Open Agent Leaderboard: почему ошибки AI-агентов нужно считать в деньгах
Hugging Face и IBM Research запустили Open Agent Leaderboard. Разбираем, почему стоимость AI-агента нужно считать вместе с его ошибками.
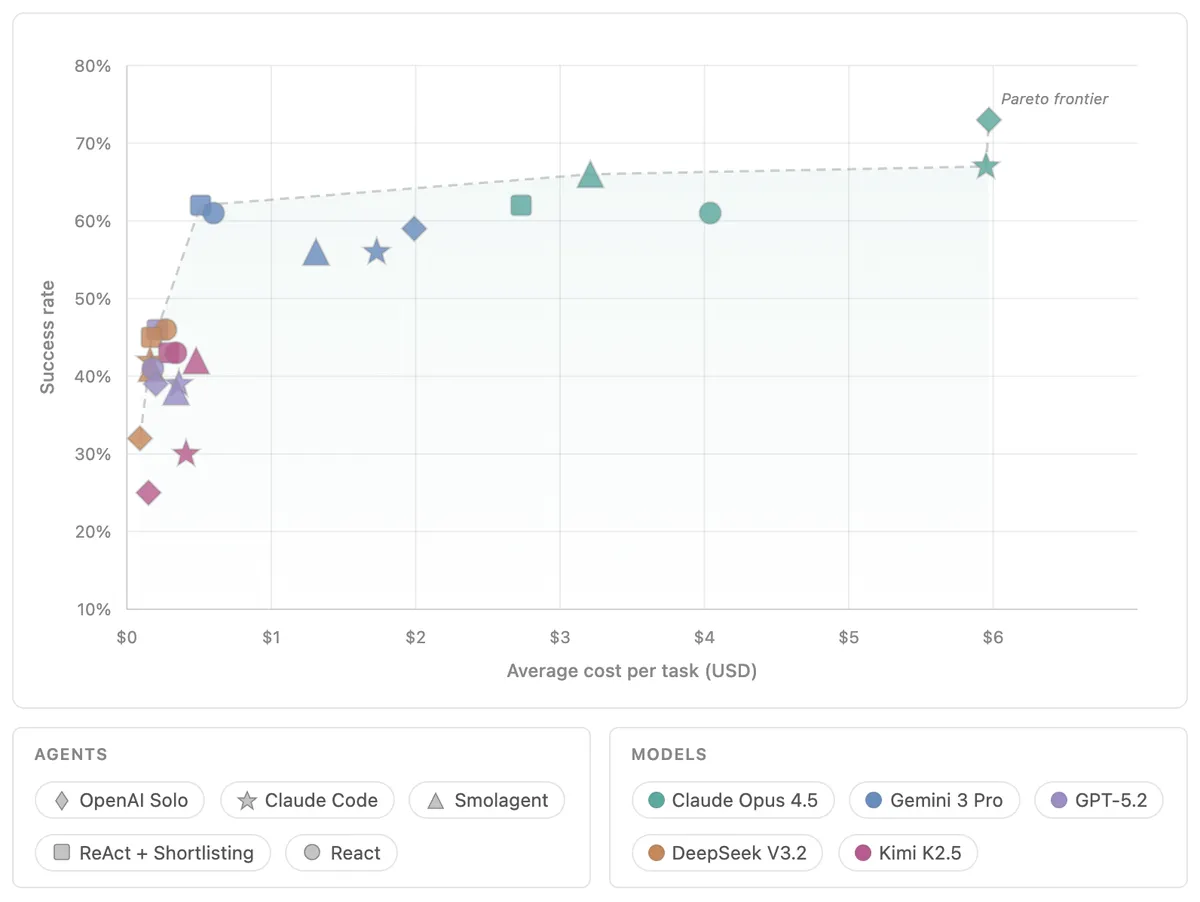
По состоянию на 27 мая 2026 года Open Agent Leaderboard от Hugging Face и IBM Research предлагает более взрослый способ сравнивать AI-агенты. Он смотрит не только на модель внутри, а на всю систему: модель, инструменты, планирование, память, поведение при ошибке и стоимость выполнения задачи.
