Словарь терминов ИИ: 35 ключевых понятий простым языком
Полный словарь терминов искусственного интеллекта на русском. От базовых понятий до продвинутых: определения, примеры, объяснения простым языком.
Аббревиатуры, англицизмы, техническая терминология: попробуй разберись в искусственном интеллекте, если половина слов незнакома. Мы собрали ключевые термины из мира ИИ и машинного обучения в одном месте. От базовых понятий вроде «нейросети» до специализированных, таких как RAG и LoRA. Каждый термин объяснён простым языком с примерами.
Словарь организован по алфавиту. Возвращайтесь к нему, когда встретите незнакомое понятие в статьях, документации или на конференциях.
Если вы пришли сюда разбирать не отдельный термин, а целый подкластер, держите рядом базовый материал о больших языковых моделях и гайд по AI-агентам и их рабочим сценариям.
А
AGI (Artificial General Intelligence), общий искусственный интеллект
Гипотетический ИИ, способный решать любые интеллектуальные задачи на уровне человека или выше. Современные модели хороши в узких областях (перевод текста, генерация изображений), а AGI должен уметь обучаться новому без специальной настройки. По состоянию на март 2026 года AGI не создан. Это скорее ориентир для исследований, чем реальный продукт.
API (Application Programming Interface), программный интерфейс
Набор правил, по которым одна программа общается с другой. В контексте ИИ это способ отправить запрос к модели и получить ответ. Например, API OpenAI позволяет разработчикам встраивать GPT в свои приложения: отправляешь текстовый запрос, получаешь сгенерированный ответ. Большинство ИИ-сервисов работают через API, и именно оно лежит в основе любых интеграций.
Аугментация данных (Data Augmentation)
Приём, при котором обучающие данные искусственно расширяют: изображения поворачивают, обрезают, меняют яркость; тексты перефразируют. Цель — увеличить разнообразие без сбора новых данных. Помогает модели лучше обобщать, а не запоминать конкретные примеры.
Б
Большая языковая модель (Large Language Model, LLM)
Нейросеть с миллиардами параметров, обученная на огромном корпусе текстов. Умеет генерировать текст, отвечать на вопросы, писать код, переводить. GPT-4o, Claude, Gemini, LLaMA — примеры таких моделей. «Большая» — потому что количество параметров измеряется миллиардами: у GPT-4 предположительно более триллиона, у LLaMA 3 — от 8 до 405 миллиардов. Подробнее об устройстве и применении LLM — в нашем материале «Что такое LLM и как работают большие языковые модели».
Бенчмарк (Benchmark)
Стандартизированный тест для сравнения моделей между собой. MMLU проверяет знания в 57 предметных областях, HumanEval оценивает умение писать код, MT-Bench — качество диалога. Бенчмарки помогают объективно измерить прогресс, но имеют ограничения: модель может «натренироваться» на тестовые данные и показать высокий балл, не став по-настоящему умнее.
В
Внимание, механизм внимания (Attention)
Механизм, позволяющий модели «фокусироваться» на наиболее важных частях входных данных. Когда модель переводит предложение, внимание помогает ей понять, какие слова в оригинале связаны с каким словом в переводе. Self-attention — разновидность, где модель сопоставляет каждый элемент последовательности со всеми остальными. На этом механизме построена архитектура Transformer.
Выравнивание (Alignment)
Настройка ИИ так, чтобы его поведение соответствовало намерениям и ценностям людей. На практике: модель не должна генерировать вредный контент, следовать опасным инструкциям или обманывать пользователя. Основные методы — RLHF (обучение с обратной связью от человека) и Constitutional AI. Alignment остаётся одной из центральных проблем безопасности ИИ.
Г
Галлюцинация (Hallucination)
Ситуация, когда модель уверенно выдаёт ложную информацию. Например, ссылается на несуществующую научную статью или приписывает человеку слова, которых тот не говорил. Причина: модель не «знает» факты, а предсказывает наиболее вероятное продолжение текста. Методы вроде RAG (подключение внешних источников) частично решают проблему, но полностью она пока не устранена.
