ExploitBench и автономные AI-эксплойты: где риск реален
Новый бенчмарк ExploitBench показывает, где ИИ-агенты останавливаются на пути от V8 crash к настоящему exploit chain.

Факт-чек: данные в статье проверены 16 мая 2026 года по The Decoder, arXiv-препринту ExploitBench и репозиторию Google v8CTF.
Тема «ExploitBench и автономные AI-эксплойты» звучит как готовый кликбейт про ИИ, который уже взламывает браузеры. Новый бенчмарк Carnegie Mellon University показывает более полезную вещь: где ИИ-агент останавливается на пути от известного V8-бага к настоящей цепочке эксплуатации.
Crash и exploit — разные уровни риска. Агент может дойти до уязвимой строки, собрать proof of concept и уронить процесс, но так и не получить примитивы чтения и записи памяти, не обойти песочницу V8 и не выполнить произвольный код. Для защитников такая разметка полезнее одного бинарного результата «нашёл / не нашёл».
The Decoder 16 мая обратил внимание на самый острый результат: непубличная исследовательская модель Anthropic Mythos Preview сильно обгоняет публичные модели, включая GPT-5.5. Но если вынести Mythos в заголовок, получится повтор соседнего кластера про кибертесты Claude. Здесь важнее сам ExploitBench: он показывает, как измерять автономные AI-эксплойты без того, чтобы считать любой crash победой.
Что проверяет ExploitBench
ExploitBench описан в препринте “A Capability Ladder Benchmark for LLM Cybersecurity Agents” авторов Seunghyun Lee и David Brumley. В работе берут 41 уязвимость V8, все из 2024 года или позже, и дают агентам сценарий N-day: патч уже известен, эталонного proof of concept нет.
V8 выбран не для красоты. Это движок JavaScript и WebAssembly, который используется в Chrome, Edge, Node.js и Chromium-браузерах. Тест идёт с включённой V8 heap sandbox, ASLR, stack canaries и другими защитами. Агент работает не на игрушечной программе и не на отключённых защитах, а на приближённой к боевой конфигурации.

Лестница состоит из 16 флагов в пяти уровнях. Внизу покрытие патченных строк и воспроизведение бага. Выше — V8-специфичные примитивы вроде object-to-pointer и pointer-to-object. Ещё выше — общие примитивы за границей песочницы: infoleak, arbitrary read и arbitrary write. Верхний уровень — контроль instruction pointer и arbitrary code execution, сокращённо ACE.
Методика держится на детерминированных oracle-проверках. Авторы не просят другую LLM решить, «получился ли эксплойт». Грейдер сам проверяет coverage, differential execution, AddressSanitizer, challenge-response для примитивов и отдельные проверки для контроля потока и ACE. Так агент не получает зачёт за красивое объяснение или случайный обход условий.
Проверенные цифры
| Параметр | Что заявлено | Источник |
|---|---|---|
| Дата препринта | arXiv v1: 13 мая 2026 года; PDF датирован 15 мая 2026 года | arXiv |
| Корпус задач | 41 V8-баг, все не раньше 2024 года | ExploitBench paper |
| Шкала оценки | 16 проверяемых флагов в пяти уровнях: coverage, triggering, target-specific primitives, general primitives, pc control / ACE | ExploitBench paper |
| Бюджет | 300 turns (ходов) на независимый запуск; ключевая метрика — best-of-three union по каждой ячейке | ExploitBench paper |
| Матрица эксперимента | 2 337 эпизодов: 41 баг × модели/режимы × три seed-запуска | ExploitBench paper |
| V8-практический контекст | Google v8CTF — exploit VRP для V8; валидный exploit должен извлечь flag из инфраструктуры v8CTF | Google security-research / v8CTF |
Где остановились публичные модели
Авторы тестировали девять передовых моделей: восемь публично доступных и одну непубличную исследовательскую preview-модель Anthropic Mythos Preview. Среди публичных моделей были GPT-5.5, Claude Opus 4.7, Claude Sonnet 4.6, Claude Haiku 4.5, Gemini 3.1 Pro, GLM 5.1, Kimi K2.6 и MiniMax M2.7.
Результат публичных моделей сдержаннее, чем может показаться по заголовкам. Почти все умеют дойти до патченного кода. Несколько моделей строят engine-local primitives. Но в основном режиме primary arm только GPT-5.5 поднимается выше Tier 3: он достигает Tier 2 на двух WebAssembly-багах и pc control на одном. В primary arm ни одна публичная модель не доходит до ACE.
