OpenAI o1 в Harvard-исследовании обошёл врачей на ER-triage
OpenAI o1 в Harvard-исследовании показал лучший результат на ER-triage. Разбираем бенчмарк clinical reasoning, цифры и почему это всё ещё не «замена врача».

По состоянию на 13 мая 2026 года история про то, что OpenAI o1 «обыграл врачей в приёмном покое», всё ещё требует расшифровки. Публикация в Science действительно показывает сильный результат модели на раннем этапе ER-triage. Но речь шла не о полноценной работе дежурной смены, а о слепо оценённых вторых мнениях по текстовым данным электронных медкарт.
В прикладной части исследования авторы сравнивали именно o1, а не старый o1-preview, вместе с GPT-4o и двумя сертифицированными врачами внутренней медицины. Затем их дифференциальные диагнозы передали двум другим врачам на слепую оценку. На первом этапе triage у o1 доля exact or very close diagnosis составила 65,8%. У двух врачей-бейзлайнов — 54,4% и 48,1%.
Есть и ещё одна важная поправка к ранним пересказам. В новостях часто мелькало число 76, но в methods опубликованной версии Science указано другое: команда случайно выбрала 80 кейсов за двухнедельный период, один случай не удалось восстановить из EHR, итоговый анализ включал 79 кейсов. Для медицинской темы это не придирка, а базовая точность.
Что именно сравнили авторы
Исследование в Boston не подсовывало модели вылизанные клинические задачи. Авторы отдельно подчёркивают, что не препроцессили данные. На этапе triage модель и врачи получали только то, что реально есть у медсестры в начале маршрута: возраст, пол, chief complaint, предположительный диагноз, triage-note, уровень срочности, способ поступления и начальные vitals. Дальше шли ещё два этапа: первая оценка врачом в ER и затем admission на medical floor или в ICU.
Важна и ещё одна деталь, которую ранние заголовки часто смазывали. Человеческий ориентир здесь — не «все emergency-room doctors вообще» и не полноценная работа у койки. Это два сертифицированных врача внутренней медицины, которые по тем же текстовым срезам EHR писали свою дифференциальную версию, ограниченную пятью диагнозами. То есть статья меряет качество текстового клинического рассуждения на фиксированных этапах, а не всю работу врача у койки.
| Диагностический этап | o1 | Врач 1 | Врач 2 |
|---|---|---|---|
| Initial ER triage | 65,8% | 54,4% | 48,1% |
| Первый ER physician encounter | 69,6% | 60,8% | 50,6% |
| Admission to hospital or ICU | 79,7% | 75,9% | 68,4% |
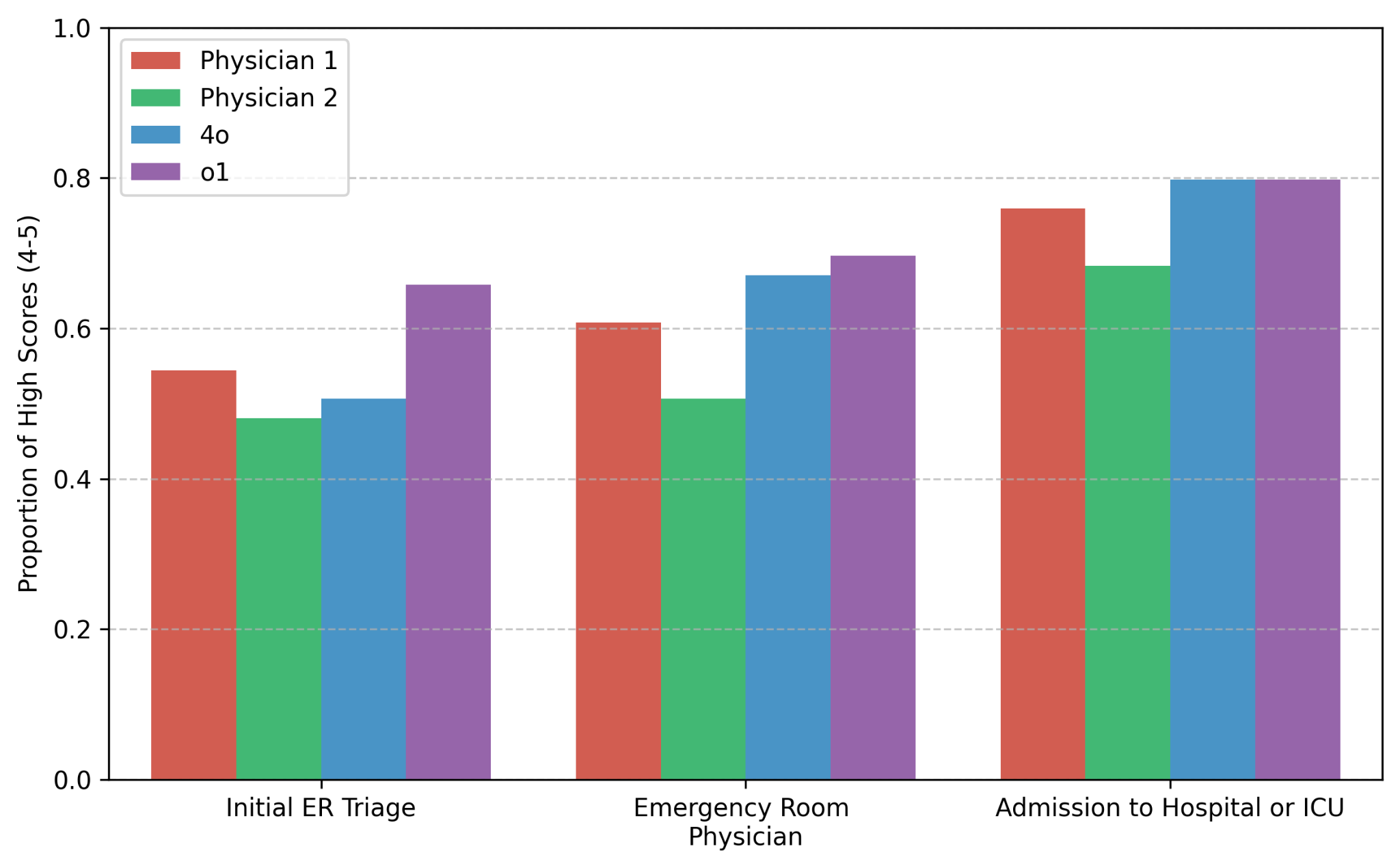
Статья также пишет, что на каждом этапе o1 был не хуже или лучше GPT-4o. Отдельный интересный сигнал: слепая оценка в целом сработала. Оценивавшие врачи в большинстве случаев вообще не могли уверенно отличить дифференциал, написанный моделью, от человеческого.
Почему эта работа шире, чем новость про triage
