AI-боты сканируют TLS-логи: новый налог на открытый веб
AI-боты находят новые домены через публичные CT-логи. Что это значит для владельцев сайтов, robots.txt и экономики открытого веба.
По состоянию на 27 мая 2026 года AI-боты сканируют TLS-логи уже как часть новой экономики краулинга. Новый домен получает сертификат, запись появляется в публичном журнале Certificate Transparency, и вскоре его может проверить поисковый или обучающий бот. Для владельца сайта это выглядит как один запрос к /robots.txt. В масштабе открытого веба это ещё один способ превратить любую свежую страницу, витрину, документацию или блог в сырьё для автоматического сбора данных.
Важное уточнение: речь не о приватных TLS-логах на сервере владельца сайта. Речь о CT-логах, то есть публичных журналах выданных TLS-сертификатов. Они нужны для безопасности веба: по ним можно обнаружить ошибочно или вредоносно выпущенные сертификаты. Но та же прозрачность даёт ботам удобный список новых доменов и поддоменов.
Поводом стал RSS-материал на Хабре от 24 мая. Автор связал отчёт HUMAN Security о росте AI-трафика с короткой заметкой Benjojo: после выпуска нового сертификата для autoconfig.benjojo.uk сервер почти сразу увидел запрос к /robots.txt с user-agent OAI-SearchBot. Сам пример не доказывает, что каждый такой запрос идёт именно из CT-логов. Но он хорошо показывает главный сдвиг: открытые технические реестры, которые создавались для доверия и безопасности, всё чаще становятся источником навигации для автоматизированного веба.
Почему CT-логи нельзя просто закрыть
Certificate Transparency решает реальную проблему. Если удостоверяющий центр по ошибке или после взлома выдаст сертификат для чужого домена, публичный append-only журнал позволяет владельцу домена, браузерам и независимым наблюдателям это заметить. На официальной странице проекта CT прямо сформулирована цель: сделать выпуск сертификатов прозрачным и проверяемым.
Побочный эффект понятен любому администратору: имя домена в сертификате перестаёт быть скрытым. Для публичного сайта это нормально. Внутренние панели, временные стенды, тестовые поддомены и автоконфигурационные адреса часто живут в странной серой зоне: их не считают секретом, но и не ждут, что они мгновенно попадут в поле зрения краулеров.
CT-логи ускоряют этот момент обнаружения. Раньше боту нужно было найти ссылку, пройти sitemap, угадать адрес или получить домен из сторонней базы. Теперь достаточно наблюдать за потоком свежих сертификатов. Практический риск связан со скоростью: время между появлением ресурса и первым автоматическим визитом сокращается.
Один бот не равен обучению модели
В этом сюжете легко перейти к слишком сильному выводу: мол, OpenAI увидела сертификат и сразу забрала страницу для обучения. Такой вывод был бы неточным. В документации OpenAI разные краулеры разведены по назначению: OAI-SearchBot используется для поиска в ChatGPT, GPTBot связан с контентом, который может использоваться для обучения базовых моделей, а ChatGPT-User ходит по ссылкам в рамках действий пользователя. OpenAI также пишет, что владельцы сайтов могут разрешать и запрещать эти боты отдельно через robots.txt.
Поэтому корректная формулировка такая: пример Benjojo показывает быстрый визит поискового AI-бота после появления сертификата. Он не доказывает использование конкретной страницы для обучения LLM. Но для владельца сайта практическая разница часто меньше, чем кажется. Сервер всё равно обслуживает запросы, журналирует их, тратит пропускную способность и вынужден решать, каких ботов считать полезными, каких терпеть, а каких блокировать.