Это важный сдвиг для команд, которые уже пробуют агентов в разработке, поддержке, исследовательских задачах или внутренних процессах. В обычном рейтинге модель может выглядеть сильной. В реальном рабочем процессе та же модель начинает стоить по-разному, если её обернуть в другой агентный слой. А неудачный запуск, как показали авторы лидерборда, в их экспериментах обходился на 20-54% дороже успешного.
Поэтому новость не про очередную таблицу «кто первый». Open Agent Leaderboard полезен тем, что переводит разговор об AI-агентах из режима «какая модель умнее» в режим «какая система даёт результат за разумные деньги и не сжигает бюджет на провалах».
Что запустили Hugging Face и IBM Research
Hugging Face опубликовала Open Agent Leaderboard 18 мая 2026 года. Проект связан с фреймворком Exgentic и статьёй General Agent Evaluation, представленной на ICLR 2026 Workshop on Agents in the Wild. Авторы называют его открытым бенчмарком для сравнения полных агентных систем.
Ключевое слово здесь — «систем». В строке лидерборда стоит не абстрактная LLM, а конкретная связка агента и модели. В расчёт входят интерфейс, доступные действия, способ планирования, обработка ошибок и стоимость. В официальной карточке организации Hugging Face формулировка такая: лидерборд сравнивает полного агента, включая модель, инструменты, стратегию планирования и восстановление после ошибки.
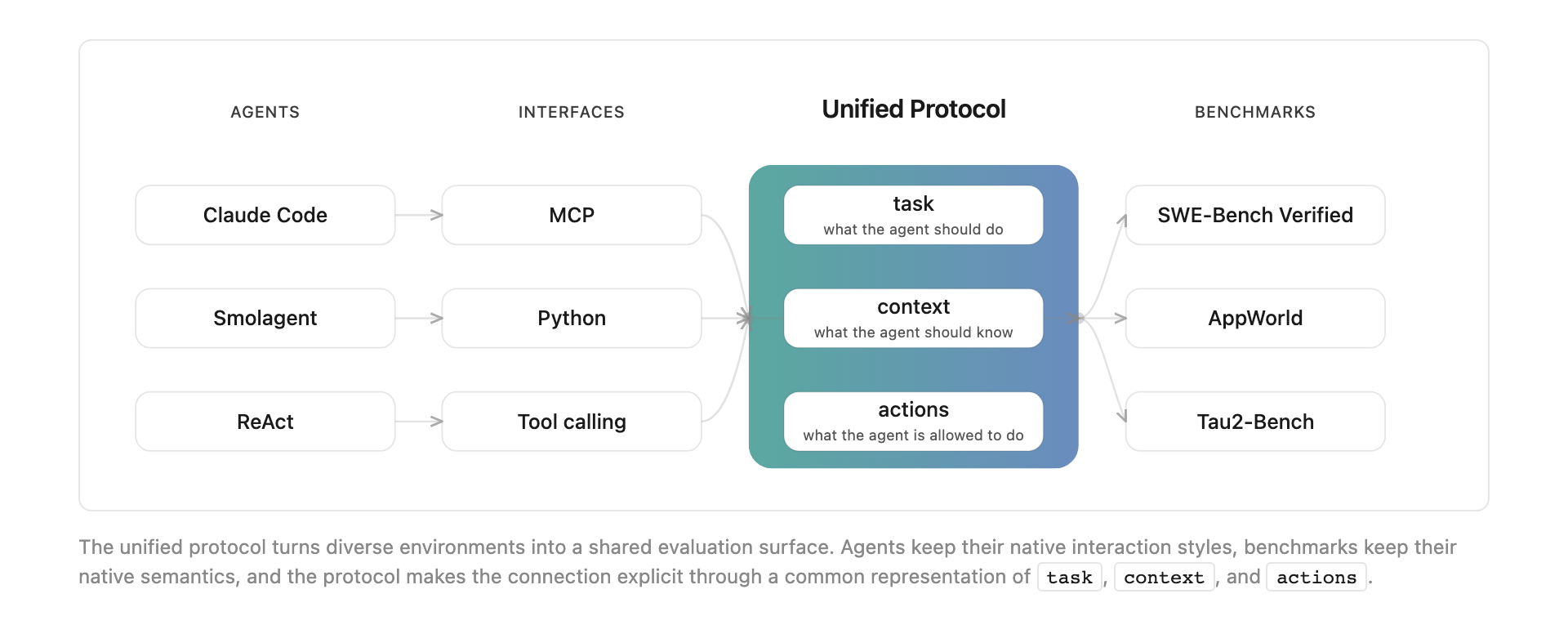
Оценка собрана из шести задач: SWE-Bench Verified, BrowseComp+, AppWorld, Tau2 Airline, Tau2 Retail и Tau2 Telecom. Такой набор не покрывает всю агентность, но намеренно смешивает разные режимы работы: исправление кода, веб-исследование, действия в приложениях, клиентскую поддержку и техническую поддержку по правилам.
