Open-source реестры пакетов перегружены: кто платит за AI и CI/CD
Open-source реестры пакетов стали критической инфраструктурой, но AI, CI/CD и машинный трафик перегружают их быстрее, чем меняется модель поддержки.

По состоянию на 12 мая 2026 года разговор о реестрах пакетов уже нельзя сводить к удобству разработчика. Maven Central, PyPI, npm, NuGet и соседние экосистемы давно стали базовой инфраструктурой мировой цепочки поставки ПО. Проблема в другом: компании до сих пор потребляют эту инфраструктуру так, будто она бесплатна, бесконечна и не требует никакой операционной поддержки.
Свежие источники сходятся в одной точке. OpenSSF пишет, что в 2026 году публичные реестры обслужат более 10 триллионов загрузок open-source пакетов. Sonatype оценивает уже прошедший 2025 год в 9,8 триллиона загрузок только по четырём крупным экосистемам: Maven Central, PyPI, npm и NuGet. На этом фоне AI-агенты, CI/CD, сканеры зависимостей, одноразовые сборки и облачные пайплайны перестают быть нейтральной автоматизацией. Они становятся главной формой потребления инфраструктуры реестров.
Для технаря здесь важен не только масштаб, но и вывод. История не про то, что «ИИ всё сломал». История про то, что машинный трафик уже растёт быстрее старой модели эксплуатации и финансирования. И если этот разрыв не закрывать, узким местом становятся не отдельные библиотеки, а сама инфраструктура, на которой держатся сборки, обновления, проверки зависимостей и реакция на supply-chain инциденты.
Реестры пакетов уже работают как критическая инфраструктура
Ещё несколько лет назад публичный реестр можно было воспринимать как удобный фон. Разработчик запускает сборку, менеджер зависимостей тянет нужный пакет, всё работает. В 2026 году это описание устарело. OpenSSF прямо называет package registries foundational digital infrastructure не только для open source, но и для глобальной цепочки поставки ПО. Это точная формулировка: без этих сервисов не едет не только небольшой проект, но и коммерческая разработка в облаках, корпоративных пайплайнах и SaaS-платформах.
Отсюда меняется и цена ошибки. Registry сегодня отвечает не только за раздачу архивов. Он держит аутентификацию и права издателей, реагирует на malware, разруливает споры по namespace, поддерживает зеркала, кэши, поиск, индексацию, аудит, сигналы доверия и расследование инцидентов. OpenSSF отдельно напоминает, что всё это в большинстве экосистем до сих пор держится на инфраструктурных пожертвованиях, грантах и небольших оплачиваемых командах вперемешку с волонтёрским трудом.
Именно поэтому разговор о registries всё чаще уходит из эстетики «open source сам разберётся» в экономику и эксплуатацию. Вопрос уже не в том, нужны ли такие сервисы. Вопрос в том, кто должен платить за их масштаб, отказоустойчивость и безопасность, если основную выгоду из них извлекают крупные коммерческие пользователи.
