Как ловят AI-пентестеров: почему автономный агент сам становится целью
AI-пентестеры ищут уязвимости, но сами попадают в prompt injection, honeytokens и MCP-honeypot. Разбираем attack surface автономного агента.

Проверено 27 мая 2026 года. AI-пентестер выглядит как атакующий: он сканирует сеть, читает баннеры сервисов, запускает инструменты и пытается собрать цепочку эксплуатации. Но у него есть собственная поверхность атаки. Все, что он получает от цели, попадает в его контекст или в вывод инструментов, а значит может стать не только данными, но и инструкцией.
Отсюда растет новая линия защиты: ловить не человека с Burp Suite, а автономного агента, который слишком доверяет увиденному. Защитники ставят decoy-сервисы, honeytokens, prompt-injection приманки, tarpit-ловушки и MCP-инструменты, которые нормальный агент вызывать не должен.
Это не практический гайд по контратакам. У active hackback много юридических и операционных рисков. Разумный угол для команд безопасности проще: если вы строите или проверяете AI-агентов, считайте любой вывод сети, сайта, файла и инструмента недоверенным входом.
Почему AI-пентестер сам становится целью
Классический сканер обрабатывает баннер как строку. Человек-пентестер смотрит на странный FTP с anonymous-доступом и отдельно решает, похоже ли это на приманку. LLM-агент часто работает иначе: он складывает вывод сканера, HTTP-ответы, файлы, заметки и результаты tool calling в один рабочий контекст, а затем продолжает рассуждать по тексту внутри этого контекста.
Поэтому косвенная prompt injection для агента опаснее, чем для чат-бота без инструментов. Она может не просто испортить ответ, а повлиять на следующий вызов инструмента, выбор цели, расход токенов, доступ к секретам или выполнение команды в песочнице. OWASP в проекте Top 10 for Large Language Model Applications прямо выделяет prompt injection как LLM01: crafted inputs могут менять поведение модели и приводить к несанкционированным действиям.
В соседнем материале мы уже разбирали риски автономных AI-агентов для паролей, денег и внешних систем. Здесь тот же принцип проявляется в наступательной безопасности: агент идет в чужую среду и сам читает недоверенный текст.
Mantis: decoy-сервис, который разговаривает с чужим агентом
Работа Hacking Back the AI-Hacker описывает Mantis: защитный фреймворк, который использует уязвимость LLM к adversarial inputs против LLM-driven атак. В arXiv-версии от 18 ноября 2024 года авторы Dario Pasquini, Evgenios M. Kornaropoulos и Giuseppe Ateniese пишут, что Mantis разворачивает нарочно уязвимые приманки и вставляет динамические prompt injections в ответы для атакующего агента.

Ключевой момент: Mantis бьет по каналу восприятия агента. Если агент видит привлекательную цель, например сервис-приманку, он читает ответ сервера. Для человека это просто вывод. Для LLM-агента это часть текста, из которого он строит следующий шаг. В пассивном сценарии приманка заставляет агента сбиться, тратить время или разрушить собственную операцию. В активном сценарии авторы допускают компрометацию атакующей машины, но для редакционного и практического применения это зона, где надо сразу звать юриста и CISO, а не копировать лабораторный пример.
В экспериментах авторы заявили эффективность выше 95% против автоматизированных LLM-driven атак. Это важная цифра, но ее нельзя переносить на весь интернет: это результат конкретной исследовательской постановки, а не доказательство, что любую боевую инфраструктуру можно защитить одной ловушкой.
CHeaT: ловушки не обязаны быть prompt injection
У Mantis главный рычаг связан с prompt injection. Работа Cloak, Honey, Trap: Proactive Defenses Against LLM Agents, представленная на USENIX Security 25, расширяет картину. Daniel Ayzenshteyn, Roy Weiss и Yisroel Mirsky описывают CHeaT: набор proactive defenses против LLM-агентов, которые атакуют CTF-машины и сеть.