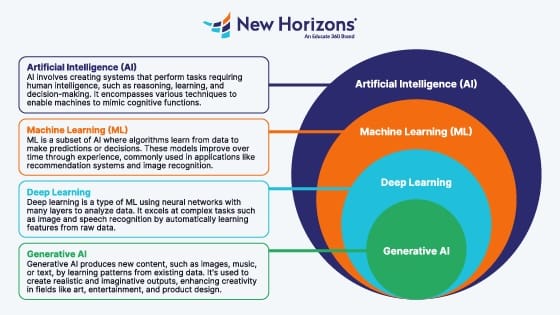
Генеративный ИИ (Generative AI)
Общее название для моделей, которые создают новый контент: текст, изображения, музыку, видео, код. ChatGPT генерирует текст, Midjourney — изображения, Suno — музыку. Аналитические модели классифицируют или предсказывают. Генеративные создают что-то новое на основе изученных закономерностей.
Глубокое обучение (Deep Learning)
Подраздел машинного обучения, использующий нейросети с несколькими слоями (отсюда «глубокое»). За прорывами последних лет стоит как раз глубокое обучение: распознавание изображений, голосовые ассистенты, языковые модели. Отличие от классического ML — модель сама извлекает признаки из сырых данных и не требует ручного выделения важных характеристик.
GPT (Generative Pre-trained Transformer)
Семейство языковых моделей от OpenAI. «Generative» — модель генерирует текст, «Pre-trained» — предварительно обучена на большом корпусе, «Transformer» — архитектура, на которой модель построена. GPT стало нарицательным: часто любую языковую модель называют «GPT», хотя технически это название конкретной линейки OpenAI (GPT-3.5, GPT-4, GPT-4o).
Д
Дообучение (Fine-tuning)
Дополнительное обучение уже готовой модели на специализированных данных. Базовая модель знает «всё понемногу», а после дообучения начинает хорошо справляться с конкретной задачей, например отвечать в стиле техподдержки или генерировать медицинские заключения. Требует значительно меньше данных и вычислений, чем обучение с нуля.
Диффузионная модель (Diffusion Model)
Тип генеративной модели, которая создаёт изображения через «удаление шума». Сначала модель учится превращать картинку в шум, а затем — восстанавливать картинку обратно. При генерации модель берёт случайный шум и поэтапно превращает его в изображение по текстовому описанию. Stable Diffusion, DALL-E 3, Midjourney — все работают по этому принципу.
И
Искусственный интеллект (Artificial Intelligence, AI)
Общий термин для систем, которые выполняют задачи, обычно требующие человеческого интеллекта: распознавание речи, принятие решений, перевод, генерация контента. Современный ИИ — узкий (narrow AI): каждая модель хороша в своей задаче, но не обладает общим пониманием мира. Термин ввёл Джон Маккарти в 1956 году на конференции в Дартмуте.
Инференс (Inference)
Использование уже обученной модели для получения результатов. Когда вы вводите запрос в ChatGPT и получаете ответ, это и есть инференс. Обучение (training) требует огромных вычислительных мощностей и происходит один раз, а инференс выполняется при каждом запросе и определяет скорость работы модели для конечного пользователя.
К
Контекстное окно (Context Window)
Максимальный объём текста, который модель может обработать за один раз: и входной запрос, и собственный ответ. Измеряется в токенах. У GPT-4o контекст составляет 128 тысяч токенов, у Claude 3.5 Sonnet — 200 тысяч, у Gemini 1.5 Pro — до 2 миллионов. Чем больше контекстное окно, тем больше информации помещается в один запрос: целые книги, кодовые базы, длинные переписки.
Классификация (Classification)
Задача, в которой модель относит входные данные к одной из заранее определённых категорий. Спам-фильтр классифицирует письма (спам или нет), система модерации определяет тональность комментария (позитивный, негативный, нейтральный). Одна из базовых задач машинного обучения.
Л
LoRA (Low-Rank Adaptation)
Метод эффективного дообучения больших моделей. Вместо изменения всех миллиардов параметров LoRA добавляет небольшие обучаемые матрицы к существующим слоям. Модель адаптируется к новой задаче, а расход памяти и вычислений сокращается в разы. LoRA стал стандартом для дообучения на пользовательском оборудовании, например для создания персонализированных генераторов изображений на Stable Diffusion.
