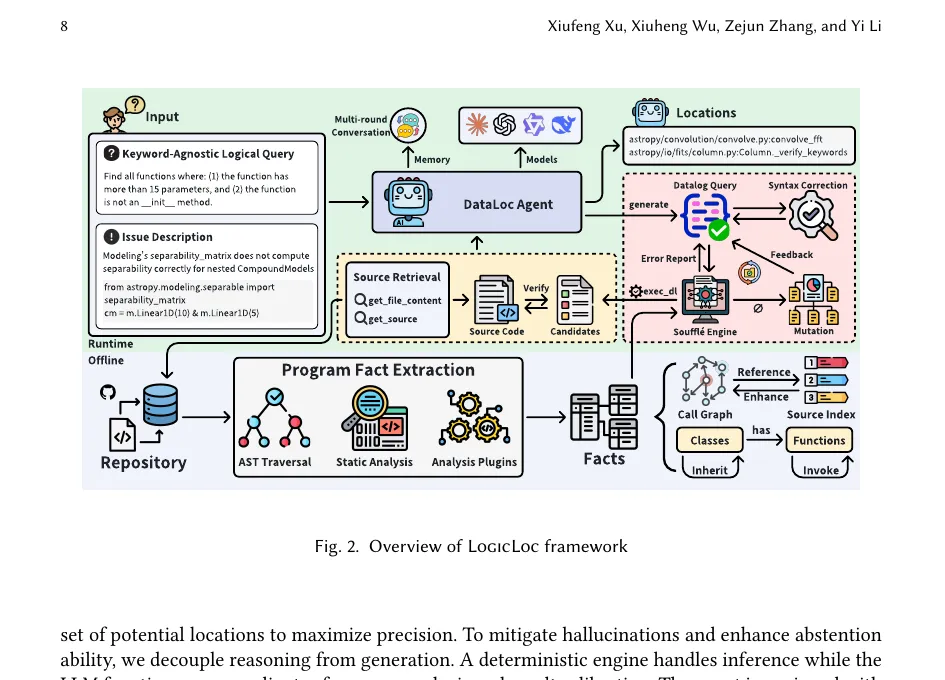
По состоянию на 21 апреля 2026 года один из самых неприятных вопросов для AI coding agents звучит так: они действительно понимают репозиторий или просто хорошо угадывают по названиям файлов и функций. Препринт Neurosymbolic Repo-level Code Localization, опубликованный на arXiv 17 апреля 2026 года, показывает, что многие популярные benchmark'и по локализации кода завышают способности моделей именно из-за этого эффекта.
Авторы называют его keyword shortcut. Если в описании задачи уже есть file path, class name или function name, модель может выйти на нужный участок через grep, embedding retrieval или грубую фильтрацию кандидатов. Это полезный эвристический трюк, но не то же самое, что структурное reasoning по чужой кодовой базе.
Для редакции важен не академический спор сам по себе. Repo-level code localization — один из базовых тестов для агентного программирования: прежде чем агент исправит баг, он должен понять, где вообще искать причину. Если benchmark измеряет в основном умение цепляться за naming hints, команда получает слишком оптимистичную картину реального уровня AI-агентов в сложном репозитории.
Как возникает keyword shortcut
Авторы препринта разбирают локализацию кода как задачу поиска точных мест в репозитории по естественному описанию проблемы. На практике именно с этого шага начинается почти любой агентный процесс: найти модуль, функцию или связку файлов, где сидит причина бага или нужная логика. Проблема в том, что многие issue-driven benchmark'и упрощают задачу сильнее, чем кажется.
