DeepMind AI co-clinician: ИИ под контролем врача, а не вместо него
DeepMind показывает не «AI-врача», а исследовательскую систему под контролем врача. Разбираем, что подтверждено в blind-eval, RxQA и телемедицинских симуляциях.

По состоянию на 2 мая 2026 года Google DeepMind не показала миру «AI-врача» и не объявила продукт для самостоятельной диагностики. Она запустила исследовательскую инициативу AI co-clinician и довольно жёстко описала рамку: система должна работать под клиническим контролем врача, а не вместо него.
В этом и есть главный смысл новости. На рынке ИИ уже слишком много историй, где модель сначала побеждает в красивом тесте, а потом её пытаются мысленно дотащить до реальной практики. DeepMind делает другой ход. Она берёт передовую модель, помещает её в медицинский контур с высокой ценой ошибки и сразу показывает две вещи: где система уже помогает и где человек всё ещё сильнее.
Что именно объявила DeepMind 30 апреля
Официальный пост DeepMind от 30 апреля 2026 года строится не вокруг продажи, а вокруг нового клинического контура. В компании называют его triadic care: у пациента, врача и ИИ появляется общая рабочая связка, где модель помогает с поиском, объяснением и маршрутизацией, но клиническая власть остаётся у врача.
Это важно зафиксировать сразу, потому что именно здесь проходит граница между точным заголовком и дешёвым хайпом. Формулировки вроде «Google сделала AI-доктора» или «ИИ заменяет врачей» противоречат первоисточнику. DeepMind, наоборот, несколько раз подчёркивает, что исследовательские коллаборации на этой стадии не предназначены для диагностики, лечения, профилактики болезней или медицинских советов.
| Контур | Что подтверждено | Источник |
|---|---|---|
| Слепая оценка для врачей | В объективном анализе 98 реалистичных запросов первичной помощи система прошла 97 случаев без критических ошибок | Google DeepMind blog, 30 апреля 2026 |
| Лекарственные вопросы | В RxQA система набрала 73,3% против 72,7% у GPT-5.4-thinking-with-search, а в открытом формате — 95,0% против 90,9% | Google DeepMind blog, 30 апреля 2026 |
| Телемедицинские симуляции | Рандомизированная симуляция: 20 синтетических сценариев, 10 врачей, игравших пациентов, 120 гипотетических телемедицинских консультаций | Google DeepMind blog; technical report PDF |
| Сравнение с врачами | Экспертные врачи сильнее в целом, но AI co-clinician сопоставим или лучше врачей первичного звена в 68 из 140 оцениваемых аспектов | Google DeepMind blog, 30 апреля 2026 |
Где co-clinician уже показал пользу
Самая сильная часть анонса не в слове co-clinician, а в том, как DeepMind пыталась проверять систему. Для режима помощи врачу команда вместе с академическими врачами адаптировала фреймворк NOHARM, чтобы отслеживать не только явные ошибки, но и ошибки умолчания. В медицине это критично: иногда модель опасна не тем, что говорит лишнее, а тем, что не поднимает важный тревожный признак.