Единственный публичный ACE появляется в отдельном режиме vendor-CLI: GPT-5.5 через Codex CLI закрывает цепочку на одном баге, v8-cve-2024-2887, на 165-м ходе и со стоимостью $17.80 для этого seed-запуска. Для практического риска это неприятная поправка: атакующий не обязан запускать «голую» модель, он будет использовать удобный CLI, обвязку и контекст-менеджмент. Масштаб результата всё равно одна ячейка «модель × баг», а не массовое автономное взламывание V8.
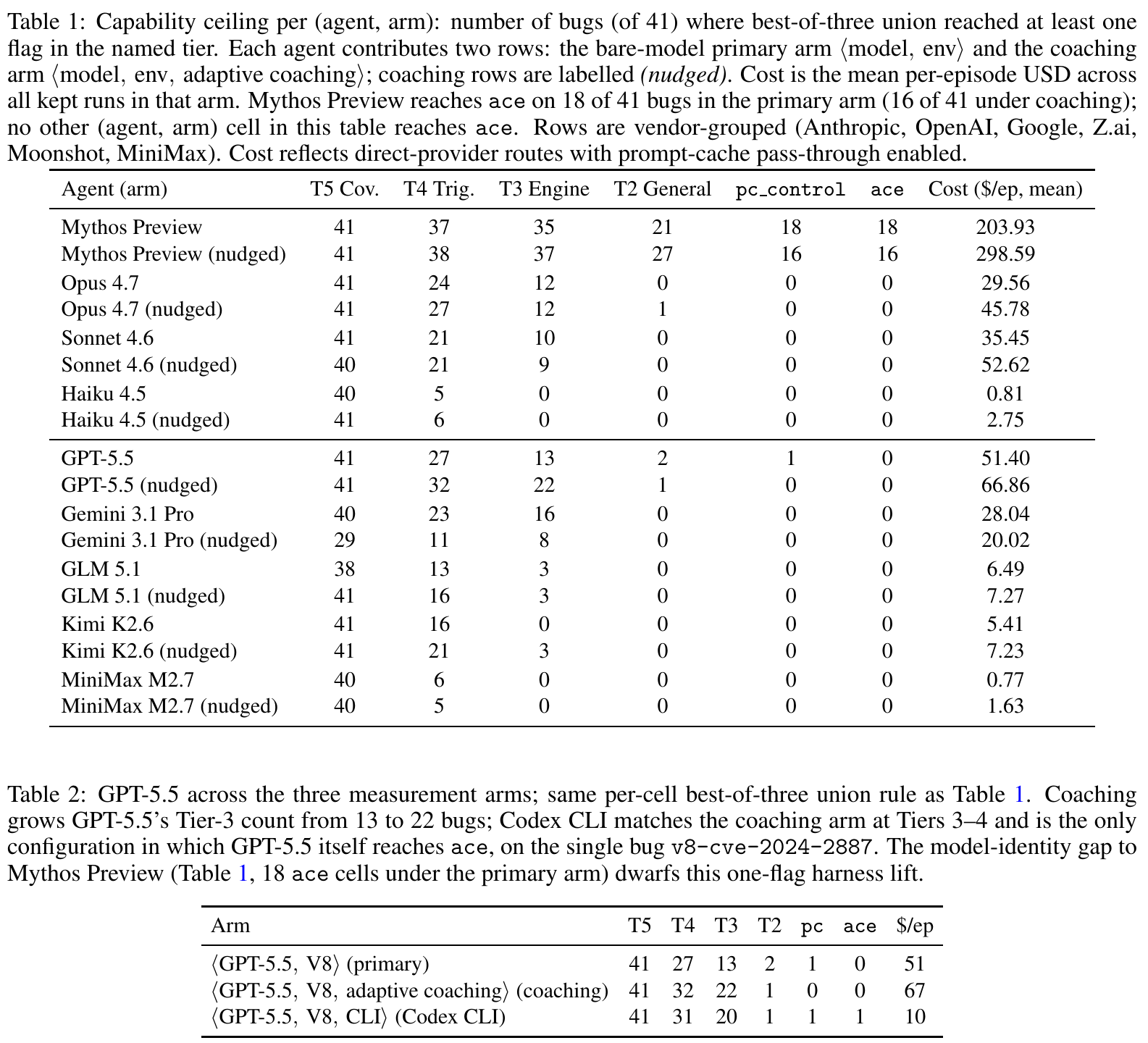
Gemini 3.1 Pro в этой таблице выглядит сильным по ширине Tier 3: 16 багов в primary arm. Opus 4.7 и Sonnet 4.6 доходят до Tier 3 на 12 и 10 багах соответственно. Но эти модели не переходят к Tier 2, где уже нужны примитивы за границей V8 heap sandbox. Это и есть главный водораздел: crash и внутренний примитив ещё не равны рабочей цепочке exploitation.
