Cloudflare Pay Per Crawl: кто заплатит за AI-краулинг
Cloudflare хочет превратить AI-краулинг из бесплатного скрапинга в оплачиваемый доступ. Разбираем Pay Per Crawl, HTTP 402 и риски для веба.
Проверено 8 июня 2026 года. Cloudflare Pay Per Crawl — это функция AI Crawl Control, которая позволяет владельцу сайта назначить цену за доступ AI-краулера к странице. Если краулер готов платить, он получает обычный HTTP 200. Если нет, Cloudflare возвращает HTTP 402 Payment Required и передаёт цену в заголовке crawler-price.
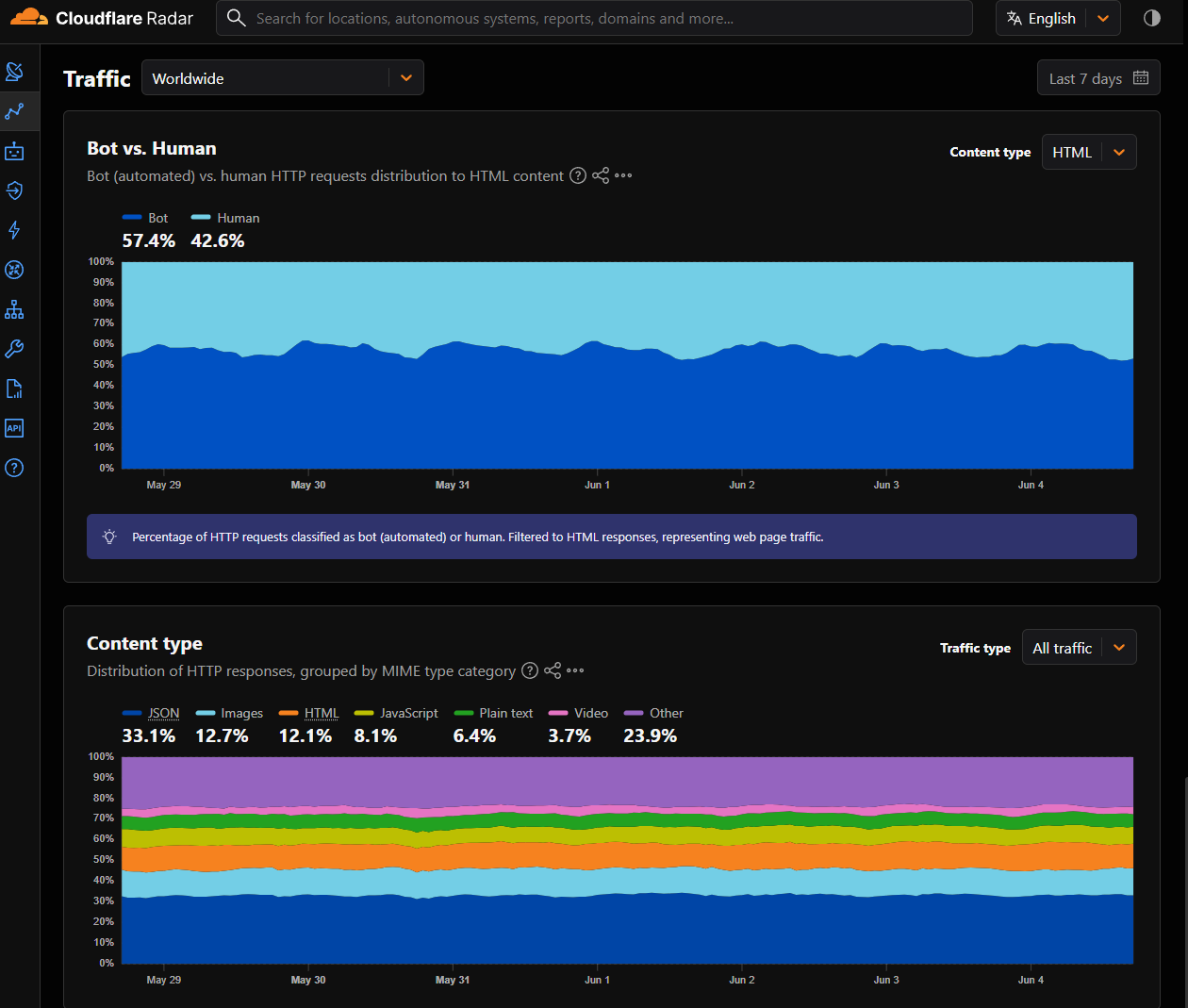
Повод свежий. 3 июня 2026 года сооснователь и CEO Cloudflare Мэтью Принс написал, что бот-трафик впервые обогнал человеческий. The Decoder на следующий день показал скриншот Cloudflare Radar: за последние 7 дней боты давали 57,4% HTTP-запросов к HTML-контенту, люди — 42,6%. Эту цифру нельзя читать как «в интернете уже больше ботов, чем людей». Метрика считает запросы к страницам, а не внимание, время чтения или число реальных пользователей.
