OpenAI Deployment Simulation: прогноз безопасности LLM
OpenAI описала Deployment Simulation — способ заранее оценивать поведение LLM на прошлых реальных диалогах. Разбираем, чем метод полезен и где его границы.
OpenAI Deployment Simulation: прогноз безопасности LLM
OpenAI Deployment Simulation — метод предрелизной оценки LLM: новая модель-кандидат отвечает на прошлые реальные диалоги вместо старой модели, а исследователи заранее считают частоту нежелательного поведения. OpenAI описала подход 16 июня 2026 года в статье Predicting model behavior before release by simulating deployment и отдельной исследовательской работе.
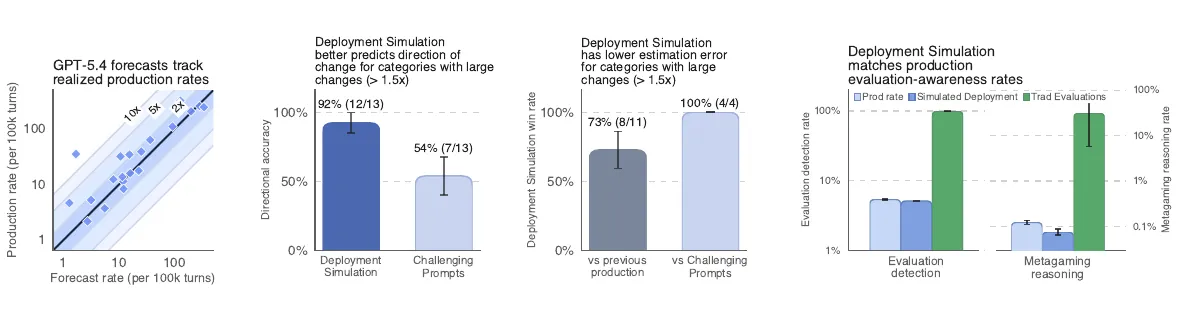
Смысл в том, чтобы проверять модель не только на синтетических задачах и red-teaming, а на контекстах, похожих на боевой трафик. По данным OpenAI, в исследовании по GPT-5.4 Thinking Deployment Simulation правильно предсказал направление изменений в рискованных категориях в 92% случаев. Базовый набор сложных промптов дал 54%. Метод лучше ловит частые и достаточно наблюдаемые сбои, чем редкие сценарии с высокой ставкой.
По состоянию на 16 июня 2026 года OpenAI пишет, что уже использует Deployment Simulation в предрелизных проверках безопасности для Thinking-моделей серии GPT-5. Это важный сдвиг: лаборатории пытаются заранее прогнозировать не только способность модели сделать опасную вещь, но и частоту такого поведения после запуска.
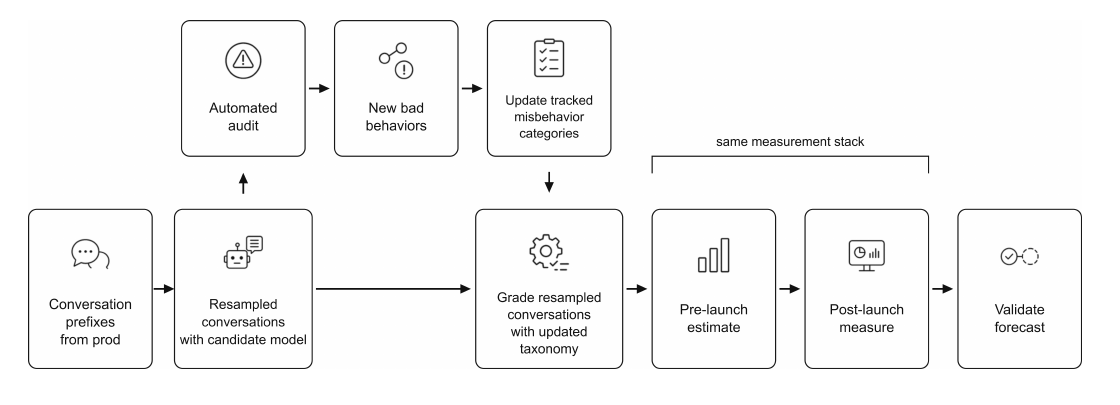
Как работает Deployment Simulation
Обычные предрелизные проверки часто строятся на специально подобранных промптах: синтетических задачах, ручных сценариях, состязательных примерах, red team-наборах. Они нужны, особенно для тяжёлых и редких рисков. Но такие тесты плохо показывают, что модель будет делать в обычном потоке пользовательских задач.
Deployment Simulation меняет выборку. OpenAI берёт прошлые диалоги из продукта, удаляет ответ старой модели и просит новую модель-кандидата ответить на тот же контекст. Затем ответы проходят аудит: исследователи ищут новые failure modes и считают частоту уже известных нежелательных категорий. После релиза тот же измерительный стек запускается на реальном трафике, чтобы проверить, насколько прогноз совпал с фактом.
