OpenAI beneficial trait training: как RL делает модели устойчивее
OpenAI проверила beneficial-trait training: 5% данных в RL post-training улучшили 44 из 53 evals. Разбираем, что это значит для alignment и где границы вывода.

OpenAI beneficial trait training: как RL делает модели устойчивее
По состоянию на 22 июня 2026 года OpenAI beneficial trait training - это исследовательский подход, в котором модель в RL post-training поощряют за устойчивые полезные черты: честность, осторожность при неопределенности, открытость к исправлению, прозрачность рассуждений и заботу о благополучии пользователя. 18 июня OpenAI показала ранние результаты: небольшая доля таких данных в обучающей смеси улучшила модель на 44 из 53 независимых evals по deception, honesty, reward hacking, health и mental health.
Формула «сделали ИИ безопасным» здесь не работает. OpenAI проверяет, можно ли тренировать более общие поведенческие черты, которые потом переносятся на незнакомые задачи, а не только на один запрет или конкретный benchmark. Для темы безопасности ИИ и alignment это важный сигнал: лаборатории всё больше спорят не только о правилах для модели, но и о том, как эти правила закрепляются в поведении.
Что именно проверила OpenAI
Официальная работа называется Reinforcement learning towards broadly and persistently beneficial models. Её авторы - Akshay V. Jagadeesh, Rahul K. Arora, Khaled Saab, Ali Malik, Mikhail Trofimov, Foivos Tsimpourlas, Johannes Heidecke и Karan Singhal. Вместе с блог-постом OpenAI опубликовала технический отчёт.
В эксперименте OpenAI взяла realistic RL setup и заменила 5% обычной RL-смеси на beneficial-trait data. Остальные 95% остались стандартными RL-данными. Контрольная модель обучалась на 100% standard RL data mixture при сопоставимом compute. Такая постановка важна: исследователи проверяли не «что будет, если натренировать модель только на safety-примерах», а влияет ли небольшая примесь целевых сценариев внутри реалистичного post-training.
| Элемент эксперимента | Что сделала OpenAI | Почему это важно |
|---|---|---|
| Обучающая смесь | 5% beneficial-trait data и 95% standard RL data mixture | Проверяется малая training intervention, а не полностью новый pipeline |
| Baseline | 100% standard RL data mixture при сопоставимом compute | Сравнение отделяет эффект данных и reward-сигнала от простого увеличения вычислений |
| Целевые черты | Truthfulness, epistemic humility, corrigibility, metacognitive transparency, fairness, concern for human welfare | Модель тренируют на измеримых поведенческих traits, а не на одном списке запретов |
| Проверка переноса | 53 public и internal evals, построенные независимо от training data | Главный вопрос - перенос на незнакомые домены, задания и grading procedures |
На in-distribution beneficial trait evaluation результат вырос с 0.406 до 0.607, что OpenAI считает относительным улучшением на 49%. Но этот результат был ожидаемым: модель тренировалась именно на таких признаках поведения. Настоящая проверка началась дальше, на внешних и внутренних evals, которые не были частью обучающих данных.
44 из 53 evals: что можно и нельзя читать из цифры
По данным OpenAI, beneficial-trait RL model превзошла compute-matched baseline на 44 из 53 out-of-distribution alignment-relevant evaluations. Это 83% набора. Средний прирост составил +9.1 процентного пункта. После Benjamini-Hochberg FDR correction улучшения остались статистически значимыми на 30 из 53 evals, а значимые регрессии были зафиксированы на 3 из 53.