В PDF paper есть две особенно важные цифры. Первая: более чем в 50% кейсов SWE-bench Lite issue description прямо содержит identifying information ground-truth location — file names, class names или function names. Вторая: SWE-bench Lite в среднем затрагивает только 1.15 code changes per issue. Когда пространство поиска и так узкое, а текст ещё и подсказывает точные identifiers, лидерборд легко начинает награждать не глубокое понимание репозитория, а удачный lexical matching.
| Сигнал | Что нашли авторы | Почему это важно |
|---|---|---|
| Issue text | >50% кейсов SWE-bench Lite содержат identifying info целевой локации | Модель может сузить поиск по названиям, а не по структуре кода |
| Размер реальной правки | В среднем 1.15 code changes per issue | Даже слабый локализатор получает очень узкое пространство поиска |
| Новый диагностический benchmark | KA-LogicQuery: 225 logic-intensive queries across 9 projects | Он убирает naming hints и заставляет проверять именно structural reasoning |
Это не означает, что issue-driven benchmark'и бесполезны. Они ближе к реальной разработке, где баг действительно приходит через issue. Но paper показывает важную границу: если benchmark слишком щедро раздаёт file names и function names, модель может пройти локализацию как задачу retrieval, а не как задачу понимания зависимостей, потока исполнения и ограничений внутри кодовой базы.
Почему это проблема именно для AI coding agents
Хороший инженер, который впервые заходит в чужой репозиторий, обычно не знает точного имени функции заранее. Он описывает поведение: «найди, где создаётся такой-то побочный эффект», «пойми, почему этот путь ломается при composite moduli», «какой участок кода проверяет это условие». Если benchmark учит агента ждать готовый identifier в issue text, такой тест плохо переносится на реальный production workflow.
Здесь новый препринт хорошо рифмуется с другой линией критики coding benchmark'ов. В статье Why SWE-bench Verified no longer measures frontier coding capabilities, опубликованной OpenAI 23 февраля 2026 года, компания сообщила, что в аудите 138 задач минимум 59.4% содержали существенные проблемы тестов и/или описаний, а сама SWE-bench Verified всё сильнее отражает contamination, а не реальную coding capability. Это другой класс проблемы: OpenAI пишет о flawed tests и утечке решений в обучение, а новый препринт — о naming hints и keyword shortcut. Но вывод у них общий: красивый leaderboard по coding benchmark'ам всё хуже совпадает с тем, как агент ведёт себя в живой кодовой базе.
Для команд разработки это не теоретический нюанс. Если агент ошибается на шаге локализации, дальше он начинает дорого шуметь: читает не те файлы, запускает не те проверки, собирает лишний контекст и возвращает diff, который выглядит правдоподобно, но стоит на ложной гипотезе. Мы уже видели более общий вариант этой поломки в материале о том, как бенчмарки ИИ-агентов дают ложное чувство способности. Здесь речь о более узкой и потому более опасной вещи: где именно ломается reasoning по репозиторию.
Что делает KA-LogicQuery
Чтобы убрать shortcut, авторы вводят задачу Keyword-Agnostic Logical Code Localization и benchmark KA-LogicQuery. В нём 225 запросов по 9 проектам, и эти запросы формулируются не через готовые названия функций или файлов, а через составные логические условия. Идея простая: если модель действительно понимает структуру репозитория, она должна пройти и такой тест.
В препринте это выглядит наглядно. Запрос может описывать не имя функции, а её свойства: например, найти функции, у которых больше 15 параметров и которые не являются __init__-методами. Дальше система должна пройти от естественного описания к формальной проверке по program facts, а не искать буквальное совпадение строки в коде.

У авторов есть ещё один умный ход: KA-LogicQuery-Neg, то есть вариант benchmark'а, где правильный ответ — пустое множество. Это проверка на abstention. Хороший локализатор должен не только что-то находить, но и уметь честно сказать: «в репозитории нет места, которое удовлетворяет этим ограничениям». Для автономных агентов это критично. Галлюцинировать кандидат на локацию иногда опаснее, чем не найти ничего.
Как устроен LogicLoc
Препринт предлагает не только новый benchmark, но и собственный агентный фреймворк LogicLoc. Его идея в том, чтобы разделить роли. LLM не пытается сама обходить репозиторий шаг за шагом до бесконечности. Сначала система извлекает из кода program facts: сущности, связи, call graph, inheritance, reference edges и другие структурные признаки. Затем модель синтезирует Datalog-программу, которая выражает нужный логический запрос.
