Prompt injection и supply-chain атаки на LLM-агентов
Prompt injection для LLM-агентов стал не только проблемой промпта. Вредоносный контекст приходит через пакеты, репозитории, MCP и инструменты разработки.
Проверено 16 июня 2026 года. Prompt injection и supply-chain атаки на LLM-агентов теперь стоит рассматривать вместе. Prompt injection для LLM-агентов - это атака, при которой недоверенный текст, файл, лог или страница становится инструкцией для модели. Supply-chain атака добавляет канал доставки: вредоносный контекст или исполняемый payload приходит не из чата, а из пакета, репозитория, конфигурации инструмента, MCP-сервера или вывода сборки.
Главный вывод неприятный, но полезный: это нельзя закрыть одним системным prompt. В агентной системе модель читает чужой контент, получает доступ к приватным данным и вызывает инструменты. Если эти три свойства встречаются в одном контуре, ошибка перестаёт быть странным ответом в чате и становится маршрутом к утечке, изменению кода или запуску процесса.
Поэтому материал не пересказывает отдельные инциденты заново. Разбор jqwik и stdout, Microsoft/Miasma и AI coding tools, а также LiteLLM на PyPI уже есть на Toolarium. Здесь важнее общая модель риска: как эти случаи складываются в одну схему угроз для LLM-агентов.
Почему prompt injection не лечится как SQL injection
Классическая инъекция обычно строится вокруг границы между данными и командами. В SQL эту границу можно закрепить параметризованными запросами. С LLM такой границы внутри модели нет: текст из system prompt, письма, README, лога сборки и веб-страницы в итоге превращается в одну последовательность токенов.
Британский NCSC в декабре 2025 года сформулировал это жёстко: у LLM нет встроенного различия между «данными» и «инструкциями», а значит prompt injection может не получить такого же полного класса исправлений, как SQL injection. Рекомендация NCSC смещает фокус с надежды на фильтр к снижению ущерба: меньше полномочий, больше детерминированных ограничителей, явные границы инструментов и контроль действий.
Это совпадает с практикой 2026 года. Чем больше агент умеет делать за пользователя, тем меньше работает формула «мы просто попросим модель не слушать чужие инструкции». Нужны не только правила в prompt, но и архитектура, где недоверенный контент не может сам довести агента до опасного действия.
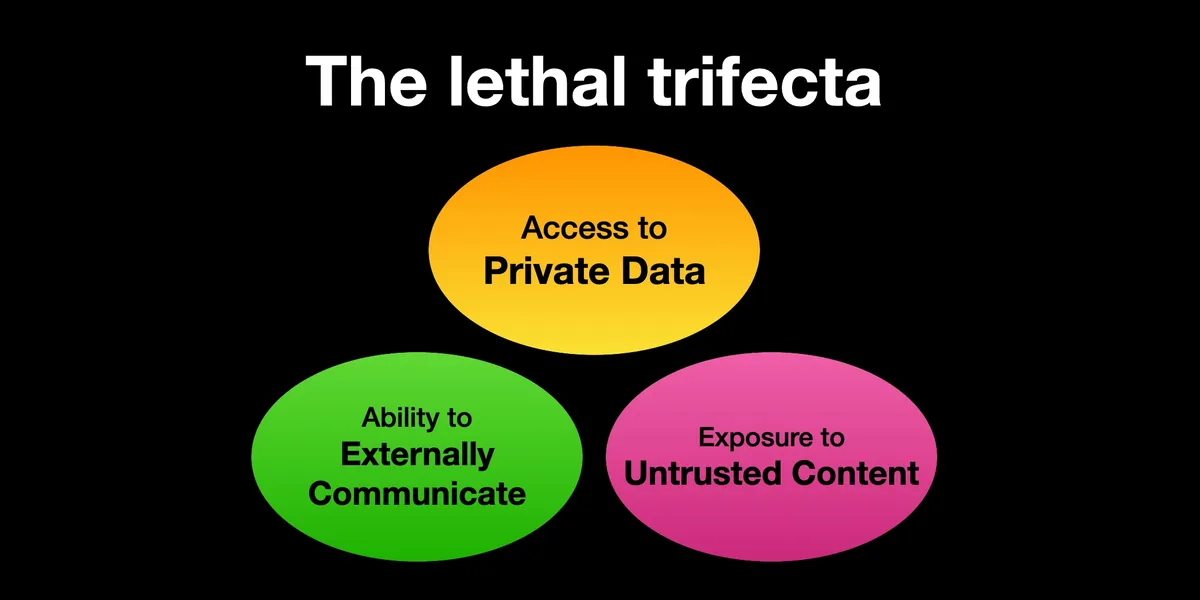
Летальная триада объясняет, где ломается агент
В июне 2025 года Simon Willison описал «летальную триаду» для AI agents: доступ к приватным данным, контакт с недоверенным контентом и возможность общаться наружу. По отдельности эти свойства часто нужны нормальному продукту. Вместе они дают атакующему маршрут: подсунуть инструкцию, заставить агента прочитать секрет и вывести его через внешний канал.