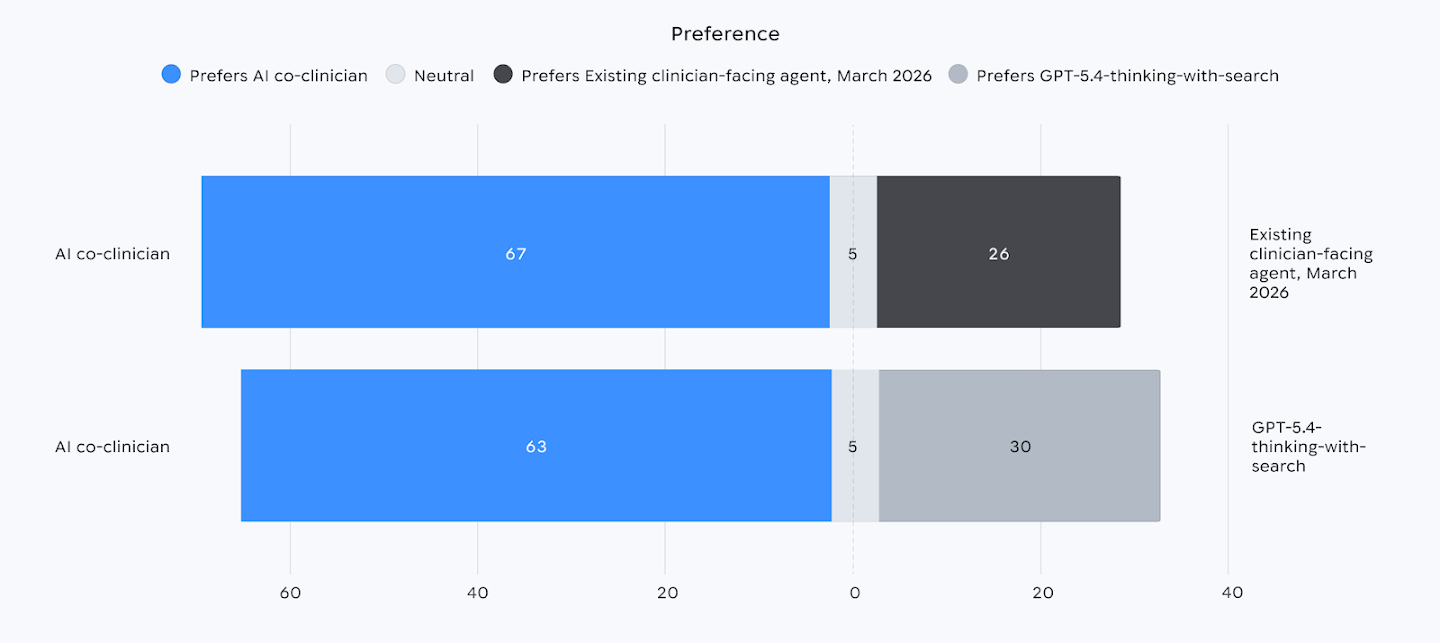
Дальше начинается то, что действительно можно считать прогрессом, а не маркетинговым украшением. В слепой оценке на 98 реалистичных запросах первичной помощи DeepMind пишет о zero critical errors in 97 cases, то есть один критический промах всё же остался. На официальном графике из того же анонса врачи предпочли ответы AI co-clinician существующему агенту для врачей в соотношении 67 к 26, а GPT-5.4-thinking-with-search — 63 к 30; ещё по 5 оценок в каждом сравнении были нейтральными. Для вопросов о лекарствах команда отдельно использовала RxQA: в тесте с выбором ответа AI co-clinician набрал 73,3%, GPT-5.4-thinking-with-search — 72,7%; в открытом формате разрыв вырос до 95,0% против 90,9%.
Именно здесь историю полезно читать не как очередной медицинский бенчмарк, а как попытку собрать прикладной слой поверх модели. Если обычный чат-бот отвечает «в общем похоже на норму», врачу от него мало пользы. Если система умеет быстро вытаскивать клинически релевантные данные, сверять ответ с клиническими источниками и не терять важные упущения, это уже другое качество инструмента.
Зачем DeepMind увела систему в телемедицину
Второй сильный блок анонса начинается там, где многие медицинские ИИ-системы обычно заканчиваются: не в текстовом чате, а в аудио-видео взаимодействии. DeepMind пишет прямо: медицина не сводится к тексту. Для клинической оценки важны голос, дыхание, моторика, внешний вид пациента, способность пройти простой физический тест на камеру.
Поэтому команда вместе с врачами из Harvard и Stanford собрала отдельное рандомизированное симуляционное исследование: 20 синтетических сценариев, 10 врачей, игравших пациентов, и 120 гипотетических телемедицинских эпизодов. В этом контуре AI co-clinician не просто отвечает на вопрос, а ведёт диалог в реальном времени, подсказывает действия и пытается извлекать сигнал из аудио и видео.
Здесь особенно ценно, что DeepMind не ограничилась абстрактной формулой «мультимодальность полезна». В официальном посте приведены конкретные примеры: система корректировала технику использования ингалятора и вела пациента через движения плеча, которые помогали распознать травму ротаторной манжеты. Это уже не история про красивое резюме разговора. Это история про то, как модель пытаются встроить в реальный сценарий удалённого осмотра.
Для Toolarium это ещё и хороший повод напомнить, чем такой контур отличается от общего разговора про AI-агентов. Здесь агентность нужна не ради самой оркестрации. Она нужна затем, чтобы система параллельно слушала, рассуждала, проверяла границы безопасности и при этом не теряла естественный темп разговора.