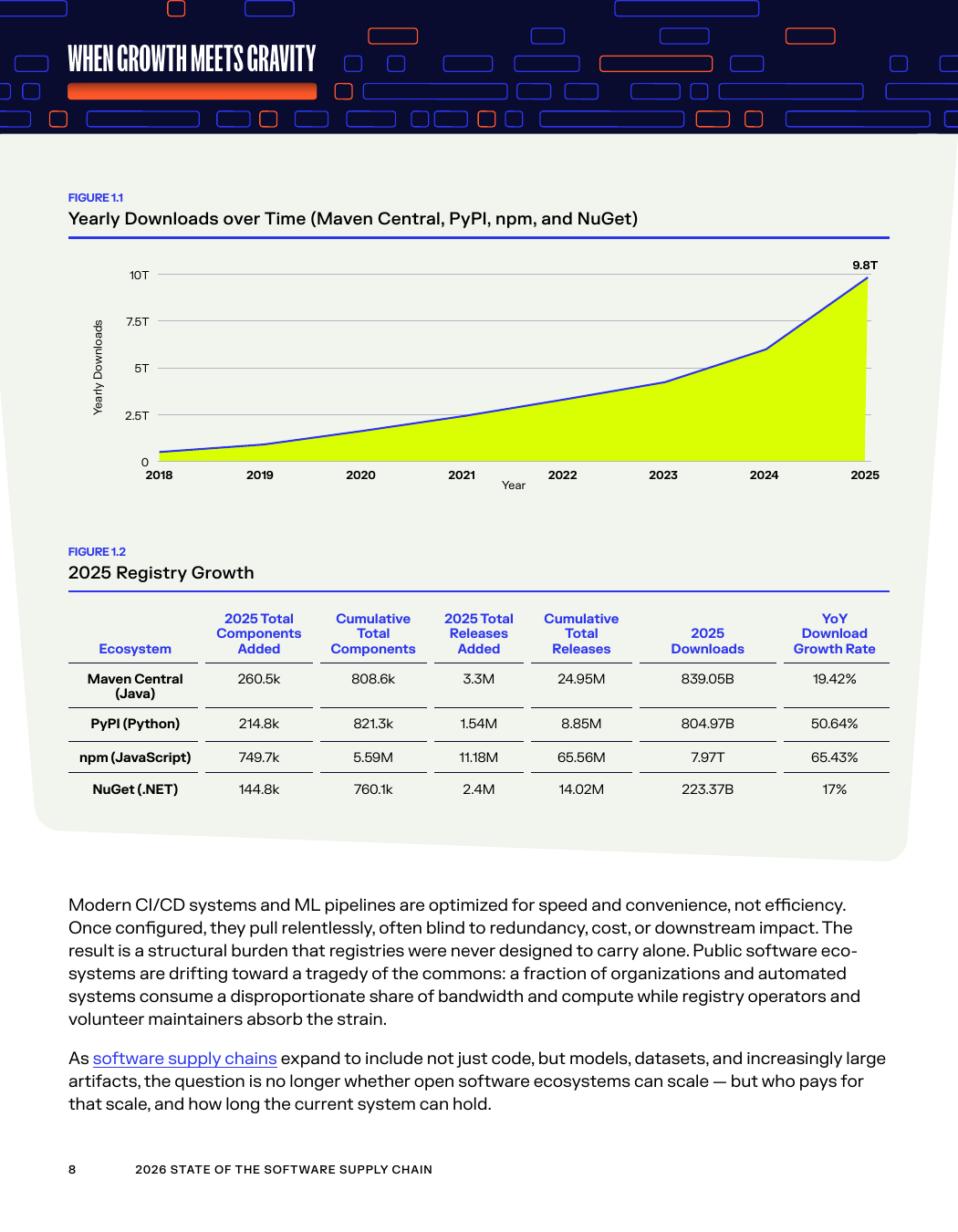
Масштаб нагрузки уже измеряется триллионами
Лучше всего реальную картину сейчас показывает Sonatype. В отчёте 2026 State of the Software Supply Chain компания фиксирует 9,8 триллиона загрузок за 2025 год по четырём крупным экосистемам. Это не абстрактная цифра для красивого заголовка. За ней стоит вполне приземлённая история: почти каждая современная сборка тянет не десятки, а сотни зависимостей, а поверх одной языковой экосистемы часто лежат другие.
| Экосистема | Загрузки в 2025 году | Рост год к году | Что это значит |
|---|---|---|---|
| Maven Central | 839,05 млрд | 19,42% | Java остаётся базовым корпоративным контуром, где даже умеренный рост даёт огромную абсолютную нагрузку. |
| PyPI | 804,97 млрд | 50,64% | Python сильнее других отражает всплеск AI- и облачных нагрузок. |
| npm | 7,97 трлн | 65,43% | JavaScript остаётся самым тяжёлым по числу запросов публичным контуром реестров. |
| NuGet | 223,37 млрд | 17% | .NET растёт спокойнее, но тоже работает на инфраструктурных объёмах. |
OpenSSF поверх этого даёт следующий ориентир: в 2026 году совокупный объём публичных реестров превысит 10 триллионов загрузок. Это больше миллиарда загрузок в час. И здесь важно не само число, а тип нагрузки. Большую часть трафика создают не люди, которые вручную ставят пакет на ноутбук, а автоматические системы, которые многократно повторяют одни и те же операции в сборках, проверках и развёртывании.
