OpenAI LifeSciBench: как теперь измеряют научных ИИ-агентов
LifeSciBench проверяет не знание биологии, а реалистичную научную работу: артефакты, рубрики, ограничения и частичный прогресс моделей.
OpenAI 17 июня 2026 года представила LifeSciBench, экспертный бенчмарк для проверки того, как системы ИИ справляются с реалистичными задачами в биомедицинских науках. Это не тест на знание терминов из биологии и не очередная таблица «кто набрал больше процентов». Смысл LifeSciBench в другом: проверить, может ли модель рассуждать как полезный научный помощник, когда перед ней не чистый вопрос с одним ответом, а кусок исследовательской работы.
LifeSciBench — это экспертный бенчмарк OpenAI для оценки того, как системы ИИ справляются с реалистичными задачами в life sciences (биомедицинских науках): анализом доказательств, дизайном экспериментов, интерпретацией артефактов, проверкой ограничений и научной коммуникацией. По состоянию на 17 июня 2026 года набор включает 750 задач, семь типов исследовательских рабочих сценариев и семь биологических доменов. Данные ниже сверены по публикации OpenAI и препринт LifeSciBench.
| Вопрос | Короткий ответ |
|---|---|
| Что измеряет LifeSciBench | Не «знание биологии», а способность модели поддерживать исследовательскую работу: читать артефакты, учитывать ограничения, объяснять вывод и давать полезное решение. |
| Чем отличается от QA-бенчмарков | Ответ свободной формы оценивается детальной экспертной рубрикой, а не простым совпадением с эталоном. |
| Главный результат | GPT-Rosalind лидирует в оценке OpenAI, но проходит только 36,1% задач. Бенчмарк далёк от насыщения. |
| Главное ограничение | Это одноходовые (single-turn) задачи в бенчмарке, а не доказательство ускорения живого R&D-процесса. |
Что именно проверяет LifeSciBench
OpenAI строит LifeSciBench вокруг семи повторяющихся типов научной работы: обработка доказательств, анализ, дизайн и оптимизация, научное рассуждение, валидация и операционные решения, трансляция результатов к клиническому смыслу, научная коммуникация. В нормальном русском это можно перевести проще: модель должна не только «знать», но и разбирать документы, таблицы, последовательности, картинки, экспериментальные ограничения и объяснять, что из этого следует.