После этого включается уже не языковая модель, а детерминированный движок. В LogicLoc есть parser-gated validation, ремонт синтаксиса, промежуточная диагностическая обратная связь и исполнение через Soufflé. Проще говоря, LLM здесь не заменяет reasoning engine, а формулирует задачу для него. Глубокий структурный обход репозитория делегируется формальной системе, которая умеет отвечать точно и воспроизводимо.
Здесь и появляется практическая ценность этой работы. Авторы не говорят «давайте просто дадим модели больше токенов и больше tool calls». Они показывают другую архитектуру: текстовая модель хороша в переводе намерения в формальное описание, а логический движок хорош в проверяемом обходе зависимостей. Для repo-level reasoning это куда взрослее, чем бесконечный multi-turn search по файлам.
Какие цифры у LogicLoc и где граница
На KA-LogicQuery paper показывает очень сильный результат. На file level LogicLoc достигает Precision 73.35%, Success Rate 68.44% и Perfect Location Rate 48.44%. На function level у LogicLoc PLR 38.27%, тогда как у baseline-методов этот показатель падает до нуля. Авторы отдельно подчёркивают, что при удалении naming hints baseline-агенты быстро теряют meaningful localization capability.
При этом на обычных issue-driven benchmark'ах LogicLoc не разваливается. Наоборот, paper пишет, что система остаётся competitive, но даёт в среднем только 2 candidate locations per issue. Это важная деталь. Многие локализаторы раздувают top-n список, чтобы случайно накрыть правильный участок. LogicLoc делает ставку на более короткий и более точный список входных точек, то есть уменьшает шум для разработчика или downstream-агента.
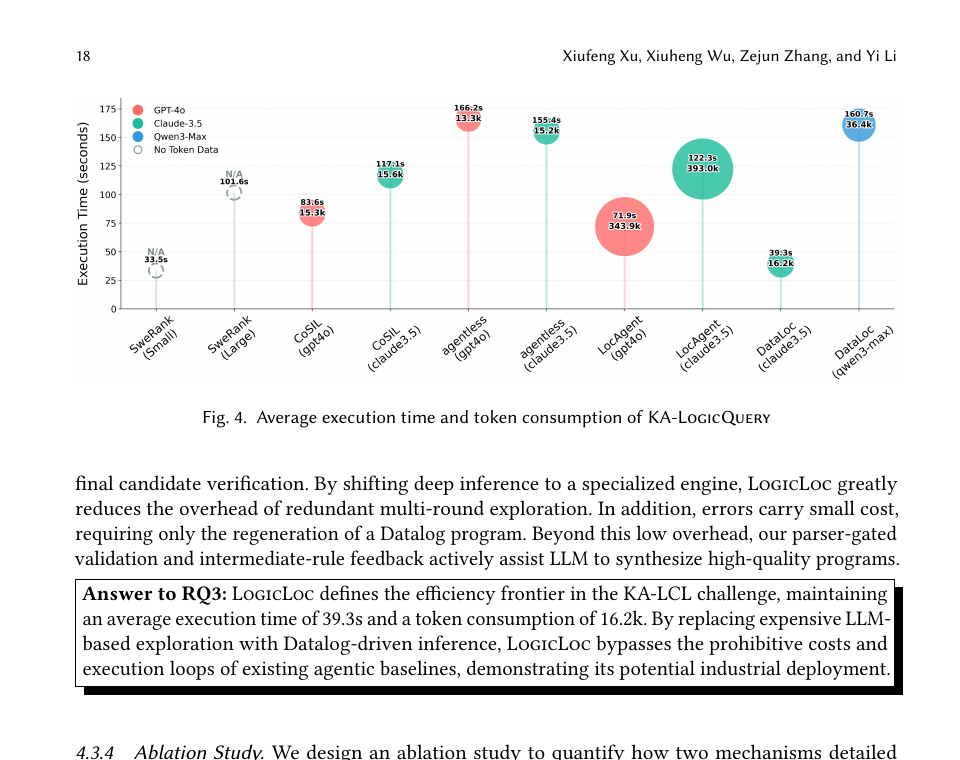
По эффективности цифры тоже редкие для агентных инструментов: среднее время исполнения 39.3s, среднее потребление 16.2k токенов. Paper отдельно пишет, что даже самый быстрый LocAgent с GPT-4o остаётся примерно вдвое медленнее, а Agentless и LocAgent тратят больше чем на порядок больше токенов. Это сильный аргумент в пользу нейросимволической схемы: дорогое текстовое исследование репозитория не всегда нужно, если основную структурную работу можно отдать детерминированному движку.