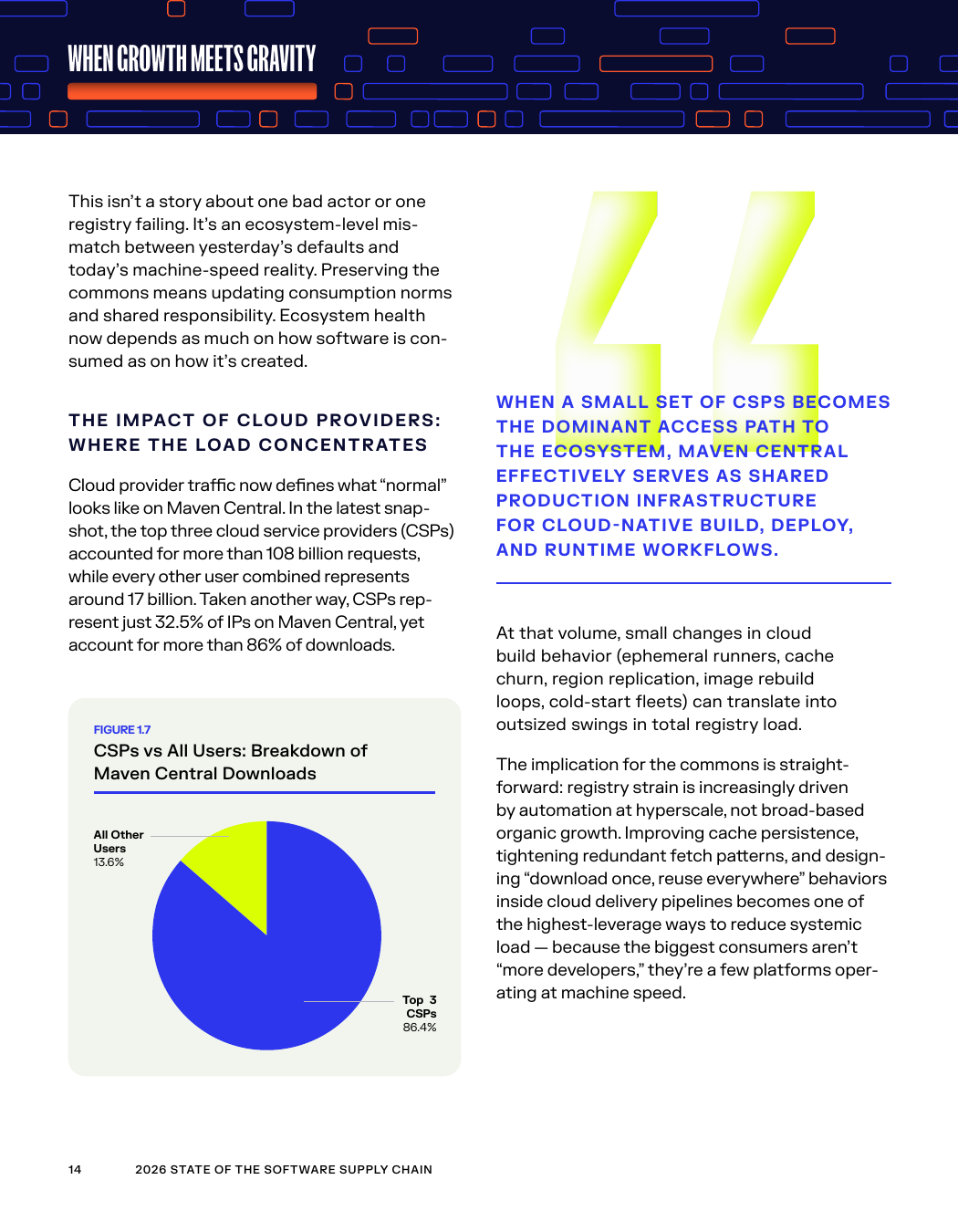
Главный источник давления — машинный трафик, а не рост числа разработчиков
Самый неприятный вывод Sonatype касается не суммы запросов, а их структуры. В 2025 году три крупнейших облачных провайдера дали более 108 миллиардов запросов к Maven Central. Все остальные пользователи вместе — около 17 миллиардов. При этом на top-3 CSP приходится только 32,5% IP-адресов Maven Central, но более 86% загрузок. Это уже не картина «миллионы независимых разработчиков что-то качают». Это история про концентрированное машинное потребление внутри больших облачных и корпоративных контуров.