Но для издателей и владельцев сайтов важен именно поток запросов. Старый обмен выглядел так: поисковик сканирует страницу, ранжирует её и возвращает читателей. AI-краулеры и агенты часто забирают ценность раньше клика: читают текст, пересказывают его в ответе, сравнивают цены, собирают факты для пользователя или модели. Cloudflare пытается встроить в этот процесс ценник.
Что именно предлагает Cloudflare
Pay Per Crawl появился 1 июля 2025 года как частная beta. В официальном блоге Cloudflare описывает его как третий режим между бесплатным доступом и блокировкой. Для каждого AI-краулера владелец домена может выбрать один из вариантов: разрешить, взять плату или заблокировать.
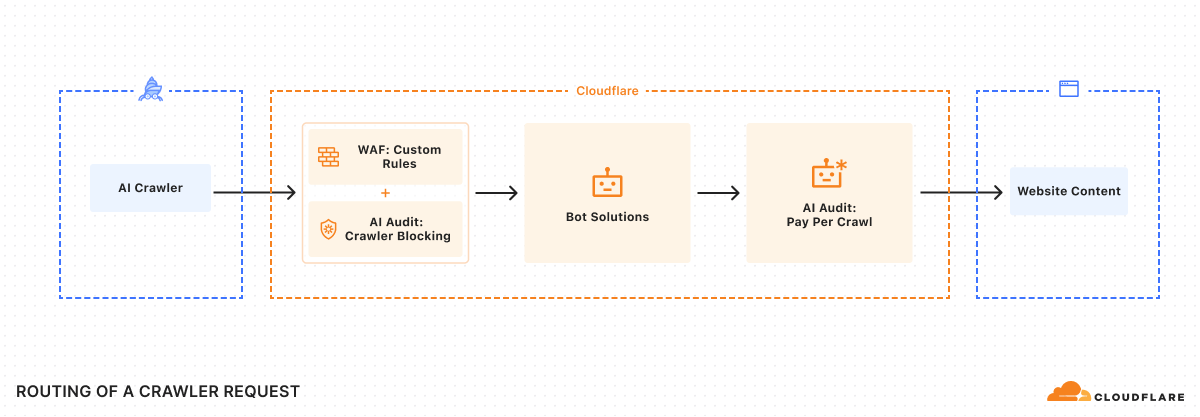
В документации Cloudflare схема выглядит так. Владелец сайта задаёт цену на уровне зоны. AI-краулер проходит проверку Web Bot Auth, делает запрос и либо заранее передаёт готовность заплатить через crawler-max-price, либо сначала получает HTTP 402 с crawler-price, а затем повторяет запрос с crawler-exact-price. Если всё совпало, Cloudflare отдаёт контент и фиксирует списание через crawler-charged. Сама Cloudflare выступает Merchant of Record, то есть техническим и платёжным посредником.
У этой конструкции есть важная деталь: правила WAF, Bot Management и явная блокировка сильнее, чем режим charge. Если сайт уже заблокировал краулер через защитные правила, Pay Per Crawl не превратит запрет в платный доступ. Сначала безопасность, потом коммерческая модель.
Почему это не просто новый robots.txt
Robots.txt всегда был скорее просьбой, чем контрактом. Хорошие краулеры его уважают, плохие обходят. Cloudflare строит Pay Per Crawl на уровне инфраструктуры: запрос проходит через edge-сеть, а ответ с оплатой возвращается как часть HTTP-обмена. Для честного краулера это машинно-читаемое правило. Владелец сайта получает способ сказать не только «нельзя», но и «можно, если платишь».