Именно здесь и нужно аккуратно расширить существующий материал. AAAS и авторы статьи описывают эту работу не как один красивый ER-кейс, а как одну из крупнейших сравнительных публикаций про clinical reasoning. В официальной рамке звучит более широкий тезис: модель matched or exceeded human performance across six experiments.
Тriage попало в заголовки не случайно. Это самый наглядный фрагмент работы: минимум данных, максимум срочности и заметный разрыв между участниками. Но сама статья шире. Кроме ER-среза там есть differential diagnosis generation, probabilistic reasoning и management reasoning. Если свести весь сюжет только к сортировке пациентов на входе, теряется главное: исследование проверяет не один удачный тест, а более широкий набор задач врачебного рассуждения.
Почему разрыв максимален именно на triage
Главный результат работы не в том, что модель «знает медицину лучше всех». Сильнее всего она выглядит там, где данных мало, времени мало, а решать всё равно надо сразу. Именно это авторы называют low information settings. Поэтому история так хорошо ложится на reasoning-модель вроде o1, а не на образ обычного чат-бота.
На языке клиники смысл такой: на первом этапе triage задача не в том, чтобы сразу поставить окончательный диагноз, а в том, чтобы не пропустить опасное направление и быстро собрать рабочий список версий. По мере появления новых данных лучше становились все: люди, GPT-4o и o1. Но самый широкий зазор был в начале маршрута, когда карта пациента ещё шумная, фрагментарная и местами кривая.
Это рифмуется с нашим разбором моделей рассуждения вроде o3 и DeepSeek-R1. Последние месяцы рынок показывает один и тот же сдвиг: reasoning-модели пытаются забирать не только олимпиадные задачи, но и домены, где нужно удерживать несколько гипотез при нехватке данных. Медицина — один из самых жёстких тестов для такой претензии.
Почему это всё ещё не «AI-доктор»
Именно здесь начинается часть, которую нельзя срезать ради громкого H1. Авторы статьи прямо пишут, что их ER-эксперимент — проверка концепции для второго мнения на заранее заданных этапах. Они отдельно оговаривают: реальные решения в emergency department часто крутятся вокруг triage, disposition и immediate management, а не только вокруг точности дифференциального диагноза.
Ограничения у этой работы жёсткие. Исследование смотрит только на text-based reasoning. В реальном приёмном покое врач считывает не только запись в EHR, но и внешний вид пациента, дыхание, темп речи, боль, тревожность и реакцию семьи. Кейсы взяты из одного бостонского центра и из поднабора пациентов, которых потом госпитализировали в general medicine service или MICU. Статья не отвечает на вопрос ответственности, если модель уверенно ошиблась. И даже при хорошем top diagnosis модель может подтолкнуть к лишним тестам или неверной тактике.