Это лучше отражает реальную проблему внедрения. Команда покупает не «модель для одного теста», а систему, которая должна переноситься между задачами. Если агент отлично чинит баги, но плохо следует правилам поддержки, общий результат уже не выглядит универсальным.
Почему одна и та же модель даёт разные счета
В официальном примере top-5 первые три конфигурации используют Claude Opus 4.5, но показывают разные проценты успеха и разную стоимость задачи. OpenAI Solo, Claude Code и Smolagent стоят рядом по модели, но не совпадают по качеству и цене. Разница возникает из агентной обвязки: как система выбирает инструменты, сколько шагов делает, когда останавливается и как восстанавливается после сбоя.
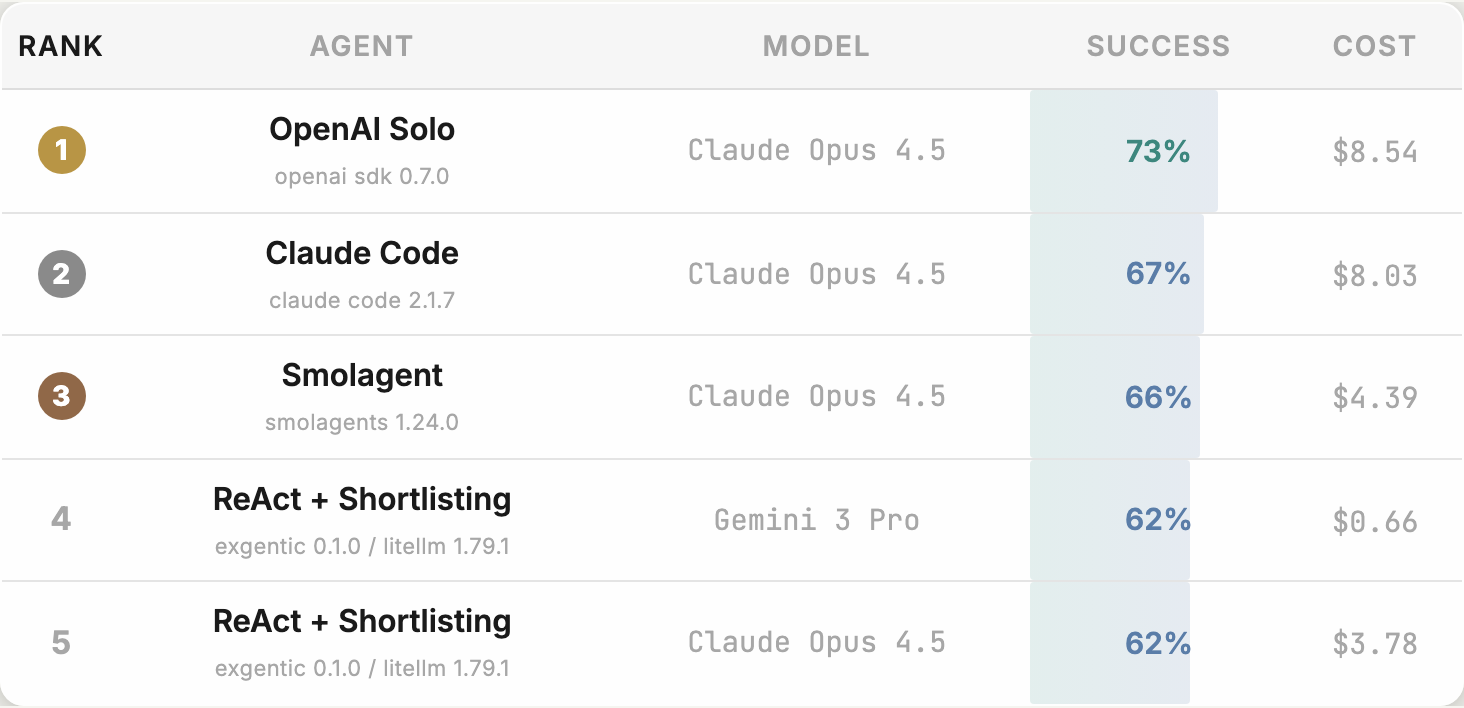
Для разработчика это звучит знакомо. Цена агента складывается не только из тарифа на токены. Её увеличивают лишние вызовы инструментов, длинные траектории, ошибки остановки, повторные попытки, плохое сокращение списка tools и ручной triage после провала. Мы уже разбирали это в материале про tokenmaxxing и tool-overuse у AI-агентов в продакшене: агент может выглядеть «автономнее», но платить за это приходится дополнительными шагами и человеческим разбором.