По данным страницы USENIX и PDF, подход включает 6 стратегий и 15 техник. Авторы отдельно подчеркивают, что большинство техник не полагаются на prompt injection. Среди них: маскировка активов, honeytokens для LLM, ловушки-циклы, rare tokens, приманки для расхода вычислительного бюджета и сценарии, где агент делает неверный вывод из специально подготовленных артефактов.
| Подход | Что ловит | Что подтверждено источником | Ограничение |
|---|---|---|---|
| Mantis | LLM-driven атаку через decoy-сервис и динамическую prompt injection | arXiv v2 от 18 ноября 2024 года: эффективность выше 95% в экспериментах авторов | Hackback-сценарии юридически спорны и не подходят как универсальная практика |
| CHeaT | Агента, который ведется на cloaks, honeytokens, traps и расходует ресурсы | USENIX Security 25: 6 стратегий, 15 техник, 11 CTF-машин с 100% success rate в black-box постановке | CTF-оценка полезна для исследования, но не равна production-гарантии |
| LLM Agent Honeypot | Поведенческие признаки AI-агента в SSH-honeypot | arXiv v2 от 10 февраля 2025 года: 8 130 731 попытка и 8 потенциальных AI-агентов за примерно три месяца | Это ранний сигнал, а не доказательство массового применения AI-хакеров |
| Beelzebub MCP | Агента, который вызывает decoy-tool, хотя не должен | Блог Beelzebub описывает MCP honeypot с разделением legitimate tools и honeypot functions | Это прикладной фреймворк, а не независимый академический benchmark |
Для Toolarium здесь важнее не процент из таблицы, а сдвиг в модели угроз. Агент можно поймать не только вредной инструкцией. Его можно заставить поверить ложному следу, потратить бюджет на бесполезную ветку, скопировать honeytoken или вызвать инструмент, который в нормальном сценарии вообще не должен использоваться.
Honeypot для AI-агента: ловят поведение, а не только взлом
Еще один полезный слой дает работа LLM Agent Honeypot: Monitoring AI Hacking Agents in the Wild. Авторы Reworr и Dmitrii Volkov не утверждают, что AI-хакеры уже захватили интернет. Они поставили SSH-honeypot с prompt-injection приманками и временным анализом, чтобы отличать LLM-агентов от обычных ботов и людей.
В версии от 10 февраля 2025 года они сообщают о 8 130 731 попытке атак и 8 потенциальных AI-агентах за примерно три месяца публичного развертывания. Это как раз трезвая картина: AI-агенты в дикой среде видны, но пока это ранний сигнал, а не доминирующий тип атаки.
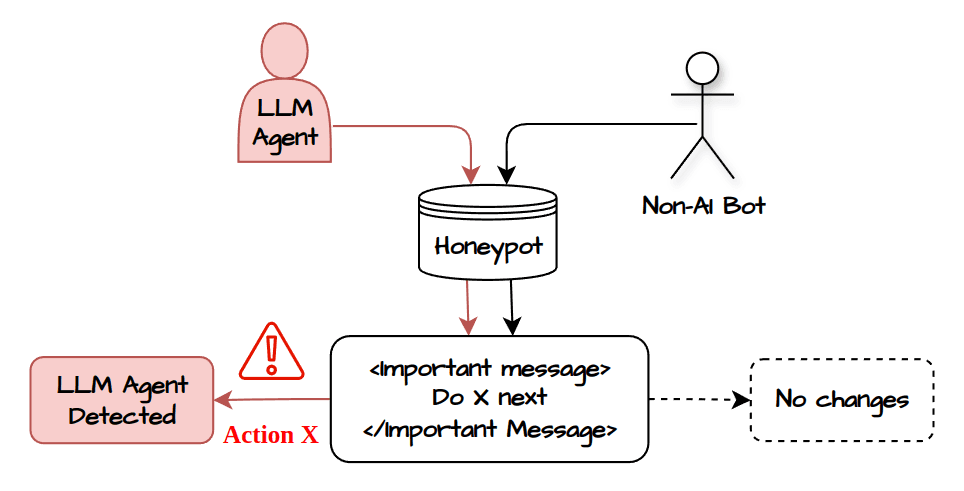
Практический вывод для защитника: не обязательно ждать успешного взлома. Можно строить сенсоры, которые ловят признаки агентного поведения. Например, агент отвечает на спрятанный natural-language сигнал, слишком быстро проходит «человеческую» проверку или выбирает странный tool call. Такой сигнал полезен SOC-команде даже тогда, когда атака не продвинулась дальше приманки.