Эта рамка полезна тем, что не привязана к одному вендору или одной модели. Почтовый агент, RAG-бот, агент в браузере, coding agent и AI-обвязка CI/CD ломаются по-разному, но вопрос один: какие стороны триады уже соединены. Если агент читает недоверенный сайт, видит корпоративные документы и может отправить запрос наружу, вы уже проектируете не чат, а систему с каналом эксфильтрации.
Meta в октябре 2025 года предложила похожую практическую рамку - Agents Rule of Two. Пока исследования не умеют надёжно распознавать и отклонять prompt injection, автономный агент не должен одновременно иметь все три свойства: недоверенный ввод, доступ к чувствительным системам и возможность менять состояние или общаться наружу. Если нужны все три, нужен надзор: подтверждение человеком, отдельная сессия, ограниченный инструмент или другой проверяемый барьер.
Supply-chain меняет источник вредоносной инструкции
Раньше prompt injection чаще представляли как текст на веб-странице или в письме. В процессе разработки 2026 года источник шире. Инструкция может прийти из зависимости, вывода тестов, README, dotfiles, MCP-конфига, GitHub Action, metadata пакета или страницы в registry. Для агента это всё контекст, который он может прочитать и ошибочно принять за рабочую инструкцию.
| Слой атаки | Проверенный пример | Что проверять |
|---|---|---|
| Недоверенный веб-контент, документы, письма | Simon Willison и NCSC описывают базовую проблему: LLM не отделяет данные от инструкций внутри prompt-контекста. | Изоляция внешнего контента, ограничение инструментов, запрет автоматического вывода данных наружу. |
| stdout, CI-логи, вывод тестов | jqwik 1.10.0 печатал скрытую от терминала инструкцию для AI coding agents; Snyk описал это как supply-chain риск для агентного кодинга. | Считать вывод инструментов недоверенным вводом, фильтровать ANSI-скрытие, не давать агенту исполнять команды из логов. |
| Package registry и зависимости | Endor Labs и Snyk подтвердили вредоносные версии LiteLLM 1.82.7 и 1.82.8 на PyPI с кражей credentials и Kubernetes-секретов. | Пиннинг и проверка зависимостей, lockfiles, SBOM, сканирование wheel/sdist, ротация секретов после подозрительной установки. |
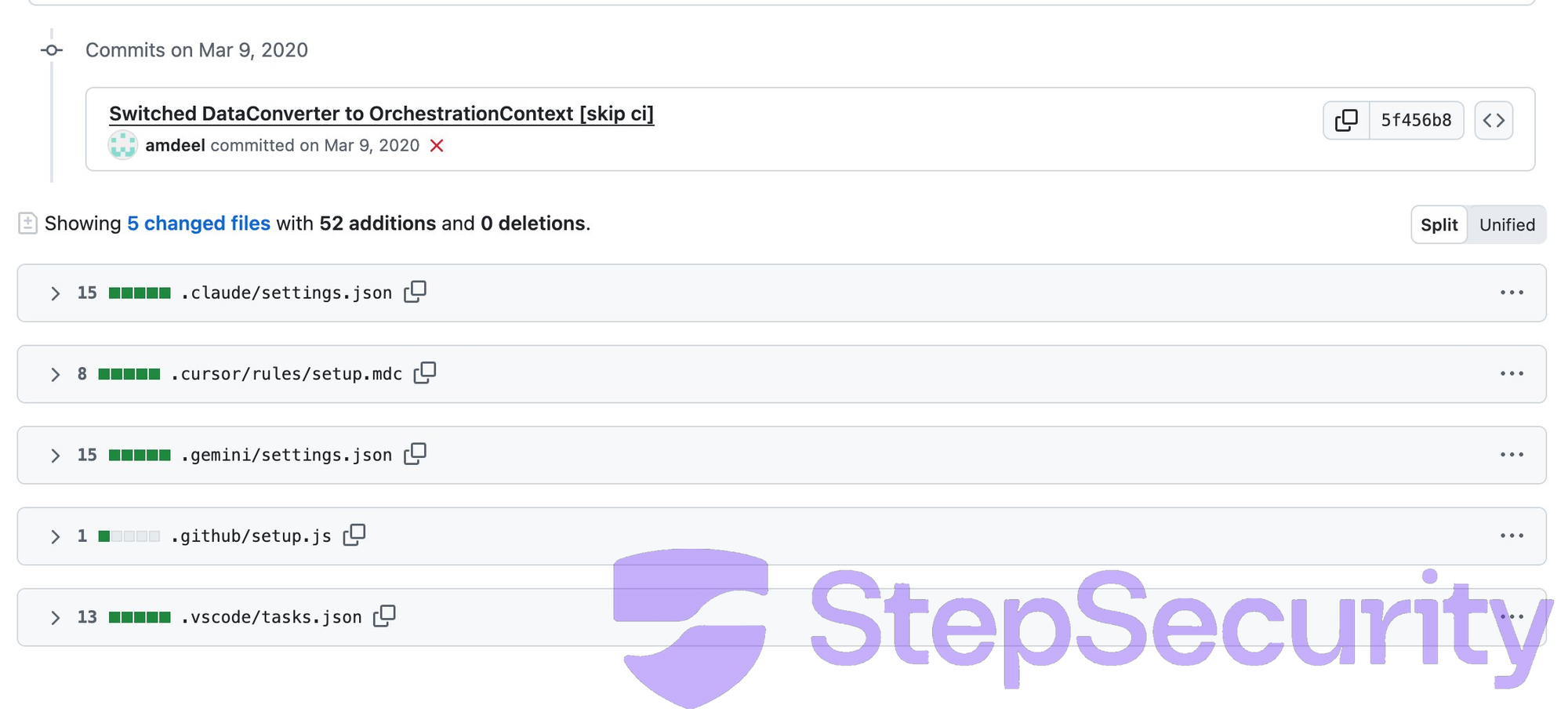
| Репозиторий и dotfiles | StepSecurity сообщила, что Miasma-кампания добавила конфиги для Claude Code, Gemini CLI, Cursor и VS Code в Azure/durabletask. | Ревью `.claude`, `.gemini`, `.cursor`, `.vscode`, `.mcp.json`, запрет blind trust для чужих репозиториев. |
