безопасность Китайские export controls для AI-моделей: новый риск для Европы Китай может ограничить зарубежный доступ к топовым AI-моделям. Разбираем, почему экспортный контроль смещается от чипов к API и весам.
LLM Почему SFT data filtering плохо убирает поведение LLM SFT data filtering кажется простым способом убрать нежелательное поведение LLM, но новые эксперименты показывают: черты могут переноситься через teacher model, prompt distribution и соседние сигналы в SFT-данных.
LLM Baidu Unlimited OCR: как читать десятки страниц за один проход Baidu показала Unlimited OCR: модель для длинных документов, где R-SWA держит KV-cache почти постоянным и читает десятки страниц за один проход.
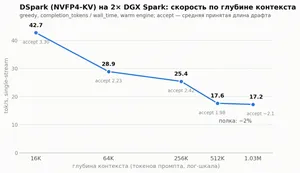
DeepSeek DeepSeek DSpark на двух DGX Spark: порт, баг и бенчмарки DeepSeek DSpark запустили на двух DGX Spark. Разбираем порт V4 Flash, sampling-slot bug, NVFP4-KV, бенчмарки и границы применимости цифр.
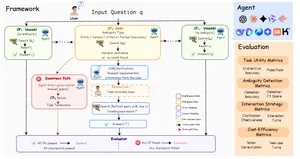
AI-агенты DiscoBench: почему AI-агенты ошибаются в поиске DiscoBench проверяет, умеют ли поисковые AI-агенты замечать неоднозначность и задавать уточняющие вопросы. Главный вывод: искать больше не значит отвечать лучше.
LLM Mistral Leanstral 1.5: Lean 4, дата-центры и fine-tuning Mistral выпустила Leanstral 1.5 для Lean 4, QTS закрыла крупный AI-дата-центр, а Bridgewater показала силу fine-tuning.
LLM GigaChat 3.5 Ultra: Сбер открыл 432B-модель с линейным вниманием Сбер открыл GigaChat 3.5 Ultra: 432B MoE-модель с гибридным вниманием, меньшим KV-cache и MTP. Разбираем, что это значит для разработчиков.