Где врачи всё ещё сильнее
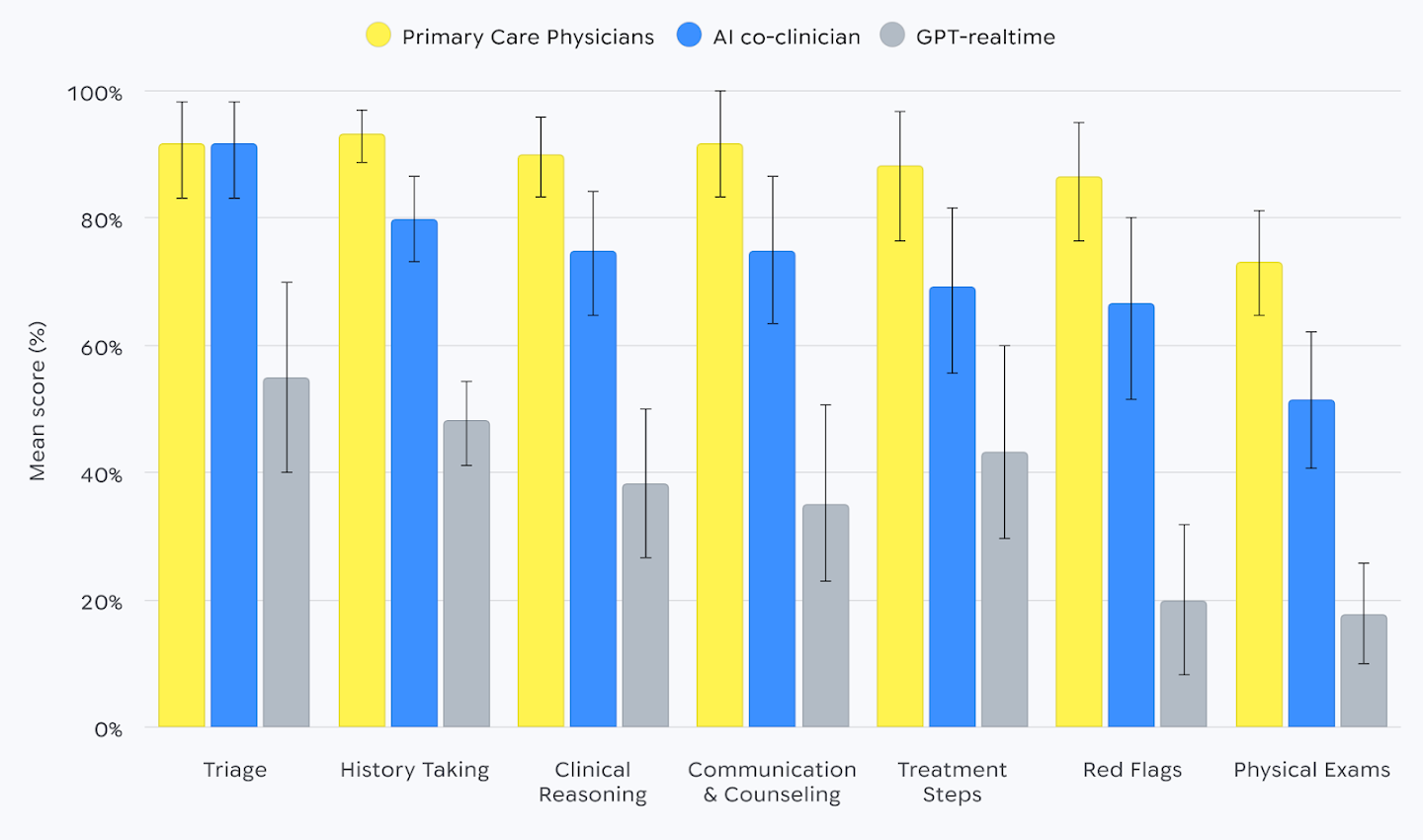
Самая честная часть материала DeepMind, как ни странно, и делает его сильнее. Компания не пытается продать мысль, что модель уже догнала врача. Наоборот, в реалистичных симуляциях экспертные врачи оказались лучше в целом, особенно там, где цена промаха максимальна: в поиске тревожных признаков (red flags) и в проведении критически важных физических тестов.