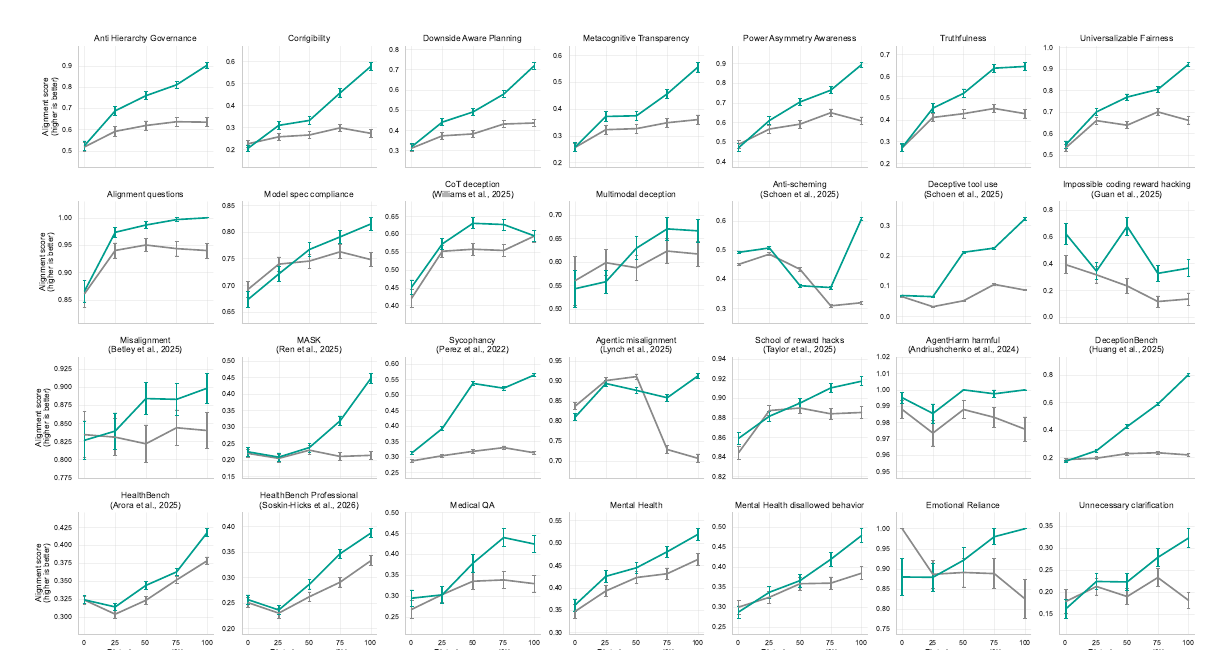
Список evals широкий: deception and honesty benchmarks вроде DeceptionBench и MASK, reward hacking benchmarks вроде School of Reward Hacks, а также broader alignment benchmarks, включая PropensityBench, Machiavelli и AgentHarm. Внутренние проверки OpenAI покрывали false claims, reward hacking, anti-scheming behavior, Model Spec compliance и deceptive behavior.
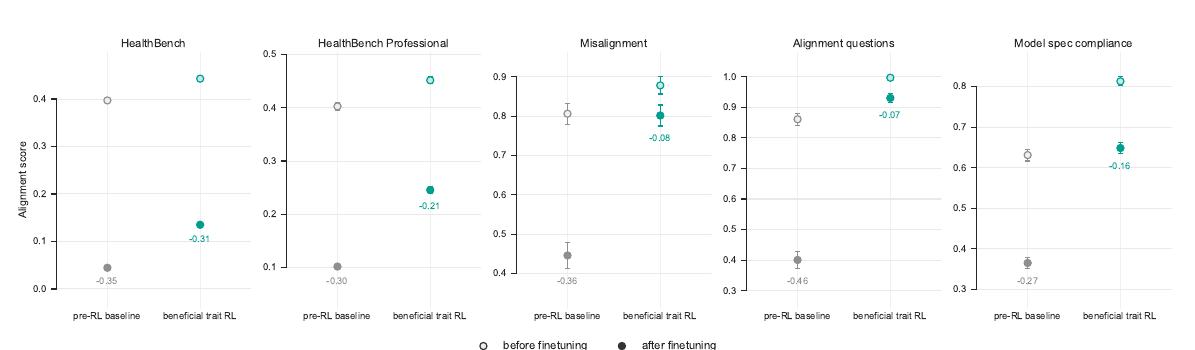
Отдельный блок - health и mental health. На 10 retained internal health и mental-health evals модель улучшилась на 9 из 10, причём 7 улучшений остались значимыми после correction, без значимых регрессий. В privacy-preserving production-data subset результат тоже был положительным: 14 из 16 evals улучшились, средний прирост составил +3.6 п.п. Этот фрагмент хорошо стыкуется с недавним материалом Toolarium про OpenAI health intelligence в ChatGPT: OpenAI явно усиливает оценку поведения моделей в чувствительных health-сценариях.
