ИИ для анализа данных в Python: где LLM реально ускоряют работу
ИИ для анализа данных в Python полезен не как «автоматический аналитик», а как ускоритель EDA, pandas-кода, SQL-черновиков и визуализации. Разбираем, какой стек выбрать и где без ручной валидации нельзя.
Проверено 6 мая 2026 года. ИИ в Python-аналитике полезен не там, где обещают «автоматический data science», а там, где снимает самые дорогие рутинные шаги: первый проход по EDA, черновой pandas-код, SQL, графики и объяснение уже полученных результатов. Как только речь идёт о статистических выводах, причинности, утечке признаков или проверке бизнес-гипотез, LLM должны оставаться вторым пилотом, а не автопилотом.
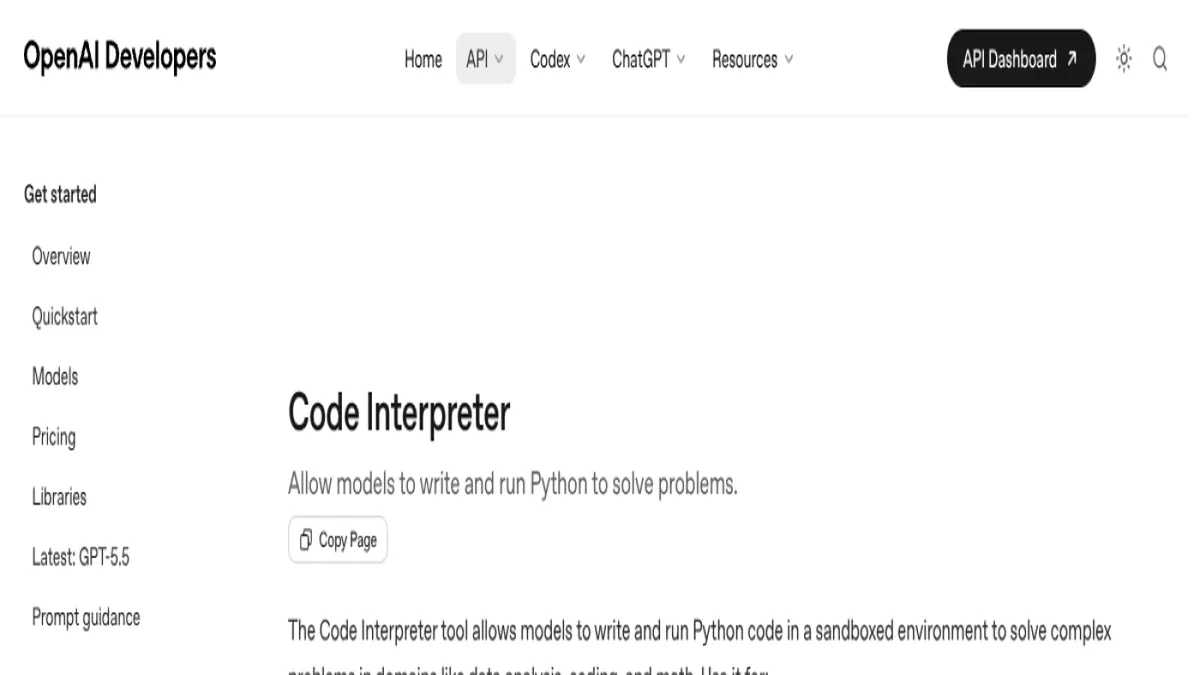
Это уже видно по тому, как устроены официальные инструменты. В актуальной справке OpenAI сказано, что ChatGPT умеет строить таблицы и графики, выполнять Python-based calculations в stateful Jupyter notebook environment и показывать сгенерированный код, результаты и assumptions для проверки. Jupyter AI умеет отвечать по активному ноутбуку, создавать и редактировать ноутбуки и запускать кодовые ячейки через ядро. PandasAI переводит запросы на естественном языке в Python-код и SQL поверх датафреймов. Все три сценария полезны, но только если заранее понятно, что именно вы отдаёте модели, а что оставляете себе.
Если вам нужен более широкий контекст по инженерному стеку, держите рядом карту ИИ для разработчиков. Если задача ближе к автоматизации вокруг таблиц и отчётов, полезно сразу посмотреть и практический маршрут GPT в Google Sheets, чтобы не смешивать Python-first и spreadsheet-first сценарии.