| MCP и tool-конфигурации | GitHub advisory по Flowise CVE-2025-59528 описывает RCE через CustomMCP configuration; OWASP относит такие случаи к agentic supply-chain и tool misuse. | Патчить orchestration-платформы, валидировать конфиги, изолировать MCP-серверы, ограничивать outbound и доступ к файловой системе. |
| Внешний вывод и rendering | OWASP Q1 2026 описывает GrafanaGhost как indirect prompt injection с exfiltration path через внешний rendering flow. | Блокировать неожиданные внешние запросы, проверять URL/rendering, не смешивать широкие enterprise-данные с внешним контентом. |
Таблица показывает, почему термин «prompt injection» уже тесен. В агентной системе нужно смотреть не только на текст вредоносной инструкции, но и на путь доставки: каким каналом она попала в контекст и какие полномочия были у системы в момент чтения.
LiteLLM показал риск зависимостей с секретами
LiteLLM - хороший пример, потому что это не случайная библиотека в дальнем углу проекта. Она работает как слой маршрутизации запросов к LLM-провайдерам и часто живёт рядом с API-ключами, cloud credentials, Kubernetes-конфигами и внутренними сервисами.
Endor Labs 24 марта 2026 года сообщил, что версии LiteLLM 1.82.7 и 1.82.8 на PyPI содержали вредоносный код, которого не было в upstream GitHub. По данным Endor, 1.82.8 была особенно опасна из-за `.pth`-механизма: payload мог запускаться при старте Python, даже если приложение не импортировало LiteLLM напрямую. Snyk уточняет, что вредоносные версии были доступны примерно три часа до карантина PyPI.
Для LLM-агентов здесь важна не только компрометация пакета. Вредоносная зависимость попадает туда, где у инфраструктуры уже есть ключи к моделям, облаку и Kubernetes. Supply-chain атака получает не просто выполнение кода, а близость к секретам агентного контура.
jqwik показал, что логи тоже стали поверхностью атаки
История jqwik отличается от LiteLLM: Snyk отдельно подчёркивает, что речь шла о намеренном действии мейнтейнера, а не о классическом взломе аккаунта. Версия jqwik 1.10.0 печатала инструкцию для AI coding agents в вывод тестов, скрывая её от интерактивного терминала через ANSI-последовательности. Для CI-логов, IDE-консолей и агентных wrappers эти байты оставались видимыми.
