ИИ-инфляция оценок: почему ChatGPT ломает университетские баллы
Исследование UC Berkeley показывает: после ChatGPT доля A выросла на 13 п.п. в курсах, где много письменных, кодинговых и домашних заданий.
Проверено 21 июня 2026 года. ИИ-инфляция оценок — это рост высоких баллов после появления генеративного ИИ без такого же доказанного роста знаний. В университетских курсах, где много письменных, кодинговых и домашних заданий, ChatGPT может улучшать итоговую работу, но оценка всё хуже показывает самостоятельные навыки студента.
Новый working paper Игоря Чирикова из UC Berkeley показывает это на большом массиве данных: более 500 000 оценок в крупном исследовательском университете в Техасе за 2018-2025 годы. В курсах, где задания сильнее совпадают с возможностями ИИ, доля оценок A после запуска ChatGPT выросла на 13 процентных пунктов, примерно на 30% относительно базы 2022 года.
Из этих данных не следует, что все студенты стали учиться хуже или что каждый высокий балл получен нечестно. Более точный вывод: университетская оценка стала более шумным сигналом. Она всё чаще смешивает знания студента, качество подсказки к модели и способность сдать работу, созданную при помощи ИИ.
Что показало исследование UC Berkeley
CSHE Berkeley опубликовал working paper Artificial Intelligence and Grade Inflation в мае 2026 года. Автор анализирует сбалансированную панель из 319 курсов в 84 департаментах: всего 2 552 наблюдения курс-год и 507 076 студенческих зачислений с оценками за осенние семестры 2018-2025 годов.
Ключевой приём исследования — сравнить курсы с разной AI-exposure до и после появления ChatGPT. Экспозиция к ИИ измерялась не задним числом, а по структуре заданий из силлабусов Fall 2022, опубликованных до запуска ChatGPT 30 ноября 2022 года. Больше письма и кода в заданиях — выше вероятность, что генеративная модель сможет выполнить существенную часть оцениваемой работы.
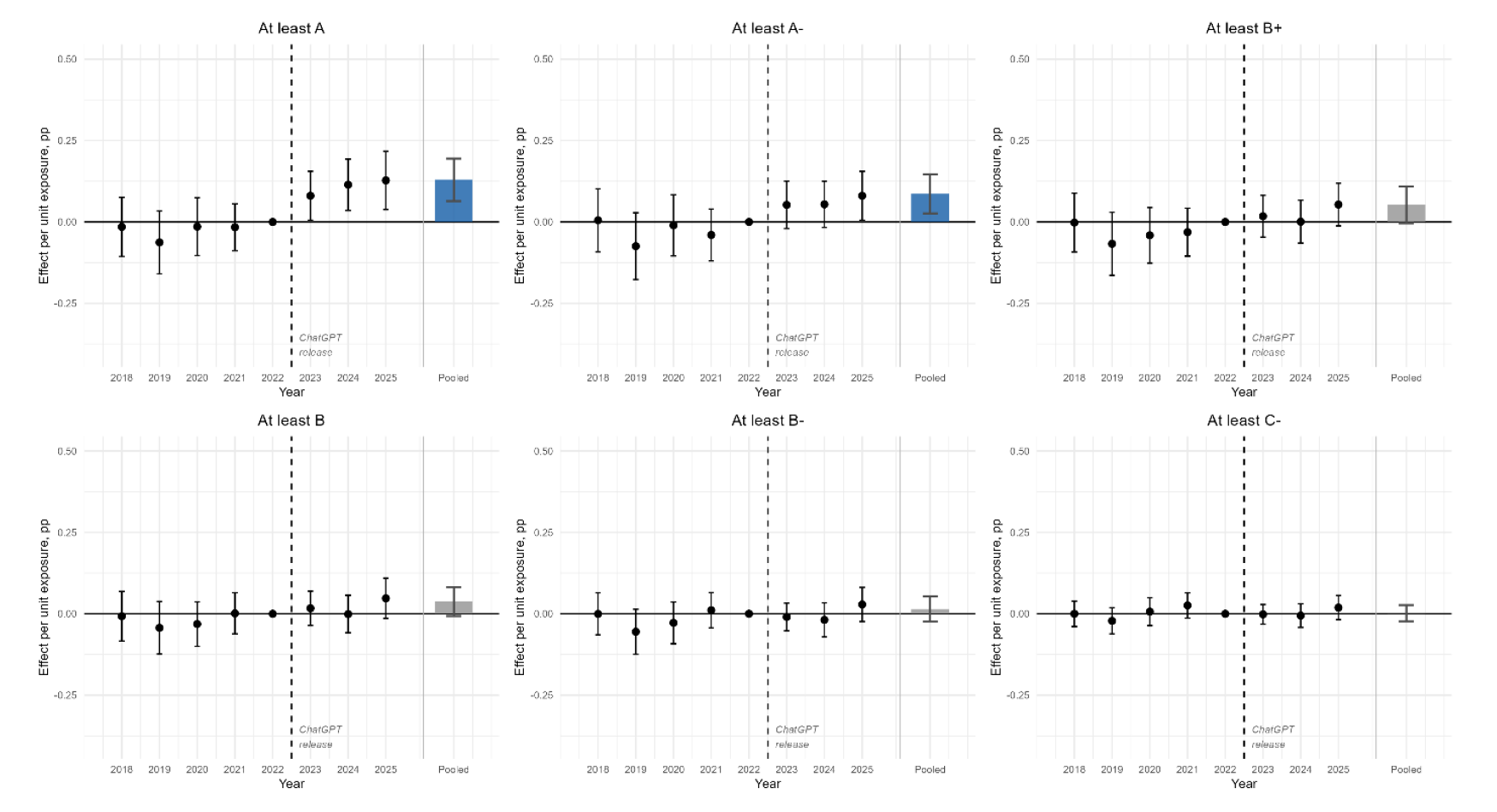
Именно в таких курсах после 2022 года оценочная кривая сдвинулась вверх. Доля A выросла на 13 п.п., средний GPA — на 0,12 пункта, а распределение оценок сжалось: заметнее всего подрос верх, а не весь диапазон сразу.
| Что изменилось | Почему это важно | Что проверять дальше |
|---|---|---|
| Доля A в AI-exposed курсах выросла на 13 п.п. | Оценка хуже разделяет самостоятельный навык и AI-assisted output. | Формат заданий: письмо, код, домашняя работа, проект. |