Эта оговорка меняет тон всей новости. Если бы DeepMind показала только результаты слепого сравнения и рост на RxQA, получился бы ещё один текст в духе «модель снова всех обошла». Но телемедицинский блок возвращает читателя на землю. Да, система прибавила. Да, она сопоставима или лучше врачей первичного звена в 68 из 140 аспектов. Но в клинике решает не средняя температура по палате, а то, что происходит на узких участках риска. И вот там человек пока устойчивее.
Это полезно читать в связке с другим сюжетом Toolarium: Isomorphic Labs готовит испытания на людях для ИИ-лекарств. В обоих случаях Google двигает ИИ в домены с высокой ценой ошибки не через лозунг «модель уже умнее специалиста», а через постепенную упаковку в дорогой, медленный и очень проверяемый контур. Разница только в объекте: там разработка лекарств, здесь помощь врачу.
Почему это история про guardrails, а не про «AI-врача»
DeepMind отдельно подчёркивает инженерный слой доверия. В телемедицинских симуляциях для пациентов AI co-clinician использует двухагентную архитектуру: модуль Clinical Planner непрерывно следит за ходом разговора и проверяет, не выходит ли Talker за безопасные клинические границы. В сценариях для врачей система делает ставку на клинические источники, проверку фактов и сверку ссылок при поиске данных.
Это и есть самый взрослый вывод из всей новости. На рынке передовых моделей уже трудно удивить тем, что система отвечает убедительно. Удивить можно другим: тем, что команда строит вокруг модели слой сдержек, проверок и явных ограничений. Такой подход не делает систему готовой к реальной медицине автоматически. Но он показывает, что хотя бы правильный вопрос поставлен верно: как не просто получить впечатляющий ответ, а вписать модель в контур, где ошибка дорогая и последствия нельзя списать на «ранний доступ».
По этой причине новость DeepMind не стоит смешивать с историей про передовые модели для биологии вообще. Например, в материале GPT-Rosalind: зачем OpenAI нужна модель для биологии фокус был на биомедицинских исследованиях и исследовательском стеке. Здесь другая задача: не поиск молекул и не научная гипотеза, а клиническая помощь человеку в контуре врача. Путать эти два класса систем значит терять самый важный смысл анонса.
Что дальше
Сильнее всего в этой истории то, что DeepMind сама не пытается её перепродать. В официальном посте прямо сказано: текущие исследовательские коллаборации не предназначены для диагностики, лечения, профилактики болезней или медицинских советов. То есть речь пока не о массовом запуске и не о приложении для пациентов, а о поэтапной проверке с академическими и медицинскими партнёрами в США, Индии, Австралии, Новой Зеландии, Сингапуре и ОАЭ.
Для русскоязычного читателя из ИТ здесь есть простой вывод. В доменах с высокой ценой ошибки выигрывает не та компания, которая первой объявит «замену специалиста», а та, которая научится упаковывать передовую модель в дисциплинированный рабочий контур. DeepMind сейчас показывает именно такую упаковку: слепую оценку, телемедицинские симуляции, двухагентную архитектуру, проверку фактов, сверку ссылок и несколько жёстких дисклеймеров поверх всего этого.
Поэтому заголовок у этой новости должен быть скучнее, чем мечтают хайповые медиа, и точнее, чем любят пресс-релизы. DeepMind не выводит «AI-врача». Она выводит AI co-clinician в контур врача. И на нынешней стадии это, честно говоря, куда интереснее.
Читайте также
- AI-агенты: что это, как работают и где дают результат
- Isomorphic Labs готовит испытания на людях для ИИ-лекарств
- GPT-Rosalind: зачем OpenAI нужна модель для биологии
Источники и дата проверки
- Google DeepMind: AI co-clinician: researching the path toward AI-augmented care, опубликовано 30 апреля 2026 года, проверено 2 мая 2026 года.
- Towards Conversational Medical AI with Eyes, Ears and a Voice, technical report, проверено 2 мая 2026 года.
- First, do NOHARM: towards clinically safe large language models, arXiv, проверено 2 мая 2026 года.
- Towards Conversational AI for Disease Management, arXiv, проверено 2 мая 2026 года.