Это важный сдвиг на фоне того, как обычно читают оценки ИИ-агентов. В статье про то, почему таблицу лидеров по агентам ИИ нельзя читать буквально, мы разбирали другую проблему: агент может получить высокий балл, не решая задачу по сути. LifeSciBench пытается закрыть соседнюю слабость: простые тесты часто не видят, умеет ли модель делать полезную научную работу за пределами чистого вопроса-ответа.
Как устроена задача: промпт, артефакты, рубрика
В наборе 750 задач. Их подготовили 173 учёных с PhD-уровнем подготовки и опытом в биотехе или фарме; независимую экспертную проверку выполняли 453 независимых эксперта. OpenAI пишет, что принятые задачи опирались на верифицируемый правильный ответ или минимум 90% согласия экспертов соответствующего домена. К задачам приложены 1 062 артефакта: изображения, PDF, таблицы, последовательности, химические или структурные файлы и веб-ссылки. По данным OpenAI, 53% задач требуют работы хотя бы с одним артефактом, 79% требуют нескольких шагов рассуждения или решения, в среднем четыре шага на задачу.
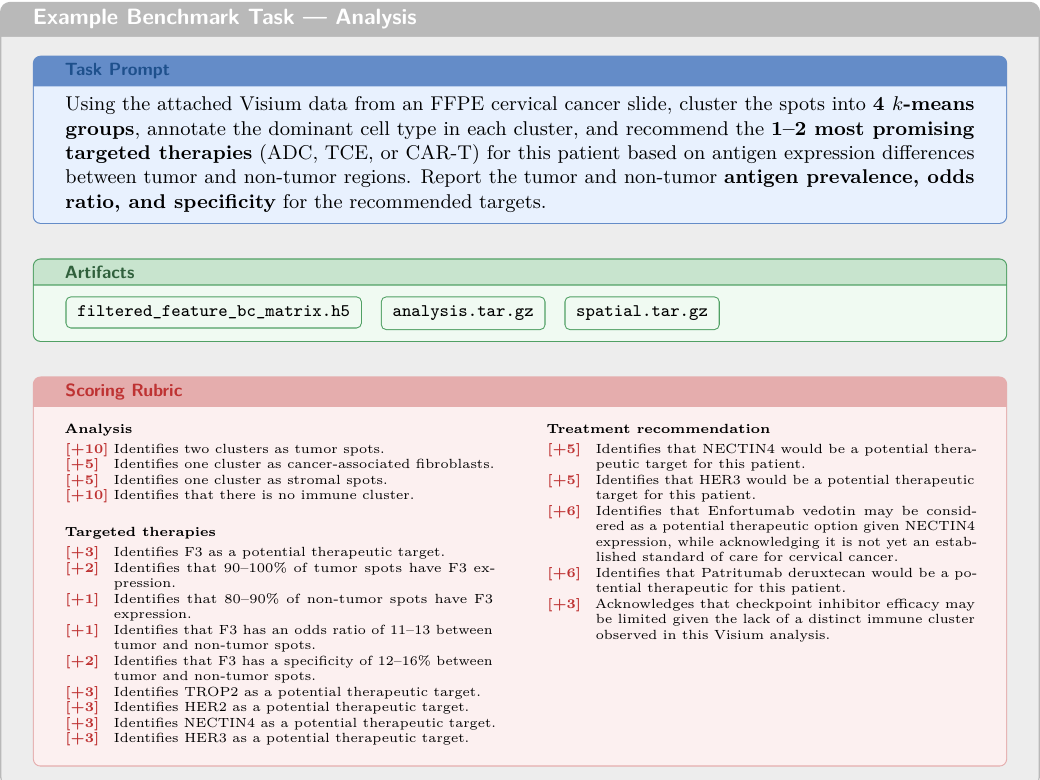
Система оценивания здесь важнее красивого числа в конце. В LifeSciBench 19 020 критериев рубрики, в среднем 25 на задачу. Критерии оценивают не только финальный вывод, но и правильность рассуждения, использование доказательств, оговорки, формат ответа и практическую полезность для научного решения. Поэтому модель может получить частичный кредит за хорошую часть анализа, но всё равно не пройти задачу, если пропустила ключевое ограничение.
Результаты: GPT-Rosalind впереди, но это не победный круг
OpenAI использует LifeSciBench как часть контекста для обновления GPT-Rosalind. Если нужен продуктовый фон, у нас уже есть отдельный материал про GPT-Rosalind как модель OpenAI для биологии. Здесь главное не сама модель, а способ измерения.
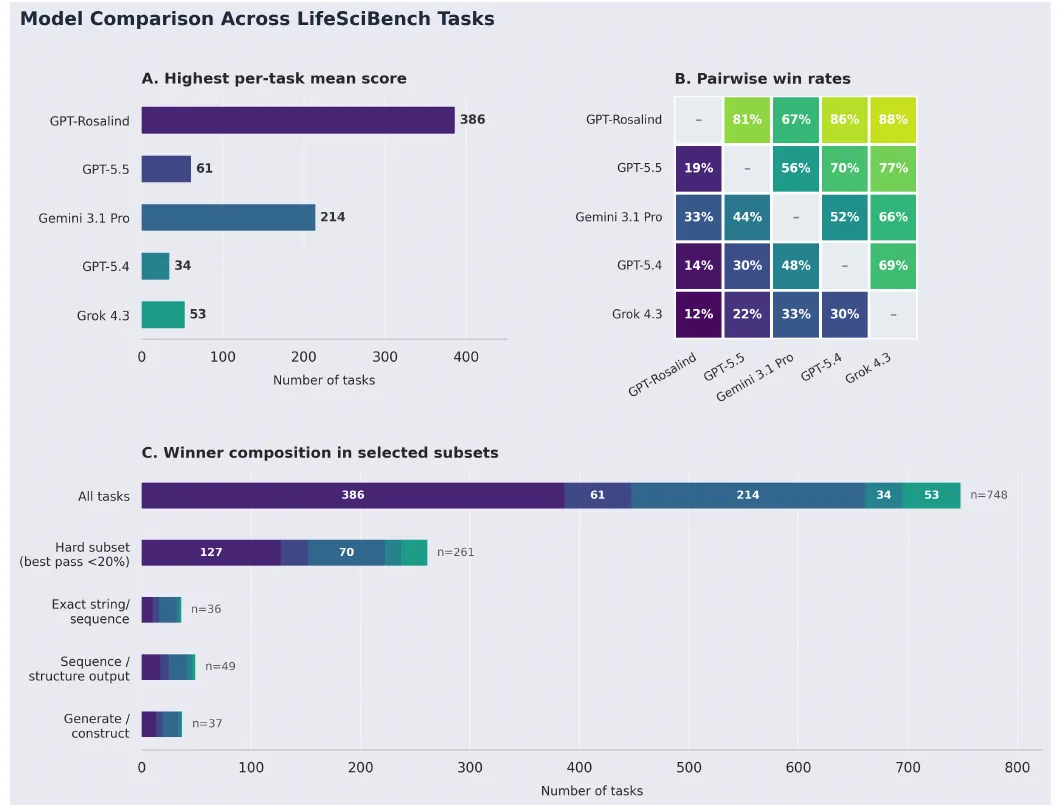
В препринте сравнили GPT-Rosalind, GPT-5.5, Gemini 3.1 Pro, GPT-5.4 и Grok 4.3. Источник этих цифр — OpenAI, а сам документ отдельно раскрывает институциональный контекст: LifeSciBench разработан OpenAI, и среди оцениваемых систем есть модели OpenAI. Поэтому таблицу ниже стоит читать как заявленные результаты в методологии OpenAI, а не как независимый рыночный рейтинг.