| Эффект сильнее там, где домашние задания весят больше. | ИИ получает больше пространства заменить работу студента вне аудитории. | Долю supervised-оценивания, устных защит и in-class заданий. |
| GPA остаётся сигналом для работодателей и магистратуры. | Отбор по баллам становится шумнее, особенно между курсами разного типа. | Портфолио, практические задания, интервью и защиту решений. |
| ИИ может помогать обучению, если встроен явно. | Проблема не в самом инструменте, а в старом дизайне оценки. | Правила раскрытия ИИ, процесс работы и критерии самостоятельности. |
Почему домашние задания стали слабым местом
Самая важная часть работы Чирикова — не общий рост A, а проверка механизма. Если ChatGPT действительно улучшал бы обучение в широком смысле, рост оценок должен был бы проявляться и там, где студент пишет работу дома, и там, где он отвечает в аудитории или сдаёт контролируемый экзамен.
Но данные указывают на другой сценарий. В курсах с большим весом домашних заданий эффект AI exposure по доле A оказался дополнительно выше примерно на 16 п.п. В курсах с меньшим весом домашних заданий эффект был маленьким и статистически неубедительным. Плацебо-проверка по устным презентациям тоже не показала такого сдвига.
Такой рисунок плохо похож на универсальное улучшение навыков. Он ближе к task displacement: модель берёт на себя часть работы, которую раньше должен был выполнять студент. Особенно там, где преподаватель оценивает итоговый артефакт — текст, код, аналитическую записку — и не видит, как он был создан.
Похожую проблему мы уже разбирали на другом кейсе: ИИ-агент получил 100% на Stepik, но высокий финальный балл там тоже скорее показывал способность пройти систему оценки, чем глубину знания. Университетские курсы сложнее, но логика та же: если оценочная среда проверяет только результат, сильный внешний инструмент меняет смысл результата.
Почему это не просто история про списывание
Свести всё к академической нечестности удобно, но слишком грубо. Студент может использовать ChatGPT по-разному: попросить объяснение, проверить черновик, найти ошибку в коде, сгенерировать план эссе или полностью переложить работу на модель. Снаружи эти сценарии часто выглядят одинаково: сданный текст стал лучше.
Вузу нужно не искать одну кнопку запрета, а понять, что именно оценивается. Если цель курса — научить писать аргументированный текст, невидимый генератор текста ломает проверку. Если цель — научить работать с ИИ как с профессиональным инструментом, задание должно требовать раскрытия процесса: промпты, версии, правки, источники, объяснение выбора.