Раньше Sonatype пыталась ограничивать перегрузку на уровне отдельных IP. Но этого стало мало. Ещё в 2024 году компания писала, что 83% всей пропускной нагрузки Maven Central приходятся всего на 1% IP-адресов. В 2025 году ситуация сместилась дальше: целые организации начали скачивать одни и те же компоненты более полумиллиона раз в месяц и не для пары библиотек, а для тысяч артефактов. Если такой трафик распределён по сотням или тысячам IP, простое ограничение по IP уже почти бесполезно.
Почему это происходит, тоже не секрет. Sonatype прямо указывает на знакомые паттерны: одноразовые сборки, постоянное выбивание кэша, репликация по регионам, пересборки образов, холодные старты и параллельные CI/CD-пайплайны. Иными словами, реестр пакетов часто страдает не от одного злого потребителя, а от настроек по умолчанию, которые в масштабе превращают нормальную сборку в нескончаемый поток лишних скачиваний.
ИИ здесь не главный виновник, но сильный ускоритель
Самая удобная ошибка в этой теме — назначить AI единственной причиной перегрузки. Источники так не говорят. OpenSSF и Sonatype описывают ИИ как усилитель уже существующей машинной нагрузки. Это важная разница. CI/CD, сканеры зависимостей и облачные сборки нагружали реестры и без генеративных моделей. Но AI добавляет сразу несколько новых контуров: больше Python-пакетов, больше автоматических окружений, больше агентных сценариев и больше кода, который сам генерирует код и зависимости.
OpenSSF в майском разборе пишет прямо: распространение AI coding agents and tools уже усиливает давление на package registries. В том же тексте есть показательная деталь по PyPI: в 2025 году индекс добавил 130 тысяч новых пакетов, почти догнав уровень 2018 года, а в 2026-м прибавляет уже около 900 пакетов в день. Это не доказательство, что весь рост идёт только от ИИ. Но это хороший индикатор того, как быстро растут производство и потребление зависимостей.
Есть и менее очевидный слой. В главе про AI agents Sonatype пишет, что 27,76% рекомендаций по обновлению зависимостей ссылались на несуществующие версии. Для читателя это важно не как анекдот про галлюцинации, а как инфраструктурный риск. Если агент не привязан к живому состоянию реестра, он не только делает лишнюю работу, но и создаёт бессмысленный трафик, неверные действия с пакетами и ложные обновления, которые потом кто-то должен разбирать.
OpenSSF добавляет ещё одну неприятную деталь: реестры теперь стоят на переднем крае безопасности цепочки поставки, а злоумышленники тоже используют ИИ. Чем выше скорость публикации, пересборки, проверки и атаки, тем больше на операторов ложится работы по разбору вредоносных пакетов, реагированию и применению правил.
Это уже вопрос безопасности, а не только счёта за CDN
В феврале 2026 года OpenSSF собрала Package Manager Security Forum, и там проблема прозвучала ещё жёстче. Участники из разных экосистем зафиксировали общую картину: управление и борьба со злоупотреблениями находятся под всё большим давлением, а устойчивость реестров больше нельзя отделять от их безопасности. Если у оператора не хватает ресурсов на реагирование, аудит, восстановление аккаунтов, применение правил и разбор вредоносных пакетов, это быстро бьёт по всей цепочке поставки.