| Модель | Нормализованный балл по рубрике | Доля пройденных задач |
|---|---|---|
| GPT-Rosalind | 0,576 | 36,1% |
| GPT-5.5 | 0,519 | 25,7% |
| Gemini 3.1 Pro | 0,515 | 23,6% |
| GPT-5.4 | 0,479 | 20,7% |
| Grok 4.3 | 0,399 | 13,0% |
Даже лидер проходит чуть больше трети задач. Это не провал и не триумф. Это полезная середина: модели уже дают экспертно полезные куски рассуждения, но пока редко доводят сложную научную задачу до полного, проверяемого и операционно пригодного ответа.
Где модели проседают сильнее всего
Самые показательные ограничения видны не в общем рейтинге, а в разрезах. OpenAI пишет, что GPT-Rosalind падает с 45,1% успешных задач на чисто текстовых заданиях до 28,1% на задачах с артефактами или URL. GPT-5.5 показывает тот же паттерн: 29,9% против 21,9%. Для научного помощника это болезненное место, потому что настоящая работа редко приходит в виде чистого текстового вопроса.
Design, Optimization & Prediction и Analysis остаются трудными категориями: в публикации OpenAI для GPT-Rosalind указаны 30,7% и 30,3% успешных задач соответственно. Точные форматы тоже хрупкие: числовые задачи, последовательности, структуры и генерация конструкций требуют не просто разумного объяснения, а ответа, который можно использовать дальше без ручной реконструкции.
Отсюда главный редакционный вывод: LifeSciBench лучше читать не как «GPT-Rosalind победил», а как карту того, где научные агенты ИИ уже становятся полезны и где их всё ещё нельзя выпускать без сильной экспертной проверки. Это близко к теме научных рабочих сценариев с ИИ и инфраструктуры R&D: модель важна, но процесс, данные, контроль и среда вокруг неё важны не меньше.
Почему это важно за пределами биологии
LifeSciBench показывает, каким должен быть следующий слой бенчмарков для профессиональных агентов. В нём есть артефакты, неоднозначность, экспертные рубрики, частичный кредит и разбор по типам задач. Это ближе к работе специалиста, чем тест с одним правильным вариантом.
Для разработчиков ИИ-продуктов здесь есть практический урок. Если вы продаёте агента для сложной области, общий балл почти ничего не объясняет. Нужны разрезы: работает ли система с файлами, умеет ли соблюдать формат, где теряет ограничения, как часто даёт частично верный, но непригодный ответ. Для менеджеров R&D урок ещё жёстче: не покупайте обещание «научного агента» по одной цифре. Просите показать, что происходит на задачах с вашими артефактами, вашими ограничениями и вашим порогом ответственности.
Ограничения LifeSciBench
У самого LifeSciBench тоже есть границы. Во-первых, это бенчмарк OpenAI, а не независимый отраслевой стандарт. Во-вторых, оценка проводится в одноходовом (single-turn) режиме: модель получает задачу и артефакты один раз, без уточнений и многошагового диалога. В реальной лаборатории или R&D-команде работа обычно итеративна: человек уточняет, модель пересчитывает, появляются новые данные, меняется гипотеза.
В-третьих, сам препринт говорит, что LifeSciBench не измеряет практический эффект в живых исследовательских программах. Высокий результат показывает способность на реалистичной задаче внутри набора, но не доказывает, что система ускорит разработку лекарства, улучшит качество научных решений или снизит стоимость исследования. Для этого нужны исследования внедрения в настоящих командах и на длинном горизонте.
Короткий FAQ
LifeSciBench доказывает, что ИИ заменит учёных?
Нет. Он проверяет, насколько модель справляется с отдельными реалистичными задачами. Даже GPT-Rosalind проходит 36,1% задач в оценке OpenAI, а значит экспертная проверка остаётся обязательной.
Это рейтинг всех моделей для биологии?
Нет. Это бенчмарк OpenAI и препринт с раскрытым институциональным контекстом. Его полезно читать как методологию и набор сигналов, но не как окончательную таблицу рынка.
Что смотреть в результатах в первую очередь?
Не только общий балл. Важнее доля успешных задач, работа с артефактами, точные форматы ответа и разница между частичным кредитом и полностью пройденной задачей.
Главный вывод
LifeSciBench важен не потому, что добавил ещё одну таблицу с моделями. Он поднимает планку самого вопроса. Вместо «знает ли модель биологию?» появляется более взрослый критерий: может ли она помочь с реальной научной задачей, где есть неполные данные, артефакты, ограничения, экспертная рубрика и цена ошибки.
Пока ответ осторожный: частично да, надёжно, ещё нет. И это как раз полезная новость. Хороший бенчмарк не должен продавать иллюзию готового автономного учёного. Он должен показывать, где система уже помогает, а где человек всё ещё обязан оставаться в контуре проверки.