М
Машинное обучение (Machine Learning, ML)
Область ИИ, в которой модели учатся на данных, а не программируются правилами вручную. Вместо написания условий «если температура выше 30, включить кондиционер» разработчик подаёт модели примеры, и та сама выводит закономерности. Три основных типа: обучение с учителем (есть правильные ответы), без учителя (модель ищет закономерности сама) и с подкреплением (модель получает награды за правильные действия).
Мультимодальность (Multimodality)
Способность модели работать с несколькими типами данных одновременно: текстом, изображениями, аудио, видео. GPT-4o принимает текст и изображения, Gemini обрабатывает текст, картинки, аудио и видео. Мультимодальные модели ближе к человеческому восприятию, которое тоже работает через несколько каналов сразу.
Н
Нейросеть (Neural Network)
Математическая модель, вдохновлённая устройством мозга. Состоит из слоёв «нейронов» — узлов, которые принимают данные, выполняют вычисления и передают результат дальше. Каждое соединение имеет «вес», который настраивается в процессе обучения. Простейшие нейросети решают задачи классификации, а глубокие (с десятками слоёв) лежат в основе современных ИИ-систем.
О
Обработка естественного языка (Natural Language Processing, NLP)
Направление ИИ, связанное с анализом и генерацией человеческого языка. Сюда входят перевод, суммаризация, анализ тональности, извлечение информации, ответы на вопросы. Раньше для каждой задачи требовалась отдельная модель, теперь большие языковые модели справляются с большинством NLP-задач в рамках одного интерфейса.
Обучение с подкреплением (Reinforcement Learning, RL)
Метод обучения, при котором агент учится через взаимодействие со средой: совершает действия, получает награду или штраф и корректирует стратегию. Так DeepMind обучил AlphaGo играть в го лучше чемпионов мира. В контексте LLM применяется RLHF — обучение с подкреплением на основе обратной связи от людей, чтобы модель генерировала более полезные и безопасные ответы.
Обучение с учителем (Supervised Learning)
Самый распространённый тип машинного обучения. Модели подают пары «вход — правильный ответ», и она учится предсказывать ответ для новых данных. Пример: тысячи фотографий кошек и собак с подписями «кошка» или «собака», и модель учится различать их. Качество напрямую зависит от количества и качества размеченных данных.
Открытые модели (Open Source / Open Weight)
Модели, веса которых доступны для скачивания и использования. LLaMA от Meta, Mistral, Qwen от Alibaba — примеры. Тут есть нюанс: open source означает полностью открытый код и данные, а open weight — доступны только веса, без данных обучения. Открытые модели можно запускать локально, дообучать и модифицировать без зависимости от облачного провайдера.
П
Параметр (Parameter)
Числовое значение внутри модели, которое настраивается в процессе обучения. Каждый параметр влияет на то, как модель обрабатывает данные. Количество параметров — грубый индикатор «размера» модели: GPT-3 содержит 175 миллиардов, LLaMA 3.1 — до 405 миллиардов. Больше параметров обычно означает больше возможностей, но и больше требований к вычислительным ресурсам.
Переобучение (Overfitting)
Ситуация, когда модель слишком хорошо запомнила обучающие данные и не может обобщать на новых. Как студент, который вызубрил конкретные задачи из учебника, но не может решить похожую задачу с другими числами. Признак: высокая точность на тренировочных данных и низкая на тестовых. Борются с ним через аугментацию, регуляризацию и увеличение разнообразия данных.
Промпт (Prompt)
Текстовая инструкция, которую пользователь отправляет модели. «Напиши письмо начальнику с просьбой об отпуске» — типичный промпт. Качество ответа модели напрямую зависит от формулировки запроса. Чем конкретнее промпт, тем точнее результат. Как составлять эффективные промпты — разбираем в статье «Промпт-инжиниринг в 2026: техники, которые действительно работают».