Ниже — Python-first гайд для аналитика или разработчика: где LLM реально ускоряют EDA и работу с pandas, какой стек выбрать под задачу и где без ручной валидации нельзя.
Где ИИ реально ускоряет анализ данных в Python
На практике LLM лучше всего работают не как «аналитик целиком», а как ускоритель первого прохода. Они быстро собирают boilerplate, подсказывают EDA-чеклист, пишут стандартные преобразования и помогают превратить вопрос бизнеса в исполнимый код. А вот ответственность за корректность агрегации, за статистическую интерпретацию и за итоговое решение остаётся у человека.
| Этап | Что можно отдать ИИ | Что нужно проверить руками |
|---|---|---|
| Первичный осмотр данных | Черновой EDA-чеклист, df.info(), nulls, дубликаты, кандидаты на выбросы | Бизнес-смысл полей, утечки таргета, корректность типов и временных полей |
| Очистка и преобразование | Шаблонный pandas-код, регулярки, joins, группировки, нормализация названий | Число строк до и после merge, type coercion, случайные потери записей |
| SQL и feature prep | Черновики SQL, groupby, идеи для признаков, преобразование дат | Окна агрегации, leakage, корректность denominator и grain |
| Визуализация | Код для Matplotlib/Seaborn, выбор базового типа графика, аннотации | Шкалы, binning, скрытые выбросы, ложная визуальная драматизация |
| Объяснение результатов | Черновой текст для ноутбука, сводка наблюдений, варианты формулировок | Причинные выводы, статистическая значимость, решение для бизнеса |
Рабочая рамка здесь простая: ИИ хорошо закрывает черновой код и черновое объяснение, но плохо заменяет аналитическое суждение. Если модель сама предложила фичу, сама посчитала метрику и сама же объявила её значимой, это не ускорение анализа, а ускорение самообмана.
Три рабочих стека для Python-first сценария
Условно весь рынок сейчас раскладывается на три удобных сценария. Они не взаимоисключающие: зрелая команда часто использует два или даже все три, но для разных этапов работы.
1. Быстрый прототип через чат: ChatGPT / Code Interpreter
Этот режим хорош, когда нужно быстро понять структуру файла, попросить модель собрать первый график или объяснить, что происходит в CSV/XLSX. В OpenAI Help прямо сказано, что ChatGPT помогает строить таблицы и графики, выполнять Python-based calculations и показывает сгенерированный код, результаты и assumptions. Там же уточняется, что для части data-analysis задач используется stateful Jupyter notebook environment, а pandas DataFrames могут отображаться как интерактивные таблицы. Это важный практический плюс: анализ не обязан оставаться в чате, шаги можно перепроверить и затем перенести в ноутбук или кодовую базу.
Если нужен уже не чатовый режим, а автоматизируемый API-контур, у OpenAI есть инструмент Code Interpreter. В актуальной документации указано, что он может создавать собственные файлы внутри контейнера — например, графики и CSV — и автоматически работать с файлами, переданными на вход. Для Python-аналитики это удобно там, где нужен сервисный шаг «загрузить данные → посчитать → вернуть артефакт».
2. Сценарий через ноутбук: Jupyter AI
Если основная работа живёт в ноутбуке, Jupyter AI выглядит естественнее. В user guide прямо перечислено, что AI personas могут отвечать по активному ноутбуку или активной ячейке, создавать и редактировать ноутбуки, запускать код через ядро и открывать другие файлы в JupyterLab. Это уже не просто «чат рядом с кодом», а инструмент, который понимает контекст текущего анализа.
Здесь сильнее всего выигрывают два сценария. Первый: вы просите модель переписать кусок кода, который уже существует, а не генерировать его с нуля. Второй: вы двигаетесь от вопроса к воспроизводимому ноутбуку, а не от красивого ответа к ручному восстановлению шагов. Именно поэтому режим Jupyter обычно лучше чатового сценария там, где у команды есть требования к повторяемости и ревью кода.