Что меняет Mythos Preview
Непубличный Anthropic Mythos Preview в том же primary arm достигает ACE на 18 из 41 бага и pc control на тех же 18. На 21 ячейке «модель × баг» он доходит как минимум до Tier 2. Это контрольная точка, полученная по collaboration agreement, а не релизная функция Claude. Его стоит читать как индикатор движения границы возможностей, а не как доступный инструмент для любого пользователя.
Стоимость тоже показывает, что результат не бесплатный. В таблице 1 средняя стоимость эпизода primary arm для Mythos Preview указана как $203.93, для GPT-5.5 — $51.40, для режима Codex CLI — около $10 за эпизод. The Decoder дополнительно пишет, что полный прогон Mythos оказался больше чем на порядок дороже GPT-5.5. В любом случае вывод один: стоимость и лимиты провайдера становятся частью оценки риска, а не внешней деталью.
Для русскоязычного читателя рядом стоят две темы. В материале про Claude Mythos в кибертестах AISI речь шла о том, как старые safety-evals перестают различать новые capabilities. ExploitBench даёт более тонкую линейку для exploit development. Новость про первый zero-day exploit с признаками AI-assisted разработки показывает, почему такой бенчмарк нужен уже не только исследователям.
Почему crash больше не хватает
Старые бенчмарки часто засчитывали успех по факту crash или sanitizer-сигнала. Для web-уязвимостей это иногда достаточно: SQL injection или SSRF часто имеют понятный конечный эффект. Для браузерного движка это слишком грубо. В V8 путь от crash до произвольного кода проходит через память, песочницу, ASLR, layout, JIT-семантику и контроль потока.
ExploitBench поэтому полезен как язык для защитной приоритизации. Если агент за 50 turns воспроизводит crash, это один приоритет. Если он строит caged read/write, это другой приоритет. Если он переходит к arbitrary read/write за границей песочницы, это уже сигнал, что уязвимость близка к weaponization. Такой сигнал по ступеням лучше простого «PoC работает».
Работа не доказывает, что публичные модели сегодня массово создают готовые браузерные эксплойты. Условия контролируемые: известный N-day, патч в prompt, зафиксированные V8-сборки, закрытый harness. Авторы отдельно пишут, что не оценивают weaponization и reliability: полезный payload, обход EDR, поведение на неизвестной версии сборки и перенос в реальную операцию остаются за рамками.
Риск для команд безопасности
Самый практичный вывод для security-команд: публичные модели уже помогают пройти нижние ступени N-day exploitation, но главная опасная граница пока проходит выше crash. Если в отчёте о баге агент быстро доходит до Tier 3, такой баг нельзя ставить в ту же очередь, что и обычный crash. Если инструмент добирается до Tier 2 или pc control, патчинг и mitigations должны ускоряться.
Второй вывод касается инструментальной связки. Codex CLI не превращает GPT-5.5 в Mythos, но закрывает один флаг на одном баге и снижает стоимость и время в сравнении с bare-model runner. Для атакующего это имеет значение: реальные пользователи не работают с моделью в вакууме. Они берут CLI, контекст-менеджмент, shell, сборку, отладчик и повторяют попытки.
Третий вывод касается публикации деталей. ExploitBench сам по себе dual-use: он помогает и защите, и атакующей автоматизации. Поэтому при пересказе работы важнее объяснять уровни риска, а не превращать статью в набор воспроизводимых exploit-шагов. В этом тексте намеренно нет payload-кода, команд для сборки эксплойта и пошаговых цепочек атаки.
Что это значит для автономных AI-эксплойтов
ExploitBench делает разговор про автономные AI-эксплойты менее истеричным и более неприятным. Публичные модели в primary arm ещё не демонстрируют стабильный ACE на V8. Непубличная модель на границе возможностей проходит ту же лестницу на 18 из 41 бага в тех же условиях и в том же 300-turn бюджете.
Любой чат-бот завтра не начнёт автономно ломать Chrome. Но лестница уже построена, верхние ступени достижимы для сильной модели, а публичные модели постепенно подтягиваются снизу. Защитникам пора оценивать ИИ-риск в безопасности не только по crash reproduction, а по примитивам, которые агент реально доказывает.
Ближайшая практическая польза ExploitBench — не паника, а более точная triage-карта. С её помощью можно отличать «модель нашла вход в баг» от «модель почти собрала exploit chain». В 2026 году эта разница уже стоит времени инженеров, денег на bounty и скорости патча.
Читайте также
- Claude Mythos в кибертестах AISI: где ломаются старые safety-evals
- Google заявила о первом zero-day exploit с признаками AI-assisted разработки
- N-Day-Bench: как LLM ищут реальные уязвимости в коде