С практической точки зрения это легко увидеть на соседних кейсах. Когда через PyPI прошёл вредоносный релиз LiteLLM, удар пришёлся не по одному пакету, а по рабочим окружениям, токенам и CI-контурам вокруг него. Мы разбирали это в материале о взломе LiteLLM на PyPI. Похожая логика была и в истории с компрометацией Bitwarden CLI на npm: реестр стал каналом доставки вредоносного инструмента в среду разработчика. А разбор GitHub RCE через git push показывает другой край той же цепочки — как ломается доверенный pipeline, когда инфраструктурные допущения перестают выдерживать реальную нагрузку и сложность.
Поэтому спор «это экономическая проблема или security-проблема» уже не очень полезен. Реестр, который не успевает обрабатывать злоупотребления, уязвимости и всплески машинного трафика, перестаёт быть только бухгалтерской головной болью. Он становится операционным риском для всей цепочки поставки ПО.
Что должны сделать компании, которые живут на публичных реестрах
Самый простой неправильный ответ — ждать, что операторы всё как-нибудь починят сами. Источники как раз показывают обратное: старая модель, где небольшая группа стюардов молча тянет глобальную инфраструктуру на пожертвованиях и грантах, уже не соответствует масштабу коммерческого потребления.
- Ставить repository manager с кэширующим прокси. Sonatype повторяет этот совет уже не как nice-to-have, а как базовую гигиену. Кэш снижает нагрузку на реестр и одновременно ускоряет собственные сборки.
- Разбирать CI/CD на предмет лишнего повторного разрешения зависимостей и повторных скачиваний. Если одноразовые раннеры и контейнерные сборки снова и снова качают один и тот же артефакт, это уже архитектурный дефект, а не «цена облака».
- Перестать использовать публичные реестры как бесплатный CDN для проприетарных SDK и бинарей. OpenSSF прямо пишет, что такой сценарий стал обычным, хотя платит за него не потребитель, а общий ресурс.
- Привязывать AI-агентов и AI-помощников к живому состоянию реестра. Версия пакета должна проверяться по реальному индексу, а не по памяти модели или по красивой подсказке.
- Готовиться платить за устойчивость. Формат может быть разным: управляемые сервисы, платные уровни, поддержка фондов, коммерческие предложения от операторов. Но логика уже ясна: если крупный бизнес опирается на эти сервисы как на критическую инфраструктуру, он не может вечно делать вид, что это бесплатный общественный воздух.
Главный вывод
Open-source реестры пакетов сегодня находятся в неудобной точке. Для всей индустрии это уже критическая инфраструктура. По модели поддержки — всё ещё смесь грантов, доброй воли и маленьких команд. AI, CI/CD и машинный трафик не создали этот конфликт с нуля, но резко ускорили его.
Поэтому главный вопрос 2026 года звучит не так: «выдержат ли реестры ещё один всплеск загрузок». Более полезный вопрос другой: готовы ли компании перестроить собственное потребление и наконец начать платить за инфраструктуру, без которой не работают их сборки, сканеры, обновления и агентные контуры. Пока ответ на этот вопрос расплывчатый, перегрузка реестров будет повторяться.
Источники и дата проверки
- OpenSSF: Open Infrastructure Is Not Free, Part II, опубликовано 6 мая 2026 года, проверено 12 мая 2026 года.
- OpenSSF: Open Infrastructure is Not Free: A Joint Statement on Sustainable Stewardship, опубликовано 23 сентября 2025 года, обновлено 4 мая 2026 года, проверено 12 мая 2026 года.
- Sonatype: 2026 State of the Software Supply Chain Report — Software Infrastructure Strain, проверено 12 мая 2026 года.
- Sonatype: Maven Central and the Tragedy of the Commons, опубликовано 26 июня 2024 года, проверено 12 мая 2026 года.
- Sonatype: Addressing Organizational Overconsumption in Maven Central, опубликовано 10 июня 2025 года, проверено 12 мая 2026 года.
- OpenSSF: Advancing Package Repository Security Through Collaboration, опубликовано 19 февраля 2026 года, проверено 12 мая 2026 года.
- FOSDEM 2026: The terrible economics of package registries and how to fix them, проверено 12 мая 2026 года.