3. Слой над датафреймом: PandasAI
PandasAI закрывает другой класс задач: вопросы к датафрейму на естественном языке. В официальной документации библиотека описана как слой, который переводит запросы на естественном языке в Python-код и SQL, умеет строить графики, помогает работать с пропусками и поддерживает разные коннекторы — от CSV и XLSX до PostgreSQL, BigQuery и Snowflake. Для аналитика это удобно, когда нужен быстрый разведочный проход без ручной сборки каждого запроса.
Но здесь же и главный риск. Чем удобнее вопрос в стиле «покажи среднюю выручку по регионам», тем легче забыть проверить, как именно библиотека интерпретировала определение метрики, соединения и агрегацию. Поэтому PandasAI полезен как слой ускорения, а не как замена проверяемому коду в ноутбуке или репозитории.
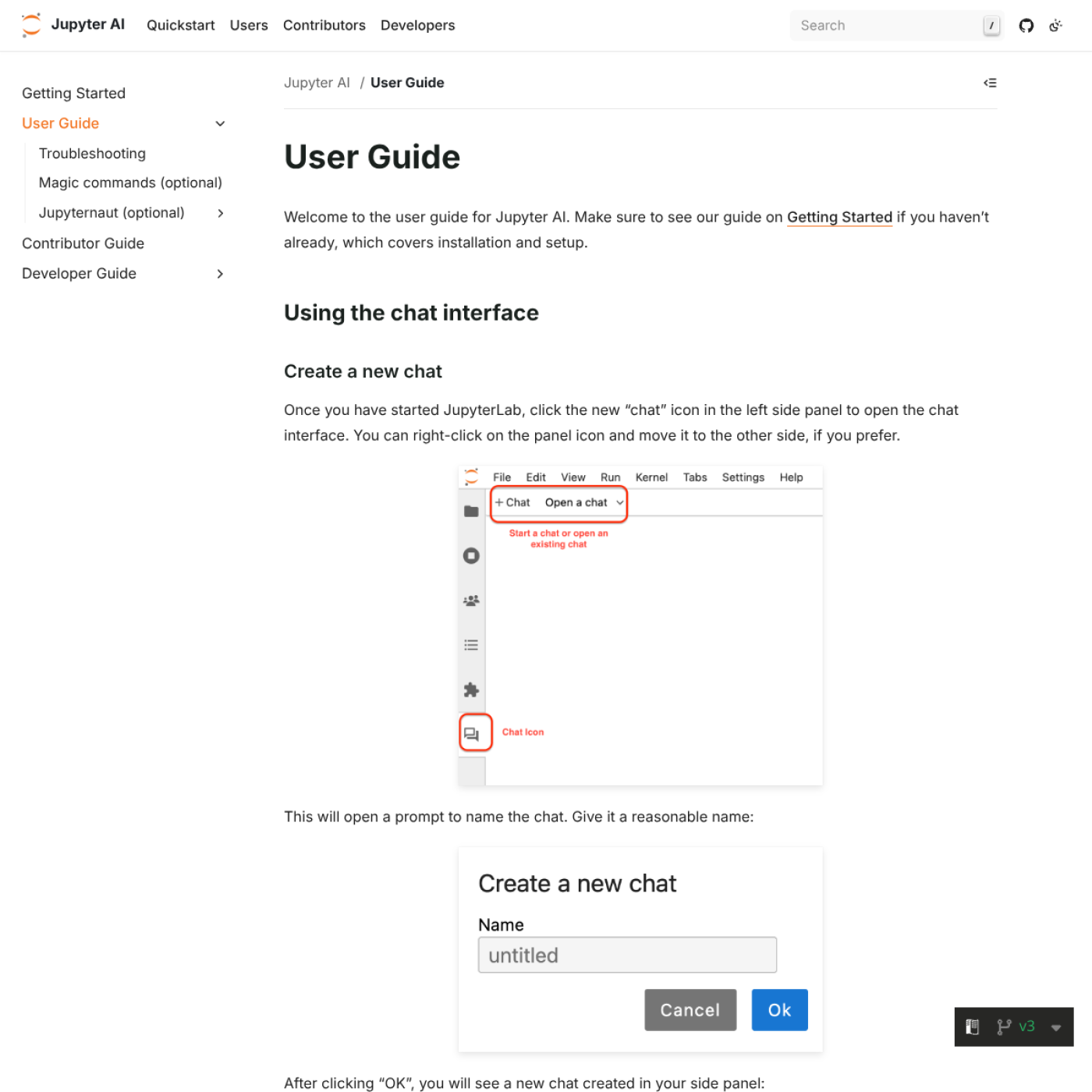
Как выглядит безопасный workflow в ноутбуке
Главная польза ИИ в Python начинается там, где у вас уже есть дисциплина анализа. Если её нет, модель просто ускорит хаос. Рабочий базовый шаблон выглядит так:
- Сначала формулируете вопрос и grain. Не «разбери данные», а «посчитай retention по когортам и проверь разницу между каналами acquisition».