Open Agent Leaderboard добавляет к этому открытую метрику. Он показывает среднюю долю успешных запусков, среднюю стоимость задачи и расклад по бенчмаркам. На графике качества и стоимости видна граница Парето: конфигурации, которые дают лучший баланс, а не просто максимальный балл любой ценой.
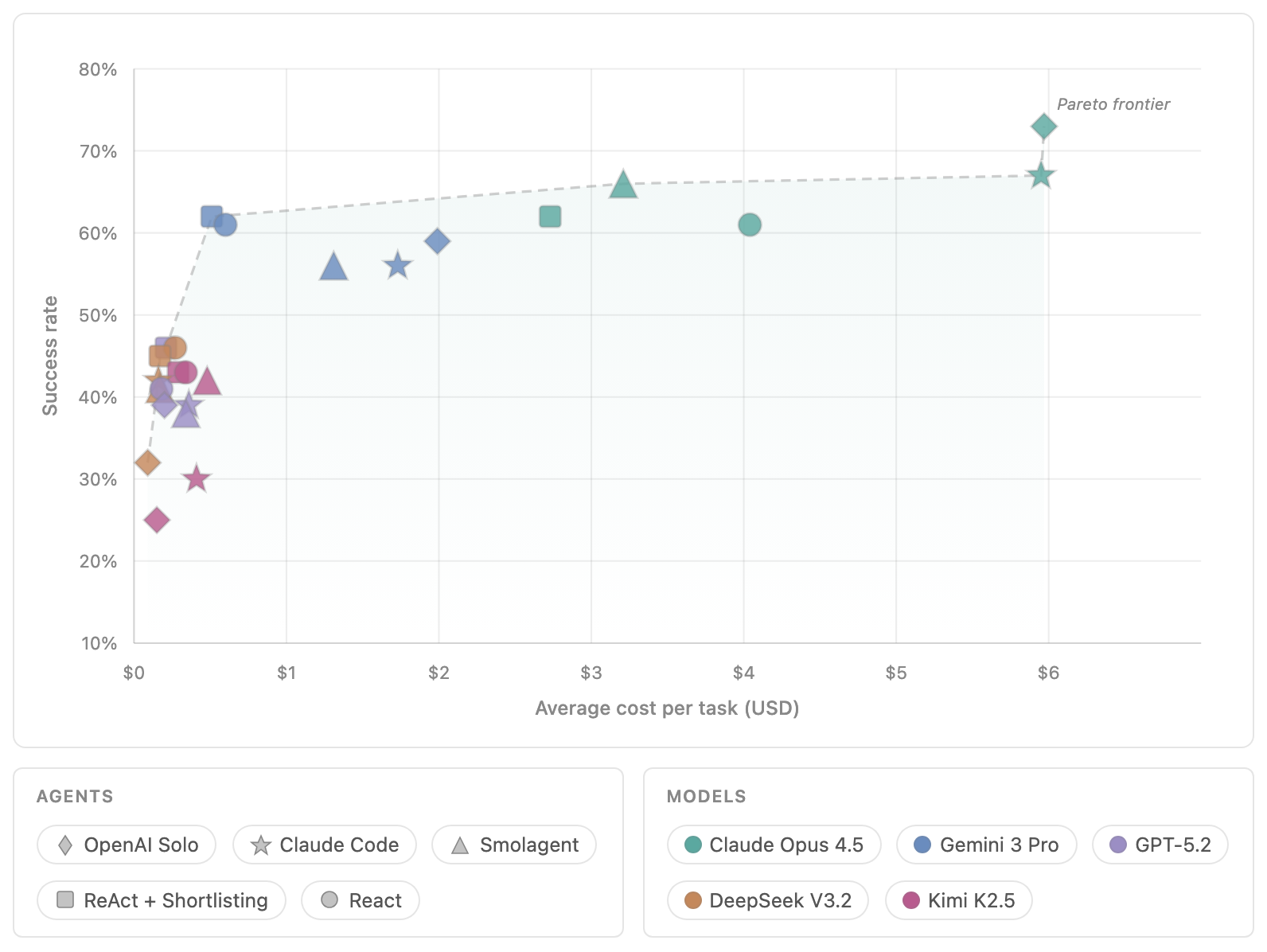
Самая неприятная метрика: провалы стоят дороже
В статье Hugging Face / IBM Research есть короткая, но важная цифра: неудачные запуски в их экспериментах стоили на 20-54% дороже успешных. Формулировку нужно читать аккуратно. Это не универсальный закон для всех AI-агентов и не обещание, что каждый провал всегда будет дороже на такой процент. Это результат конкретного набора экспериментов в Open Agent Leaderboard.
Но сама логика знакома любой команде, которая запускала агентов не в демо, а в рабочем процессе. Успешный запуск часто короче: агент понял задачу, выбрал нужный инструмент, сделал несколько шагов и закончил. Провальный запуск тянется дольше. Система пробует обходные пути, повторяет вызовы, перечитывает контекст, делает неверные действия и в конце всё равно отдаёт человеку недоделанную работу.
Отсюда следует неприятный вывод для расчёта экономики. Нельзя умножить цену «одного хорошего прогона» на количество задач и получить бюджет. Нужно считать распределение исходов: сколько задач заканчиваются успешно, сколько уходят в длинный провал, сколько требуют ручной проверки, сколько повторяются из-за плохого восстановления после сбоя. Именно здесь стоимость AI-агентов перестаёт быть прайсом на токены и становится метрикой качества рабочего процесса.
Что leaderboard не доказывает