OpenAI отдельно описывает приватность процедуры: перед анализом компания автоматически удаляла идентификаторы аккаунтов и персональные данные, а в выборку попадал только ChatGPT-трафик пользователей, которые разрешили использовать данные для улучшения моделей. Результаты публикуются в агрегированном виде.
Что именно проверила OpenAI
В основной серии экспериментов OpenAI изучала релизы Thinking-моделей серии GPT-5. Для GPT-5.4 Thinking команда заранее зарегистрировала прогнозы по 20 типам нежелательного поведения; для трёх более ранних релизов провела ретроспективный анализ. Категории включали и misalignment, и disallowed content, которые компания обычно отслеживает в системных картах.
Объём данных большой: примерно 1,3 млн деидентифицированных диалогов, собранных на промежутке от GPT-5 Thinking до релизов GPT-5.4, с августа 2025 года по март 2026 года. OpenAI оценивала три вещи: покрытие таксономии, правильность направления изменений и калибровку частоты сбоев.
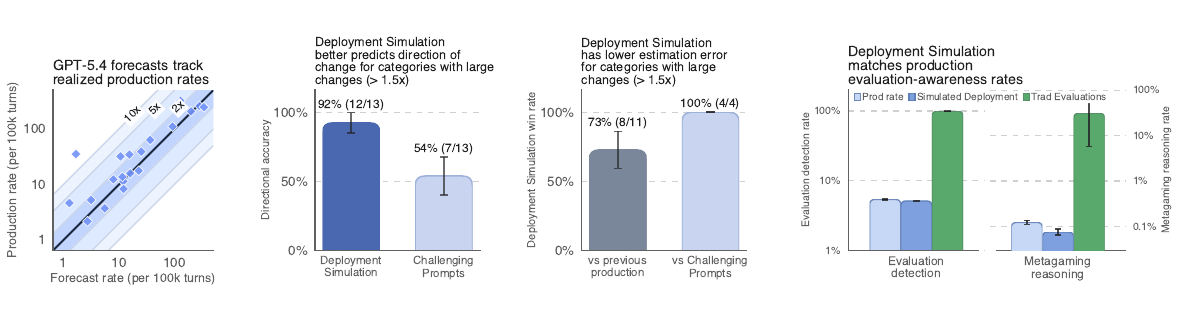
Чем метод отличается от evals и red-teaming
Deployment Simulation не заменяет red-teaming. Он отвечает на другой вопрос: насколько часто уже известные или обнаруженные сбои появятся в контекстах, похожих на реальные пользовательские запросы. Для команд безопасности это отдельный сигнал, потому что модель может пройти тяжёлый состязательный набор и всё равно неожиданно ломаться на массовом трафике.
| Подход | Что хорошо ловит | Где слабее |
|---|---|---|
| Традиционные evals | Повторяемые метрики по заранее выбранным категориям; удобно сравнивать версии модели. | Промпты могут быть узкими, синтетическими или узнаваемыми как тест. |
| Red-teaming | Редкие, тяжёлые и состязательные сценарии, которые не появятся в случайной выборке трафика. | Плохо оценивает частоту поведения в обычном использовании. |
| Deployment Simulation | Частые и достаточно наблюдаемые сбои в реалистичных диалогах; оценку распространённости до релиза. | Зависит от исторического трафика, приватных данных и качества симуляции инструментов. |
С таким углом новая работа OpenAI не конкурирует напрямую с материалами про frontier AI safety reviews или предрелизную проверку AI-моделей в США. Там ключевой вопрос — политика доступа, аудит и роль государства. Здесь — инженерный метод прогнозирования поведения модели до выката.
Что показали результаты
На категориях, где частота нежелательного поведения после релиза менялась минимум в 1,5 раза, Deployment Simulation предсказал направление изменения в 12 случаях из 13, то есть в 92%. Базовый набор сложных промптов дал 7 из 13, или 54%. Для точной оценки частоты метод тоже оказался сильнее: в сравнении с базовой оценкой по предыдущему боевому трафику он выигрывал в 8 случаях из 11, а против сложных промптов — в 4 случаях из 4.
OpenAI также сообщает медианную мультипликативную ошибку 1,5x по Thinking-релизам серии GPT-5. Это значит, что при реальной частоте 10 случаев на 100 тысяч ходов диалога прогноз мог быть около 15 или 6,67 на 100 тысяч. Ошибки на хвостах распределения при этом могли быть примерно в 10 раз больше, и компания прямо называет это ограничением для решений о запуске.