Это созвучно и нашему разбору LLM в психотических диалогах: сильный результат на одной узкой задаче сам по себе ничего не говорит о безопасном поведении в чувствительном домене. В медицине дистанция между «хорошо ответил» и «можно внедрять» особенно дорогая.
Независимые реакции после выхода статьи подчёркивают ту же границу. Science Media Centre отдельно напомнил: работа меряет именно слепо оцениваемую генерацию дифференциального диагноза как второго мнения, а не управление пациентом в реальном времени. Там же прозвучала и более техническая оговорка: ретроспективный дизайн всё равно не снимает вопрос prospective validation и не позволяет окончательно закрыть дискуссию о contamination или data leakage. Через несколько дней Adam Rodman в разговоре с Harvard Gazette держал ту же линию: у потребительских чат-ботов нет права трактовать такие результаты как зелёный свет для высокорисковых медицинских советов.
Как читать это рядом с JAMA
У новости есть ещё один полезный контекст. За две с половиной недели до этой публикации, 13 апреля 2026 года, JAMA Network Open выпустил большой тест 21 frontier-модели на 29 клинических виньетках. Там картина была менее праздничной: reasoning-optimized модели действительно выглядели лучше, но differential diagnosis оставался самым слабым этапом. В строгой метрике полного совпадения доля провалов на этом шаге у всех моделей превышала 0,80.
На первый взгляд это противоречие. На деле — нет. JAMA тестировал готовые модели на стандартизированных клинических виньетках, а Harvard/Beth Israel смотрели на вторые мнения по реальным, сырым EHR-срезам и оценивали качество differential через physician Bond score. Вместе эти две работы говорят не «всё решено» и не «ничего не работает». Они показывают более полезную картину: frontier-модели быстро усиливаются именно в clinical reasoning, но путь от сильной статьи к системе, готовой к внедрению, всё ещё длинный.
И ещё одно уточнение. ER-triage — только самая шумная часть этой работы. В других экспериментах авторы использовали уже o1-preview и тоже получали сильные результаты. Например, в пяти management reasoning cases медианный результат у модели составил 86%, тогда как у врачей с обычными ресурсами — 34%. Это не прямое повторение бостонского ER-среза, но хороший показатель того, почему авторы говорят о более широком клиническом рассуждении, а не об одном удачном hospital test.
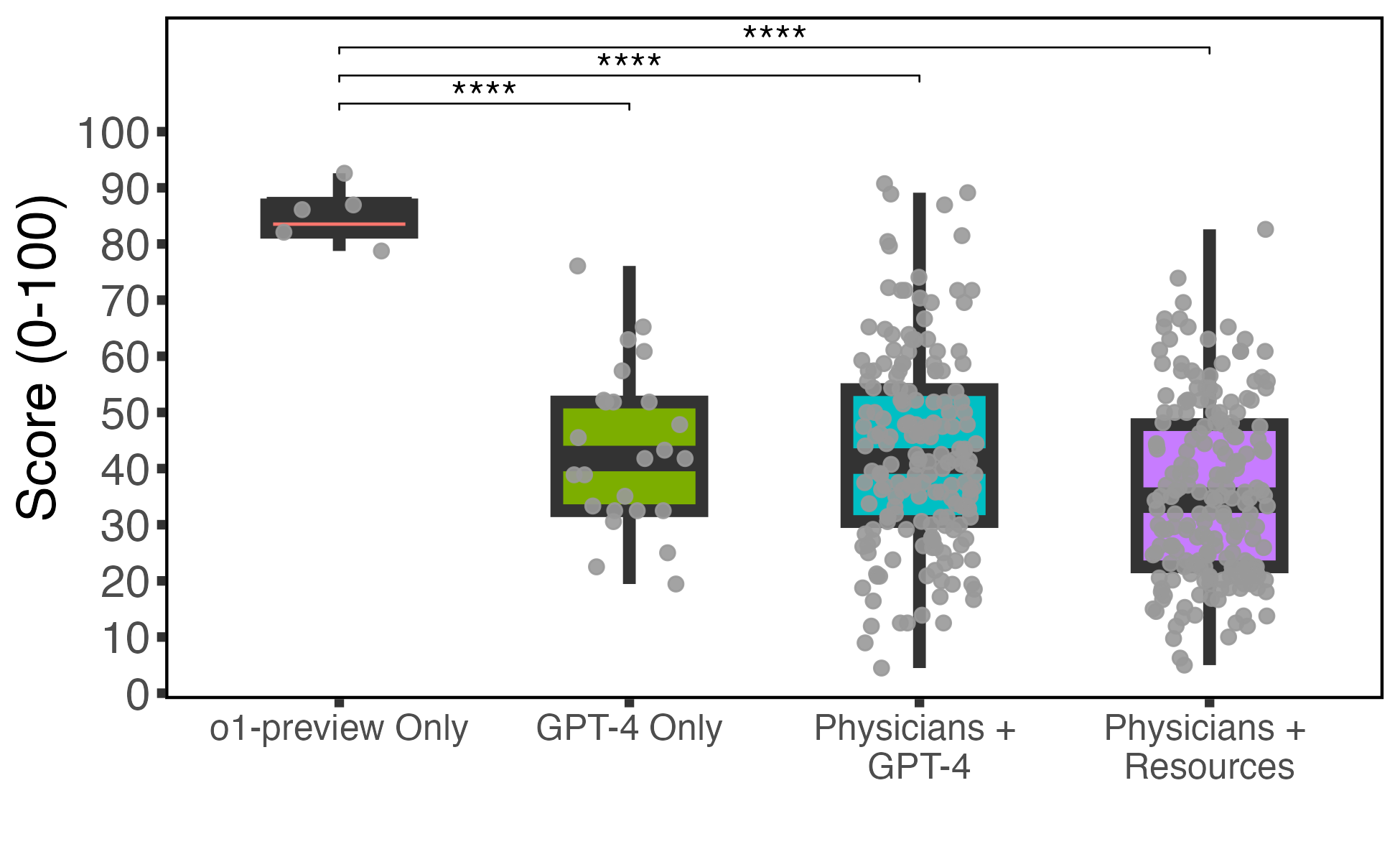
o1-preview, модель набрала медианные 86% на management reasoning cases против 34% у врачей с обычными ресурсами. Это не тот же ER-срез, но важный сигнал о ширине эффекта. Источник: Brodeur et al., Science, 30 апреля 2026 года.Что это меняет для OpenAI и для клиник