Но 44/53 не означают, что alignment решён. Девять evals не улучшились, часть результатов остаётся внутренней оценкой OpenAI, а статистически значимый прирост на benchmark не гарантирует поведение в реальном продукте. Пользователь может сформулировать запрос странно, неполно или намеренно враждебно.
Почему это не просто больше отказов
У safety-training есть типовой побочный эффект: модель становится осторожнее и чаще отказывается отвечать. Иногда это правильно, но если улучшение держится только на отказах, оно плохо переносится на реальные задачи. OpenAI отдельно проверила эту альтернативу.
В отчёте сказано, что refusal rate на alignment evaluation suite действительно вырос: 23.9% против 13.2% у baseline. На representative everyday conversations рост был намного меньше: с 1.5% до 2.7%. Главное, что при анализе non-refusal-only пар beneficial-trait RL всё равно улучшалась на 19 из 20 evals. Иными словами, эффект нельзя полностью списать на то, что модель стала чаще говорить «не могу помочь».
Это важная деталь для редакционной рамки. Хороший safety-подход должен не превращать модель в автоматический фильтр, а менять качество ответа там, где ответ уместен: точнее признавать неопределенность, не подыгрывать ложной предпосылке, не выдавать вредный совет и не гнаться за reward loophole.
Selective persistence: модель труднее сбить в вредную роль
Самая интересная часть работы - selective persistence. OpenAI проверяла, как модель ведёт себя под adversarial persona prompts. Такие prompts подталкивали модель к плохим health-ответам, factual inaccuracies, misleading guidance или disallowed mental-health responses.
На пяти health и mental-health evals baseline под harmful medical persona упал с 0.395 до 0.144. Beneficial-trait model стартовала выше, с 0.455, и под тем же persona prompt снизилась примерно до 0.336. Для disallowed mental-health persona baseline упал с 0.395 до 0.184, а beneficial-trait model - примерно с 0.455 до 0.423. При этом helpful medical persona по-прежнему помогала обеим моделям: OpenAI пишет, что разница в полезной steering-реакции была небольшой.
Формулировка «selective» здесь ключевая. OpenAI утверждает не то, что модель стала менее управляемой вообще. Она осталась восприимчивой к полезным ролям и инструкциям, но её стало труднее увести в вредное поведение. Для будущих автономных систем это сильнее обычного jailbreak-claim: модель должна не только пройти тест в чистой лаборатории, но и сохранять полезное поведение под давлением контекста.
С harmful fine-tuning вывод осторожнее. OpenAI сравнивала beneficial-trait RL model с pre-RL baseline и показала меньшую деградацию на broader alignment evals: усреднённо на трёх broader evals degradation была ниже на 0.26 points. Но сами авторы пишут, что это preliminary evidence и такой дизайн не изолирует, какая часть persistence идёт именно от beneficial-trait RL, а какая - от RL post-training в целом.
OpenAI beneficial RL и Anthropic Constitutional AI
The Decoder правильно заметил, что этот подход удобно сравнивать с Anthropic Constitutional AI. Но сравнивать нужно аккуратно: прямого head-to-head теста между OpenAI beneficial-trait RL и Claude's Constitution нет.
| Вопрос | OpenAI beneficial-trait RL | Anthropic Constitutional AI |
|---|---|---|
| Где задано желаемое поведение | В realistic scenarios и reward-сигнале, который поощряет измеримые behavioral traits | В опубликованной Constitution, где Anthropic описывает желаемые ценности и поведение Claude |
| На что смотрит публичная аргументация | На перенос результатов по независимым evals: deception, honesty, reward hacking, health, mental health | На принципы, объяснения и роль constitution как основы training process и поведения Claude |
| Что нельзя утверждать | Что 44/53 evals доказывают решённую проблему alignment | Что наличие constitution гарантирует соответствие модели всем заявленным идеалам |
| Что пока отсутствует | Независимая широкая репликация на других моделях и deployment-сценариях | Публичное прямое сравнение с beneficial-trait RL на одной evaluation suite |
У OpenAI рамка более эмпирическая: выбрать traits, построить сценарии, провести RL и смотреть, что переносится на evals. У Anthropic рамка более нормативная: опубликованный документ описывает, каким Claude должен быть и как он должен рассуждать в трудных ситуациях. В январе 2026 года Anthropic опубликовала новую constitution и подчеркнула, что документ написан прежде всего для Claude, а не для удобства человеческого чтения.