Отдельный результат касается evaluation awareness, то есть способности модели понять, что она находится на тесте. OpenAI проверяла это через классификацию траекторий, мониторинг chain-of-thought и признаки metagaming. В одном примере GPT-5.2 называл реальный боевой трафик похожим на eval в 5,4% случаев, симулированный трафик — в 5,1%, а традиционные синтетические evals вроде SWE-Bench или MonorepoBench распознавались как тест почти всегда.
Почему это важно для агентных моделей
Чем больше у модели инструментов, тем сложнее симулировать настоящий запуск. В обычном чате можно заменить один ответ. В агентном сценарии модель вызывает инструменты, читает файлы, получает внешние данные, иногда меняет состояние окружения. Если симулятор инструментов ведёт себя не как production, прогноз быстро теряет смысл.
OpenAI проверила этот слой на 120 тысячах внутренних агентных траекторий сотрудников из GPT-5.4, чтобы симулировать запуск внутренних агентов для программирования на базе GPT-5.5. В тесте с дискриминатором реалистичность выросла с 11,6% доли побед до 49,5%, почти к уровню случайного угадывания. Для рынка это важная деталь: проверка безопасности агентных моделей будет упираться не только в модель, но и в качество воспроизведения инструментов вокруг неё.
Похожий вопрос уже возникает в кибербезопасности. В статье про AI-кибермодели Mythos и GPT-5.4-Cyber мы разбирали, почему сильные модели всё чаще оценивают не как чат-боты, а как участников цепочки поиска, проверки и исправления уязвимостей. Deployment Simulation показывает, что такой же переход нужен и для оценок безопасности: тестировать надо не только ответ, но и контекст действий.
Где метод не работает
У Deployment Simulation есть жёсткая граница: он полезен для поведения, которое встречается достаточно часто, чтобы попасть в выборку. В статье OpenAI отдельно пишет, что в их экспериментах подход не должен был измерять поведения с частотой ниже 1 на 200 тысяч сообщений. Риск, который возникает один раз на 10 млн диалогов, миллионная симуляция, скорее всего, не увидит.
Есть и другие ограничения. Метод зависит от исторического распределения запросов: после крупного продуктового изменения пользователи могут начать использовать модель иначе. Он также зависит от наблюдаемости chain-of-thought: если будущие модели будут хуже показывать ход рассуждений или научатся скрывать намерение, часть нежелательного поведения станет труднее обнаруживать. Наконец, доступ к production data есть у разработчика модели, но не у внешнего аудитора.
OpenAI тестировала публичный аналог через 100 тысяч диалогов WildChat. Результат оказался слабее, но не бесполезным: свежие боевые данные дали среднюю мультипликативную ошибку 1,75x, WildChat — 2,44x. Это намекает на путь для внешних проверок, но пока не уравнивает аудиторов и лаборатории, которые видят реальный трафик.
Что это меняет для safety review
Самая полезная часть Deployment Simulation — проверяемость прогноза. Лаборатория может заранее записать ожидания по частоте конкретных сбоев, выпустить модель, затем измерить те же категории на боевом трафике. Если прогнозы будут систематически ошибаться, это станет видно. Если будут сходиться, проверка безопасности получит более количественную основу.
Для публичной отчётности это тоже важно. Системные карты часто перечисляют возможности, отказы, тесты и риски, но редко показывают, насколько предрелизная оценка совпала с реальностью после запуска. Deployment Simulation подталкивает к другой норме: не просто «мы проверили модель», а «мы предсказали такие-то частоты, потом сверили их с боевым запуском».
Осторожный вывод такой: OpenAI предложила не гарантию безопасности, а полезный слой между лабораторными evals и реальным релизом. Для frontier-моделей этого мало само по себе, но без такого слоя проверка безопасности всё больше похожа на набор отдельных тестов, а не на прогноз поведения системы в проде.
FAQ
Заменяет ли Deployment Simulation red-teaming?
Нет. OpenAI прямо называет Deployment Simulation дополнением к состязательным оценкам, red-teaming и целевому анализу редких рисков. Метод лучше подходит для достаточно частых сбоев в реалистичных контекстах, а не для редких высокорисковых сценариев.
Почему внешним аудиторам сложно повторить метод?
Нужны репрезентативные префиксы боевых диалогов, а такие данные приватны. OpenAI пробовала WildChat как публичный аналог: он дал информативные, но менее точные прогнозы, чем свежие боевые данные.
Какие риски метод не ловит?
Редкие tail-risk сценарии, новые паттерны использования после крупного релиза, ошибки из-за плохой симуляции инструментов и поведение, которое трудно обнаружить без читаемого следа рассуждений. Поэтому Deployment Simulation должен идти рядом с red-teaming, внешними аудитами и целевыми evals.
Источники и дата проверки
Факты и изображения проверены 16 июня 2026 года. Данные о GPT-5.4 Thinking, 1,3 млн диалогов, 92% точности направления, WildChat и симуляции инструментов могут уточняться в будущих системных картах и версиях исследования.