Open Agent Leaderboard не доказывает, что найден «лучший AI-агент». Он также не закрывает вопрос общей агентности. Авторы сами пишут, что набор не покрывает все способности, которые когда-нибудь понадобятся general-purpose agent. Результаты могут отличаться от отдельных benchmark leaderboard, потому что здесь агенты тестируются как общие системы без тонкой настройки под каждый тест.
Это ограничение делает проект честнее. Большая часть публичных сравнений AI-агентов страдает от обратной проблемы: красивый процент выглядит как способность, хотя за ним может стоять тонкая оптимизация под конкретный набор задач. Мы уже писали похожую историю в материале про GTA-2 benchmark AI-агентов: настоящий провал часто виден не в одной итоговой цифре, а в том месте рабочего процесса, где агент теряет задачу.
Здесь важна не абсолютная позиция в рейтинге, а разложение результата. Если модель объясняет большую часть качества, но agent architecture уже меняет outcome и стоимость, командам придётся измерять оба слоя. Иначе можно купить сильную модель, завернуть её в плохой агентный контур и получить дорогую систему с нестабильным поведением.
Почему security-slop важен для этой темы
История с bug bounty и Linux security reports хорошо показывает, что цена ошибки агента не заканчивается на счёте за API. В марте 2026 года Bugcrowd сообщил, что за три недели его очереди выросли более чем на 334% даже без учёта легитимных отчётов из обычной работы исследователей. Компания связала рост с массовыми отчётами с низкой уверенностью: тонкими доказательствами, шаблонными описаниями и отсутствием проверки перед отправкой.