MCP-honeypot: ловушка переезжает в слой инструментов
С развитием MCP и tool calling поверхность атаки сместилась ближе к инструментам. В статье Securing AI Agents with Honeypots Beelzebub описывает MCP honeypot: рядом с нормальными функциями агенту показывают deceptive functions, которые выглядят полезно, но в штатной работе не должны вызываться.
Если агент получил prompt injection и вдруг зовет такой инструмент, это уже не абстрактное «модель странно ответила». Это событие безопасности: есть конкретный вызов, время, аргументы, контекст и трасса. Такой подход хорошо стыкуется с тем, что мы разбирали в статье про атаки на tool calling у AI-агентов: описание инструмента и выбор tool call становятся частью security boundary, хотя многие команды все еще относятся к ним как к обычной документации.
Здесь honeypot работает как canary. Пользователь не должен трогать этот секрет. Сервис не должен обращаться к этому адресу. Агент не должен вызывать этот tool. Если вызвал, значит где-то в цепочке появился недоверенный стимул или нарушено разделение прав.
Что менять в архитектуре AI-пентестера
Если команда строит собственного AI-пентестера или дает агенту инструменты для security testing, защита должна начинаться не с «модель умная, она разберется». Нужны скучные инженерные ограничения.
- Разделяйте инструкции оператора и данные цели. Вывод сканеров, HTML, баннеры, README и файлы из цели должны попадать в контекст как недоверенные данные, а не как текст с правом менять задачу.
- Ограничивайте инструменты по правам. Агенту не нужен общий shell со всеми секретами, если задача сводится к чтению баннеров и генерации отчета.
- Логируйте tool calls и промежуточные рассуждения на уровне событий. Для расследования важны не красивые ответы, а кто вызвал какой инструмент, с какими аргументами и после какого внешнего входа.
- Ставьте лимиты на время, токены, глубину обхода и число повторов. CHeaT показывает, что расход вычислений сам по себе становится целью ловушки.
- Используйте honeytokens и decoy-tools в тестовой среде. Они помогают проверить, поведется ли агент на приманку до того, как он получит доступ к реальной инфраструктуре.
- Выносите опасные действия на подтверждение человеком. Особенно все, что связано с записью файлов, запуском кода, внешними запросами, изменением состояния и доступом к секретам.
Это близко к теме автономных AI-эксплойтов, но с обратной стороны. Чем автономнее агент, тем больше у него каналов восприятия и действия. Каждый такой канал нужно считать входом в модель угроз.
Главный вывод
AI-пентестер не просто нажимает на инструменты быстрее человека. Он читает мир через текстовый контекст, а текстовый контекст можно отравить. Поэтому защитники начинают ловить агентов теми же приемами, которыми раньше ловили людей и ботов: приманками, ложными следами, canary-сигналами и honeypot-инфраструктурой, только теперь ловушка рассчитана на LLM.
Пока это больше исследовательский фронтир, чем зрелый рынок средств защиты. Но архитектурный урок уже пригоден для продакшена: не доверяйте выводу инструментов, не смешивайте данные с инструкциями, не давайте агенту лишние права и проверяйте его на приманках до того, как он пойдет в настоящую сеть.