В июне 2026 года Cloudflare отдельно расширила AI Crawl Control: платные клиенты могут отправлять на заблокированных краулеров кастомный HTTP 402 с сообщением вроде «для лицензирования напишите сюда». Компания утверждает, что её клиенты уже отправляют больше миллиарда таких 402-ответов в средний день. Это ещё не миллиард оплаченных обходов. Скорее сигнал, что владельцы сайтов хотят заменить молчаливую блокировку коммерческим маршрутом.
Эта тема пересекается с тем, что мы уже разбирали в материале про AI-ботов и новый налог на открытый веб. Там проблема была в нагрузке и невидимых расходах инфраструктуры. Здесь добавляется вопрос цены контента: если AI-система получает данные без перехода пользователя на сайт, кто платит за производство этих данных?
Старая сделка веба ломается на соотношении crawl/referral
Самый сильный аргумент Cloudflare не в статус-коде 402, а в изменении обмена между краулером и издателем. На мероприятии Axios в июне 2025 года Принс приводил жёсткие соотношения: десять лет назад Google, по его словам, сканировал две страницы на каждого отправленного посетителя. В 2025 году он говорил уже о 18:1 для Google, 1500:1 для OpenAI и 60 000:1 для Anthropic. Это заявление Cloudflare, а не независимый аудит, но оно хорошо объясняет раздражение издателей.
Когда краулер забирает тысячи страниц и почти не возвращает людей, рекламная модель сайта слабеет. AI Overviews, AI Mode, чат-боты и агентные ответы могут ссылаться на источники, но пользователь часто получает достаточно информации прямо в интерфейсе AI. Мы уже видели похожий конфликт в истории про требование отдельного opt-out для Google AI Search: издатели хотят отличать обычный поиск от AI-ответов, потому что ценность перехода меняется.
| Модель | Кто получает ценность | Кто платит | Главный риск |
|---|---|---|---|
| Классический поиск | Поисковик индексирует сайт, сайт получает переходы | Пользовательское внимание и реклама | Падение органического трафика |
| AI-краулинг без оплаты | AI-система получает текст, факты и свежие страницы | Владелец сайта оплачивает производство и нагрузку | Контент становится сырьём без компенсации |
| Cloudflare Pay Per Crawl | Краулер получает доступ по заданной цене | Оператор краулера через Cloudflare | AI-компании могут не принять рынок или обходить его |
Кому это выгодно
Для крупных издателей Pay Per Crawl выглядит как попытка масштабировать лицензионные сделки. Сейчас дорогие соглашения с AI-компаниями доступны в основном большим медиа и правообладателям. Cloudflare предлагает более мелкую единицу учёта: не многолетний контракт, а цена за запрос. По данным TechCrunch, в запуске 2025 года участвовали или поддержали permission-based подход крупные издатели и правообладатели, включая Condé Nast, TIME, Associated Press, The Atlantic, ADWEEK и Fortune.
Для небольших сайтов выгода менее очевидна. Cloudflare даёт рычаг: можно отличать поисковый краулер от AI training crawler, AI search crawler или агента, который действует от имени пользователя. Но маленькому сайту всё равно нужно решить, какую цену ставить, кого пускать бесплатно и что делать с ботами, которые не хотят подписывать запросы.
AI-компаниям Pay Per Crawl даёт легальный и технически понятный маршрут к контенту. Но это маршрут с издержками. Пока бесплатный скрапинг работает, мотивация платить появится только там, где источник достаточно ценен, блокировка достаточно сильна, а репутационный или юридический риск заметен.
Где слабые места Pay Per Crawl
Главное ограничение — статус продукта. По состоянию на 8 июня 2026 года документация Cloudflare всё ещё называет Pay Per Crawl closed beta. Это не массовый стандарт веба, а эксперимент с частным доступом.
Дальше начинается вопрос принятия рынком. TechCrunch ещё при запуске отмечал, что убедить AI-компании платить будет трудно: многие уже получают контент бесплатно. Cloudflare может обслуживать значительную часть веба, но ей всё равно нужны обе стороны сделки: владельцы сайтов и операторы краулеров.