В мае Bugcrowd добавил новые ограничения: обязательную верификацию личности для управляемых bug bounty программ, throttling для слабых аккаунтов, CAPTCHA и санкции против ферм отправки отчётов. Это не про токены. Это про то, что дешёвая генерация отчётов переносит стоимость на людей, которые должны читать, проверять, отклонять и объяснять.
Linux столкнулся с похожей проблемой в другом виде. 18 мая 2026 года Tom's Hardware пересказал сообщение Линуса Торвальдса в LKML: закрытая security mailing list стала почти неуправляемой из-за дублирующихся отчётов об уязвимостях, сгенерированных ИИ. В статье также приводится оценка Willy Tarreau: список, который два года назад получал примерно 2-3 отчёта в неделю, теперь получает 5-10 в день. Даже когда находки не полностью мусорные, повторяемость ломает triage.
Nextcloud в апреле 2026 года тоже остановил bug bounty program после всплеска отчётов, сгенерированных ИИ. По словам Jos Poortvliet, инженерная команда стала тратить на отчёты в 20-30 раз больше времени, чем раньше, причём большая часть была redundant, invalid или бессмысленной.
Эти кейсы не связаны напрямую с Open Agent Leaderboard. Они показывают другой слой той же экономики: слабый AI-процесс может быть дешёвым для отправителя и дорогим для всех остальных. Если агент генерирует невалидный отчёт, плохой pull request или ошибочную заявку в поддержку, стоимость провала уезжает в очередь людей.
Как читать Open Agent Leaderboard командам
Практический вывод простой: agent benchmark должен отвечать не на один вопрос, а минимум на четыре.
- Какой процент задач система закрывает без ручного вмешательства?
- Сколько стоит успешный запуск и сколько стоит неудачный?
- Где именно система ломается: выбор инструмента, планирование, память, остановка, восстановление после сбоя?
- Сколько человеческого triage появляется после провала?
Если команда видит только долю успешных запусков, она оптимизирует красивую цифру. Если видит только стоимость токенов, она выбирает дешёвую модель и пропускает дорогие провалы. Если видит оба измерения, появляются нормальные инженерные решения: ограничить набор инструментов, добавить tool shortlisting, логировать причины остановки, отделять быстрый отказ от длинного бесполезного прогона.
Это хорошо стыкуется с темой tool-use tax у LLM-агентов. Лишний tool-calling может ухудшать reasoning и экономику рабочего процесса. Open Agent Leaderboard показывает соседнюю мысль на уровне систем: одна и та же модель может стать дороже или дешевле в зависимости от того, как её заставили действовать.
Главное
Open Agent Leaderboard стоит читать не как спортивную таблицу, а как раннюю попытку измерять AI-агентов ближе к реальности. В реальности агент — это не модель в вакууме. Это связка модели, инструментов, протокола, памяти, восстановления после ошибок и людей, которые разгребают последствия.
Самый полезный тезис проекта звучит почти бухгалтерски: качество AI-агента нужно считать вместе со стоимостью провалов. Если неудачные запуски длиннее, дороже и требуют ручного triage, они становятся частью оценки системы. Для продакшена это важнее, чем ещё один процентный пункт в абстрактном benchmark.
Источники и проверка фактов
Факты, даты, цифры и изображения в материале проверены 27 мая 2026 года. Данные leaderboard и состав моделей могут измениться после этой даты.
- Hugging Face / IBM Research: The Open Agent Leaderboard, опубликовано 18 мая 2026 года.
- Hugging Face: Open Agent Leaderboard organization card, проверено 27 мая 2026 года.
- arXiv: General Agent Evaluation, submitted 26 February 2026, revised 11 May 2026.
- Bugcrowd: policy changes to address AI slop submissions, опубликовано 10 марта 2026 года.
- Bugcrowd: continuing our work to reduce AI slop submissions and protect signal quality, опубликовано 18 мая 2026 года.
- Tom's Hardware: Linus Torvalds says duplicate AI-generated vulnerability reports made Linux security list almost unmanageable, обновлено 18 мая 2026 года.
- Cybernews: Nextcloud's AI breaking point, опубликовано 23 апреля 2026 года.