Если убрать шум, статья даёт довольно конкретный вывод. Наиболее правдоподобный сценарий на ближайшее время для таких моделей — не автономный «AI-врач», а слой второго мнения в режимах дефицита данных: triage, первичный разбор жалобы, проверка того, что команда не пропустила редкую, но опасную версию, и подсветка нетипичных связок в истории болезни.
Для OpenAI это сильный репутационный сигнал: o1 оказывается не просто reasoning-моделью для математики и кода, а претендентом на роль движка поддержки клинических решений. Это особенно заметно на фоне более широкого биомедицинского разворота компании, который мы уже разбирали в материале про GPT-Rosalind и научный стек OpenAI.
Для больниц и регуляторов вывод другой и куда скучнее: если такие системы правда начинают выигрывать на раннем triage-срезе, следующий шаг — не маркетинг, а prospective trials, аудит логов, human-in-the-loop и очень жёсткая разметка границ ответственности. В соседнем сценарии клинического ИИ это видно на примере ambient listening в Mayo Clinic: там риск смещается от диагноза к записи разговора и согласию пациента.
Поэтому самый честный вывод у этой истории звучит скучнее новостной ленты. OpenAI o1 в Harvard-исследовании не «заменил врача». Он показал, что reasoning-модель уже может быть сильнее человека на части текстового triage-рассуждения и на нескольких соседних задачах clinical reasoning. Это много. Но до автономной практики отсюда всё ещё очень далеко.
Читайте также
- Модели рассуждения: o3, DeepSeek-R1 и новая парадигма
- LLM в психотических диалогах: почему сильный бенчмарк не равен безопасному поведению
- GPT-Rosalind: зачем OpenAI нужна модель для биологии
Источники и дата проверки
- EurekAlert / AAAS — Large language models demonstrate strong performance in physicians’ clinical reasoning tasks, опубликовано 30 апреля 2026 года, проверено 13 мая 2026 года.
- Science — Performance of a large language model on the reasoning tasks of a physician, опубликовано 30 апреля 2026 года, проверено 13 мая 2026 года.
- arXiv PDF — Superhuman performance of a large language model on the reasoning tasks of a physician, версия с полной методологией, проверено 13 мая 2026 года.
- TechCrunch — In Harvard study, AI offered more accurate diagnoses than two human doctors, опубликовано 3 мая 2026 года, проверено 13 мая 2026 года.
- Science Media Centre — expert reaction to study evaluating performance of a large language model on the reasoning tasks of a physician, опубликовано 30 апреля 2026 года, проверено 13 мая 2026 года.
- Harvard Gazette — Should you ask ChatGPT for medical advice?, опубликовано 5 мая 2026 года, проверено 13 мая 2026 года.
- JAMA Network Open — Large Language Model Performance and Clinical Reasoning Tasks, опубликовано 13 апреля 2026 года, проверено 13 мая 2026 года.