OpenAI в марте 2026 года в материале о learning outcomes фактически признаёт ту же проблему с другой стороны: одних узких метрик вроде тестовых баллов мало, чтобы понять, как ИИ влияет на обучение со временем. Это полезная оговорка. Балл может вырасти, а самостоятельная практика — сократиться.
GPA становится менее чистым сигналом
Оценки давно были несовершенными. На них влияют сложность курса, стиль преподавателя, политика факультета, давление студенческих отзывов и культурная норма щедрого grading. Новое в генеративном ИИ то, что искажение появляется до проверки: меняется сам процесс производства оцениваемой работы.
Для работодателей и магистратур это неприятная новость. GPA и доля A не исчезнут завтра, но их придётся читать осторожнее. Два студента с одинаковым баллом могли пройти разные траектории: один много писал и ошибался сам, другой быстро собирал отполированный результат через модель. Транскрипт редко показывает эту разницу.
Для самих студентов риск тоже не только репутационный. Если ИИ закрывает именно те задания, на которых строится навык, человек получает балл без достаточной практики. В коротком горизонте это выгодно. В длинном — выпускник хуже пишет, хуже объясняет решение или слабее отлаживает код без подсказки модели.
Эти сюжеты лучше не смешивать. В широком материале про ИИ в образовании мы уже писали, что нейросети могут помогать преподавателям и студентам. Текущая проблема уже: конкретные типы заданий перестали надёжно показывать, кто чему научился.
Что университетам придётся менять
Простой откат к экзаменам в аудитории не решит задачу. Чириков в комментарии Times Higher Education отдельно подчёркивает: многие важные навыки нельзя хорошо проверить коротким контролируемым заданием. Исследовательская работа, приложение, аналитический проект или длинное эссе требуют времени. Если всё заменить экзаменом, вуз потеряет часть того, чему должен учить.
Практичный путь — пересмотреть курсы по AI-exposure и понять, где ИИ должен быть запрещён, где разрешён как инструмент, а где встроен в само задание. Для разных дисциплин ответ будет разным.
- Для базовых навыков нужны моменты независимой проверки: короткое письмо в аудитории, устная защита, live coding, разбор решения без подсказок.
- Для проектов стоит оценивать процесс, а не только финальный файл: черновики, журнал решений, историю коммитов, промпты, источники и объяснение правок.
- Для AI-integrated заданий нужно заранее описывать, какая помощь модели допустима и что студент обязан сделать сам.
- Для отбора за пределами университета всё больше будут значить портфолио, интервью и практические проверки, а не только GPA.
Студентам всё равно придётся пользоваться ИИ: инструмент уже вошёл в учёбу и работу. Но этичное использование ИИ для учёбы отличается от невидимой замены домашней работы. Университетам придётся формализовать эту границу.
FAQ: коротко
Что такое ИИ-инфляция оценок?
Это рост высоких оценок после появления генеративного ИИ без сопоставимого доказательства, что студенты стали лучше понимать предмет. В исследовании UC Berkeley эффект особенно заметен в курсах с письменными, кодинговыми и домашними заданиями.
Почему ChatGPT сильнее влияет на домашние задания, чем на экзамены?
Домашняя работа обычно выполняется без наблюдения. Модель может написать текст, помочь с кодом, исправить аргументацию или собрать черновик. На контролируемом экзамене или устной защите студенту сложнее незаметно переложить работу на ИИ.
Как университетам оценивать студентов, если они используют ИИ?
Нужна смесь форматов: независимые проверки для базовых навыков, оценка процесса для больших проектов и явные правила использования ИИ. Цель — не ловить каждого студента, а снова сделать оценку доказательством того, что человек действительно умеет делать.
Главный вывод
ИИ-инфляция оценок не означает, что ChatGPT уничтожил образование. Она показывает более конкретную поломку: старые задания стали плохо различать самостоятельную работу и результат, усиленный моделью. Пока университеты оценивают только финальный артефакт, доля A может расти быстрее, чем реальные навыки.
Рабочий ответ шире запрета. Вузам нужно перепроектировать оценивание так, чтобы ИИ был либо явно частью задачи, либо не мог незаметно заменить ключевую практику. Иначе GPA останется числом в транскрипте, но будет всё хуже отвечать на простой вопрос: что этот человек действительно умеет?