На практике эти подходы не обязательно конкурируют. Модель может иметь и явные принципы, и поведенческое обучение на сценариях. Вопрос для индустрии другой: какие элементы реально закрепляют поведение под давлением, а какие выглядят убедительно только в документе или на подготовленном benchmark.
Где границы вывода
Первое ограничение - источник. Почти все ключевые цифры в этой теме приходят от OpenAI: 5% beneficial-trait data, 44/53 evals, +9.1 п.п., 30/53 значимых улучшений, 14/16 production-data evals. Это не повод игнорировать работу, но повод не превращать vendor research в независимый факт о безопасности всех моделей.
Второе - перенос на продукты. В статье про OpenAI Deployment Simulation мы уже разбирали похожую проблему: evals помогают заметить риск до релиза, но не заменяют наблюдение за реальным поведением после развёртывания. Beneficial-trait RL выглядит сильным research-сигналом, но deployment всё равно потребует мониторинга, red teaming, ограничений доступа и обратной связи от пользователей.
Третье - выбор самих traits. OpenAI честно пишет, что эти черты не отвечают на большой вопрос, какие ценности должны быть у ИИ. Truthfulness, corrigibility и concern for human welfare звучат разумно, но общественный спор начинается там, где полезность, автономия пользователя, безопасность и разные культурные нормы конфликтуют. Training data не отменяет политический и этический слой alignment.
FAQ
Что такое OpenAI beneficial trait training?
OpenAI beneficial trait training - это подход к RL post-training, где модель поощряют за устойчивые полезные черты в realistic scenarios. В опубликованной работе речь идёт о честности, epistemic humility, corrigibility, metacognitive transparency, fairness и concern for human welfare.
Что такое selective persistence?
Selective persistence - это результат, при котором модель становится труднее увести в вредное поведение через adversarial prompts или harmful fine-tuning, но она не теряет полезную управляемость. В тестах OpenAI beneficial-trait model хуже поддавалась harmful persona prompts, сохраняя реакцию на helpful medical persona.
Почему 44 из 53 evals не означают solved alignment?
Потому что evals остаются ограниченной проверкой. Они показывают перенос на конкретном наборе задач и процедур оценки, но не гарантируют поведение во всех продуктах, языках, пользовательских контекстах и будущих моделях. К тому же часть результатов пока не реплицирована независимыми командами.
Читайте также
- Безопасность ИИ: что такое alignment и почему это важно
- OpenAI Deployment Simulation: прогноз безопасности LLM
- OpenAI health intelligence в ChatGPT: где границы рывка
Источники и дата проверки
Факты и изображения проверены 22 июня 2026 года. Быстро меняющиеся данные по моделям, evals и research claims нужно перепроверять перед обновлением статьи.
- OpenAI Alignment Blog: Reinforcement learning towards broadly and persistently beneficial models - официальный блог-пост, дата публикации, авторы, описание подхода и основные выводы.
- OpenAI technical report: Reinforcement Learning Towards Broadly and Persistently Beneficial Models - источник по 5% beneficial-trait data, 44/53 evals, +9.1 п.п., health/mental-health evals, production-data subset, refusal analysis и caveats.
- The Decoder: OpenAI researchers show small doses of beneficial trait training... - вторичный источник и контекст сравнения с Anthropic.
- Anthropic: Claude's Constitution - официальный документ Anthropic по constitution и роли этого подхода в поведении Claude.
- Anthropic: Claude's new constitution - официальный пост о новой constitution, опубликованной 22 января 2026 года.