Отдельная проблема — разные виды ботов. Поисковый робот, crawler для обучения модели, AI search crawler и браузерный агент пользователя ведут себя по-разному. Если всё назвать «ботами» и закрыть одним правилом, можно случайно отрезать полезную индексацию, партнёрский трафик или агентный сценарий, где пользователь действительно хотел получить доступ к странице.
Ещё один слабый участок — обходы и идентичность. Cloudflare опирается на Web Bot Auth и подписи запросов, чтобы отличать заявленного краулера от подделки. Это правильное направление, но оно работает для участников, которые готовы регистрироваться и подписывать трафик. Необъявленные краулеры и браузерная автоматизация остаются отдельной задачей для bot management.
Что это значит для SEO и владельцев сайтов
Pay-to-crawl не заменяет SEO. Страница всё ещё должна быть понятной поиску, быстро загружаться, иметь нормальную структуру и приносить пользу человеку. Но владельцам сайтов придётся разделять доступ по типам машинных читателей: кого пускать ради видимости, кого пускать за деньги, кого закрывать совсем.
Для SEO-команд это добавляет новый слой решений. Раньше главный вопрос был «может ли поисковик увидеть страницу». Теперь рядом появляется вопрос «может ли AI-система использовать страницу без перехода и компенсации». В материале про поиск для AI-агентов мы писали, что агентный поиск становится отдельным инфраструктурным рынком. Cloudflare показывает второй слой того же рынка: кто контролирует доступ к исходным страницам.
Практический вывод осторожный. Новостным сайтам, справочникам, форумам, базам знаний и коммерческим каталогам уже стоит смотреть на отчёты AI-краулеров в Cloudflare, логах сервера или аналитике. Но включать платный доступ вслепую опасно. Сначала нужно понять, какие краулеры реально создают нагрузку, какие дают переходы, какие нужны для поиска и какие просто забирают данные.
FAQ
Что такое Cloudflare Pay Per Crawl?
Это функция AI Crawl Control, через которую владелец сайта задаёт цену за доступ AI-краулера к контенту. Краулер либо платит и получает HTTP 200, либо получает HTTP 402 Payment Required с ценой доступа.
Чем Pay Per Crawl отличается от robots.txt?
Robots.txt сообщает пожелания владельца сайта, но технически не заставляет краулер подчиняться. Pay Per Crawl работает на уровне Cloudflare edge: запрос можно разрешить, заблокировать или перевести в платный сценарий.
Кто должен платить за краулинг?
В модели Cloudflare платит оператор AI-краулера. Это может быть компания, которая собирает данные для AI search, обучения модели, ответа агенту или другого автоматизированного сценария. Пока это closed beta, поэтому массового правила для всего рынка нет.
Почему это важно издателям?
AI-ответы уменьшают ценность старой сделки «краулер забрал страницу, сайт получил переход». Если пользователь получает ответ без клика, издателю нужен другой способ вернуть часть стоимости контента. Pay Per Crawl — одна из попыток создать такой способ.
Что пока нельзя утверждать
- Нельзя писать, что Pay Per Crawl уже стал стандартом. Cloudflare прямо называет его closed/private beta.
- Нельзя обещать, что все AI-компании начнут платить за обход сайтов. Это зависит от принятия рынка, юридического давления и качества блокировок.
- Нельзя смешивать bot traffic с числом людей в интернете. Cloudflare Radar считает HTTP-запросы к HTML-контенту, а не пользователей.
- Нельзя считать HTTP 402 полноценной лицензией на контент. Это технический механизм доступа и оплаты; юридические условия всё равно нужно оформлять отдельно.
Источники и дата проверки
Факты, даты и формулировки в материале проверены 8 июня 2026 года.
- Cloudflare Blog: Introducing pay per crawl
- Cloudflare Docs: What is Pay Per Crawl?
- Cloudflare Docs: Crawl pages
- Cloudflare Blog: Introducing AI Crawl Control
- Cloudflare Radar: Traffic Worldwide
- The Decoder: Cloudflare CEO says the web's future is pay to crawl
- TechCrunch: Cloudflare launches a marketplace for AI bots
- Axios: Publishers facing existential threat from AI