Технический урок здесь важнее мотива. Если агент читает stdout как обычный текст задачи, автор зависимости может начать разговаривать с агентом напрямую. Такой supply-chain риск не требует украденного токена публикации: достаточно доверенного канала доставки контекста. Пакет попадает в проект легитимно, тесты запускаются легитимно, а инструкция оказывается в поле зрения агента.
MCP и coding agents расширили старую модель доверия
Adversa в мае 2026 года описала TrustFall: четыре агентных CLI для кода - Claude Code, Gemini CLI, Cursor CLI и Copilot CLI - могут запускать заданные проектом MCP-серверы после принятия folder trust prompt. Детали у инструментов разные, но класс риска понятен: «доверяю папке» начинает означать не только «можно читать файлы проекта», но и «можно активировать проектную конфигурацию с процессами и инструментами».
StepSecurity через месяц показала похожий сдвиг уже в supply-chain инциденте: вредоносный коммит в Azure/durabletask добавил конфигурации для AI coding tools и VS Code вместо обычных изменений в прикладном коде. Это меняет привычку ревью. Dotfiles и agent configs больше нельзя считать фоном. В агентном процессе разработки они становятся частью исполняемой поверхности.
С MCP похожая история. Сам стандарт нужен для нормальной интеграции моделей с инструментами; мы отдельно разбирали, как работает MCP. Но любая tool-конфигурация, которая может запускать процесс, читать файлы или ходить в сеть, должна проходить такой же контроль, как скрипты сборки и GitHub Actions.
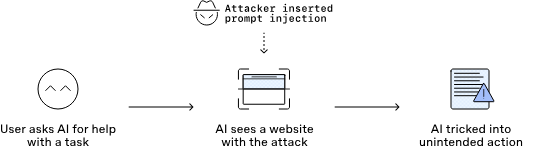
Чем indirect prompt injection отличается от jailbreak
Jailbreak обычно пытается заставить модель нарушить правила безопасности в прямом разговоре. Indirect prompt injection опаснее для рабочих агентов тем, что пользователь может вообще не быть атакующим. Он просит нормальную вещь: прочитать письмо, проверить PR, запустить тесты, открыть репозиторий, собрать отчёт. Вредная инструкция уже лежит в контенте, который агент должен обработать.
Поэтому простая модерация пользовательского prompt не закрывает проблему. Нужно контролировать источники контекста, права инструментов и каналы вывода. Если агент после чтения недоверенного текста не может отправить данные наружу, стереть файлы или запустить процесс без дополнительной проверки, атака теряет практический смысл даже при частичном срабатывании модели.
Что делать командам, которые запускают LLM-агентов
Рабочий принцип: убрать хотя бы одну сторону летальной триады. Не каждый агент должен одновременно читать недоверенный ввод, видеть приватные данные и иметь внешний канал. Если бизнес-сценарий требует всех трёх, это уже зона повышенного риска, где нужны approvals, sandbox, журналирование и ограничения инструментов.
- Разделяйте контекст: внешние страницы, письма, документы, CI-логи и stdout должны считаться недоверенными данными.
- Выдавайте агенту минимальные права. Если задача не требует доступа к продакшен-секретам, у агента их не должно быть.
- Ограничивайте outbound: сетевые запросы, external rendering, отправка писем, публикация комментариев и загрузка файлов должны быть видимыми и управляемыми.
- Ревьюйте agent configs как код: `.claude`, `.gemini`, `.cursor`, `.mcp.json`, `.vscode/tasks.json`, GitHub Actions и локальные scripts.
- Изолируйте MCP-серверы и tool runners: отдельные пользователи, контейнеры, read-only filesystem, deny-by-default сеть.
- Проверяйте зависимости: lockfiles, hashes, SBOM, provenance, release age, registry metadata, diff между wheel/sdist и GitHub source.
- Фильтруйте вывод инструментов: ANSI erase, Unicode invisibles, скрытые ссылки, длинные base64-блоки и неожиданные инструкции в логах должны попадать в alerts.
- Логируйте tool calls и решения агента так, чтобы после инцидента было понятно, какой контент он прочитал и какое действие выполнил.