Но эти цифры не означают, что проблема repo reasoning уже решена. LogicLoc — это research prototype и evaluation внутри paper. Авторы сами сравнивают систему на своём диагностическом benchmark'е и в конкретной настройке baseline-методов. Production-репозитории сложнее: там есть полиглотные проекты, инфраструктурный код, внешние сервисы, права доступа, runtime-состояние и человеческий контекст, который не лежит в AST. Поэтому корректный вывод уже другой: paper показывает более честную постановку задачи и сильный архитектурный ход, а не окончательную победу над локализацией кода.
Именно на таких старых и неровных кодовых базах обычно и начинается реальная боль, о которой мы уже писали в материале «ИИ-агенты ломают код: три проблемы от создателя libGDX». Там проблема проявляется как накопление ошибок. Здесь paper показывает ещё более раннюю стадию: агент может ошибиться ещё до самого патча, когда он только выбирает, куда смотреть.
Что из этого брать командам разработки
Первый вывод для команд простой: перестаньте читать score по repo-level localization как прямой эквивалент «агент понимает кодовую базу». Нужно спрашивать, какие именно подсказки были в задаче. Если benchmark оставляет в issue text file names, class names и function names, это уже другая задача, ближе к retrieval и ranking.
Второй вывод: при внутренней оценке AI coding agents стоит отдельно тестировать режим без naming hints. Если вы хотите понять, насколько агент ориентируется в чужом репозитории, задавайте вопросы через поведение, инварианты и связи между модулями. Хороший локализатор должен уметь работать не только с явным identifier, но и с абстрактным описанием проблемы.
Третий вывод: смотрите не только на Acc@k, но и на плотность рекомендаций, precision и способность к отказу. Модель, которая всегда отдаёт пять кандидатов, может выглядеть прилично в таблице и при этом создавать лишнюю ручную работу. Для реального engineering workflow часто полезнее агент, который даёт два точных входа или честно возвращает пустой результат.
И четвёртый вывод: не путайте scaffolding с пониманием. Команды всё равно будут компенсировать слабое repo reasoning через CLAUDE.md, skills, rulesync и другие проектные инструкции. Это нормальная инженерная практика. Мы подробно разбирали её в материале о настройке AI-агентов через CLAUDE.md, skills и rulesync. Но такая обвязка должна помогать агенту работать безопаснее и предсказуемее, а не подменять собой честную оценку того, понимает ли он репозиторий без готовых ключевых слов.
Главный вывод
Repo-level code localization остаётся слабым местом AI coding agents даже тогда, когда leaderboard выглядит уверенно. Новый paper полезен не потому, что он объявляет старые benchmark'и «мёртвыми», а потому, что аккуратно показывает, где именно возникает shortcut: модель цепляется за file names и function names вместо того, чтобы разбирать структуру репозитория.
Для рынка это отрезвляющий сигнал. Вопрос уже не в том, умеет ли агент выдавать красивый patch на тестовом issue. Вопрос в том, что произойдёт, если убрать naming hints и попросить его искать причину так, как это делает человек, впервые пришедший в чужую кодовую базу. Именно там и начинается реальное agentic coding.
Источники и дата проверки
Факты в материале проверены 21 апреля 2026 года по странице paper на arXiv, PDF paper и официальной статье OpenAI Why SWE-bench Verified no longer measures frontier coding capabilities.