- Просите у модели код или чеклист, а не вердикт. Пусть сначала предложит
pandas-шаги, SQL или графики, а не пишет «главный инсайт» до проверки расчётов. - Сразу добавляете защитные проверки.
shape, доля nulls, уникальность ключей, row counts до и после merge, sanity-check по суммам и медианам. - Сравниваете с простой baseline-версией. Например, ручной
groupby, отдельный SQL-запрос или маленький срез данных, который можно проверить глазами. - Только после этого просите текст и графики. ИИ хорошо объясняет уже подтверждённый результат, но плохо должен быть источником самого результата.
Такой workflow специально скучный. Но именно он отделяет полезного второго пилота от опасной иллюзии «LLM всё посчитает сам». Если задача затем становится повторяемой, её уже можно переносить в более стабильный автоматизированный контур. Для этого у нас есть отдельный материал про автоматизацию с LLM, но сначала гипотеза должна пережить ноутбук и ручную проверку.
Где ИИ чаще всего ломает анализ
Большинство ошибок в Python-аналитике с ИИ не выглядят как явный сбой. Они выглядят как уверенный, гладкий, но чуть неверный результат. Именно поэтому их легко пропустить.
- Неверная агрегация. Модель выбрала не тот grain, посчитала среднее вместо медианы или сложила показатели, которые нельзя суммировать.
- Тихая порча типов. Даты остались строками, денежные поля потеряли десятичную часть, категориальные значения внезапно нормализовались через слишком грубую регулярку.
- Плохой merge. После join число строк выросло или упало, но LLM не сигнализирует об этом как о проблеме.
- Утечка признаков. В признаки попало то, что в продакшне недоступно на момент предсказания, и весь последующий анализ стал красивым, но бесполезным.
- Ложная интерпретация графика. График аккуратный, но ось обрезана, binning скрывает хвост распределения, а подпись делает причинный вывод там, где есть только корреляция.
Отсюда и главное практическое правило: доверяйте ИИ как генератору гипотез и кода, но не как последнему судье результата. Это особенно важно там, где дальше идут модели из sklearn, бизнес-решения или отчёт для руководства. Красивый ноутбук с ошибкой стоит дороже, чем медленный, но проверенный код.
Когда Python уже не нужен
Не каждый вопрос к данным требует ноутбука. Если задача сводится к разовой сводке по таблице, быстрой сортировке, описанию CSV или ответу на вопрос «что произошло на прошлой неделе», иногда проще и дешевле использовать табличный ИИ-инструмент без полноценного Python-стека. Для таких сценариев полезнее наш разбор нейросетей для таблиц.
Но если вам нужна воспроизводимость, повторяемый код, нормальные проверки, версионирование ноутбуков и путь от EDA к feature engineering или модели, Python по-прежнему остаётся основным рабочим контуром. ИИ здесь не отменяет стек аналитика. Он просто ускоряет часть механики вокруг него. В более широком контексте это укладывается в тот же рабочий стек, который мы разбирали в материале про ИИ для разработчиков.
Итог
ИИ для анализа данных в Python полезен там, где есть много рутинного кода и много повторяющихся промежуточных шагов: первичный EDA, шаблонный pandas, SQL-черновики, графики и пояснения к уже подтверждённым результатам. Он плохо работает там, где нужен контроль grain, статистики, причинности и качества данных.
Если держать это разделение в голове, LLM действительно экономят время. Если нет, они просто ускоряют путь к красивой ошибке. Поэтому для Python-first сценария лучший подход в 2026 году остаётся тем же: пусть модель пишет первый черновик анализа, а аналитик остаётся владельцем расчёта и вывода.