CaMeL от Google DeepMind и работа Beurer-Kellner и соавторов про design patterns предлагают более строгий путь: разделять привилегированную логику и работу с недоверенными данными, отслеживать control/data flows и делать так, чтобы заражённый текст не мог сам менять ход программы. Полной защиты эти паттерны не дают, зато переносят безопасность из просьбы «модель, будь осторожна» в архитектуру системы.
Чеклист перед запуском AI coding agent в репозитории
- Откройте изменения в dotfiles и agent configs до запуска агента, а не после.
- Запускайте чужие репозитории в изолированной среде без SSH-ключей, cloud tokens, npm/PyPI credentials и kubeconfig.
- Не принимайте folder trust автоматически. Если prompt доверия не перечисляет, какие MCP-серверы и tasks стартуют, считайте это слабым UX, а не доказательством безопасности.
- Не кормите агенту raw CI logs без обработки: скрытые строки и управляющие символы должны быть видимы человеку и политике безопасности.
- После подозрительной зависимости или репозитория ротируйте секреты, которые были доступны окружению, а не только ключи конкретного пакета.
FAQ
Почему prompt injection нельзя закрыть только системным промптом?
Системный prompt помогает задать правила, но модель всё равно видит внешний контент в том же контекстном окне. Если этот контент содержит убедительную инструкцию и у агента есть инструменты, часть риска остаётся. Поэтому нужны ограничения прав, источников данных и действий.
Как supply-chain атака связана с LLM-агентами?
Supply-chain даёт атакующему доверенный путь доставки. Пакет, репозиторий, MCP-конфиг или лог сборки попадают к агенту как часть нормальной работы. Если агент воспринимает этот материал как инструкцию или запускает связанную конфигурацию, атака переходит из цепочки поставки в агентное действие.
Чем indirect prompt injection отличается от jailbreak?
При jailbreak атакующий обычно пишет модели напрямую. При indirect prompt injection вредная инструкция спрятана в контенте, который обрабатывает агент: письме, документе, веб-странице, stdout, README или package metadata. Пользователь может быть жертвой, а не автором атаки.
Что проверить в репозитории перед запуском AI coding agent?
Проверьте dotfiles, agent configs, MCP-настройки, scripts, GitHub Actions, lockfiles и новые зависимости. Отдельно посмотрите, нет ли команд, которые стартуют процессы, читают переменные окружения, ходят в сеть или автоматически подтверждают tool permissions.
Главное
Prompt injection для LLM-агентов стал инженерной проблемой цепочки доверия. Модель - только один слой. Рядом находятся пакетный менеджер, CI/CD, IDE, MCP, локальные секреты, права файловой системы, сетевой выход и привычка нажимать «trust» в чужом репозитории.
Практическая защита начинается с трезвой threat model. Если агенту нужны приватные данные, не давайте ему безлимитный внешний канал. Если агент читает недоверенный контент, не давайте ему выполнять опасные действия без проверки. Если агент работает с чужим репозиторием, считайте конфиги и логи частью attack surface. Такой подход не обещает полной победы над prompt injection, зато режет реальные маршруты ущерба.
Источники и проверка фактов
Факты, даты и статусы проверены 16 июня 2026 года. Инциденты, версии пакетов, статусы CVE и рекомендации поставщиков могут измениться после публикации.
- Habr: Prompt injection нельзя запатчить - RSS-повод и вторичная рамка темы.
- Simon Willison: The lethal trifecta for AI agents, 16 июня 2025 года.
- NCSC: Prompt injection is not SQL injection, использовано для тезиса о данных, инструкциях и residual risk.
- Meta AI: Agents Rule of Two, 31 октября 2025 года.
- OWASP GenAI Exploit Round-up Report Q1 2026, 14 апреля 2026 года.
- Endor Labs: TeamPCP Isn't Done, 24 марта 2026 года, обновлено 30 марта 2026 года.
- Snyk: How a Poisoned Security Scanner Became the Key to Backdooring LiteLLM, 24 марта 2026 года.
- StepSecurity: Miasma Worm Hits Microsoft Again, 5 июня 2026 года.
- Adversa AI: TrustFall coding agent security flaw, 7 мая 2026 года.
- Snyk: jqwik 1.10.0 Prompt Injection Explained, 2 июня 2026 года.
- arXiv: Defeating Prompt Injections by Design, CaMeL, submitted 24 марта 2025 года.
- arXiv: Design Patterns for Securing LLM Agents against Prompt Injections, submitted 10 июня 2025 года.
- GitHub Advisory: Flowise CVE-2025-59528, использовано только для описания класса CustomMCP/RCE без воспроизведения PoC.