Промпт-инжиниринг (Prompt Engineering)
Практика составления эффективных запросов к ИИ-моделям. Включает техники: few-shot (примеры в запросе), chain-of-thought (пошаговые рассуждения), role prompting (задание роли, например «ты — опытный юрист»). Грамотный промпт-инжиниринг может кратно улучшить качество ответов без изменения самой модели.
Р
RAG (Retrieval-Augmented Generation)
Метод, при котором модель перед генерацией ответа ищет релевантную информацию во внешней базе знаний. Схема работы: пользователь задаёт вопрос, система находит подходящие документы, передаёт их модели вместе с вопросом, и модель формирует ответ на основе найденных данных. RAG снижает галлюцинации и позволяет модели работать с актуальной информацией, которой не было в обучающих данных.
С
Свёрточная нейросеть (Convolutional Neural Network, CNN)
Тип нейросети, разработанный специально для обработки изображений. Сканирует картинку небольшими фрагментами (фильтрами), выделяя сначала простые элементы (линии, углы), а затем более сложные (лица, объекты). До появления трансформеров CNN были основным инструментом компьютерного зрения. Сейчас часто применяются вместе с трансформерами в гибридных архитектурах.
Т
Температура (Temperature)
Параметр генерации, который управляет «креативностью» модели. При температуре 0 модель выбирает самое вероятное продолжение, ответы получаются предсказуемые и однообразные. При температуре 1 и выше ответы более разнообразные, но менее стабильные. Для фактических задач (суммаризация, перевод) лучше низкая температура, для творческих (генерация идей, сценариев) — повыше.
Токен (Token)
Единица текста, с которой работает языковая модель. Не слово и не буква, а нечто среднее. Английское слово обычно составляет 1–2 токена, русское — 2–4 (русский язык «дороже» для моделей). Слово «искусственный» может быть разбито на 3–4 токена. Стоимость API измеряется в токенах: чем длиннее запрос и ответ, тем дороже.
Трансформер (Transformer)
Архитектура нейросети, предложенная Google в 2017 году в статье «Attention Is All You Need». В основе — механизм self-attention, позволяющий модели учитывать связи между всеми элементами последовательности одновременно. На трансформерах построены практически все современные LLM (GPT, Claude, Gemini, LLaMA) и многие модели генерации изображений.
Ф
Fine-tuning — см. Дообучение
Ч
Чат-бот (Chatbot)
Программа, которая общается с пользователем в формате диалога. Современные чат-боты на основе LLM (ChatGPT, Claude, Gemini) отличаются от старых rule-based ботов кардинально: понимают контекст, генерируют осмысленные ответы, адаптируются к стилю общения. Применяются в клиентской поддержке, образовании, программировании, творчестве.
Э
Эмбеддинг (Embedding)
Числовое представление текста (или изображения, звука) в виде вектора, то есть списка чисел. Модель превращает слово, предложение или документ в вектор так, что похожие по смыслу тексты оказываются «близко» друг к другу в математическом пространстве. Эмбеддинги — основа семантического поиска и RAG: вместо поиска по ключевым словам система ищет по смыслу.
Эпоха (Epoch)
Один полный проход обучающих данных через модель во время тренировки. Если в датасете 10 000 примеров, то одна эпоха — обработка всех 10 000. Обычно модель обучается несколько эпох: за первый проход она улавливает грубые закономерности, за последующие — уточняет. Слишком много эпох ведут к переобучению, слишком мало — модель не успевает выучить данные.
Я
Языковая модель (Language Model)
Модель, обученная предсказывать следующее слово (токен) в последовательности. Эта, казалось бы, простая задача — предсказание следующего токена — лежит в основе всех современных LLM. Модель читает текст и учится: после «Москва — столица» с высокой вероятностью идёт «России». Накопив закономерности из триллионов токенов, модель начинает генерировать связный, осмысленный текст.
Что дальше
Словарь покрывает основные термины, которые встретятся вам в статьях, документации и обсуждениях про ИИ. Технологии развиваются быстро, новые понятия появляются каждый месяц. Мы будем обновлять глоссарий по мере появления важных терминов.
Не нашли нужный термин? Напишите в комментариях, добавим в следующем обновлении.