AI-трафик перестал быть фоном
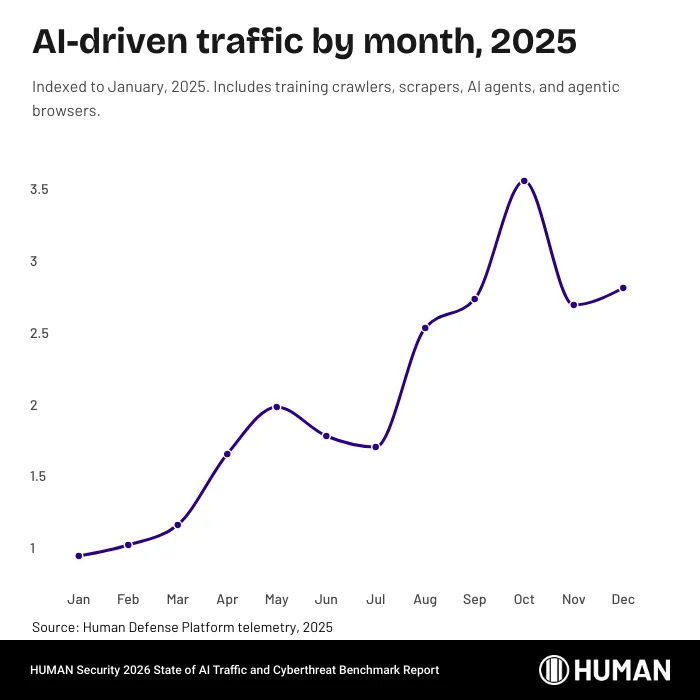
HUMAN Security в отчёте The 2026 State of AI Traffic & Cyberthreat Benchmark Report анализирует данные своей платформы за 2022-2025 годы. Методология ограничена агрегированной и анонимизированной выборкой клиентов HUMAN, а не всем интернетом. Масштаб при этом большой: в 2025 году платформа обработала более одного квадриллиона взаимодействий.
В этой выборке AI-driven traffic с января по декабрь 2025 года вырос на 187%. Трафик AI-скраперов вырос на 597%, а трафик агентных браузеров и AI-агентов, по данным HUMAN, вырос на 7851% год к году. Обучающие краулеры всё ещё дают крупнейшую долю AI-ботов, около 67,5%, но real-time скраперы уже занимают 31,9%. Это важнее красивой цифры роста: веб всё чаще читают не только индексаторы, но и системы, которым нужны свежие цены, новости, наличие товаров, документация и ответы «прямо сейчас».
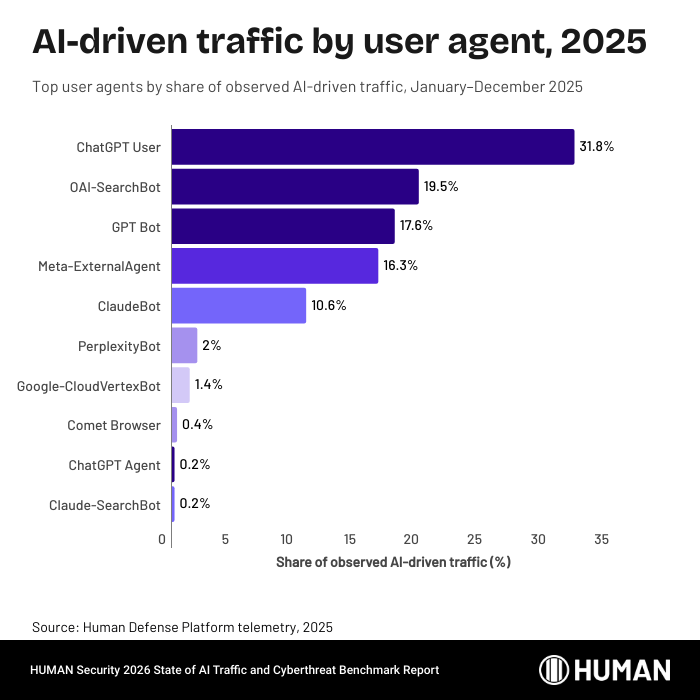
У отчёта есть ещё одна неудобная деталь: идентичность бота нельзя надёжно принимать только по строке user-agent. HUMAN отдельно пишет, что часть запросов, которые представлялись ботами ChatGPT, Mistral и Perplexity, не приходила из инфраструктуры этих операторов. Для владельца сайта это означает простую вещь: robots.txt и user-agent полезны как сигнал, но недостаточны как механизм доверия.
robots.txt держится на честности
robots.txt никогда не был замком. Это договорённость: владелец сайта публикует правила, добросовестный бот читает их и выполняет. Такая модель работала, пока основные игроки были заинтересованы в репутации поискового индекса. В мире AI-поиска, RAG, агентных браузеров и дата-брокеров стимулы стали грязнее: данные ценны сами по себе, даже если перехода на исходный сайт не будет.
Cloudflare в августе 2025 года заявила, что Perplexity использовала не только объявленный user-agent, но и необъявленные запросы, похожие на обычный Chrome на macOS, когда объявленный краулер блокировали. По данным Cloudflare, активность шла через разные IP и ASN, а компания исключила Perplexity из списка verified bots. Perplexity спорила с этими выводами: представитель компании в комментарии TechCrunch назвал публикацию Cloudflare «sales pitch» и заявил, что показанный бот не принадлежит Perplexity.
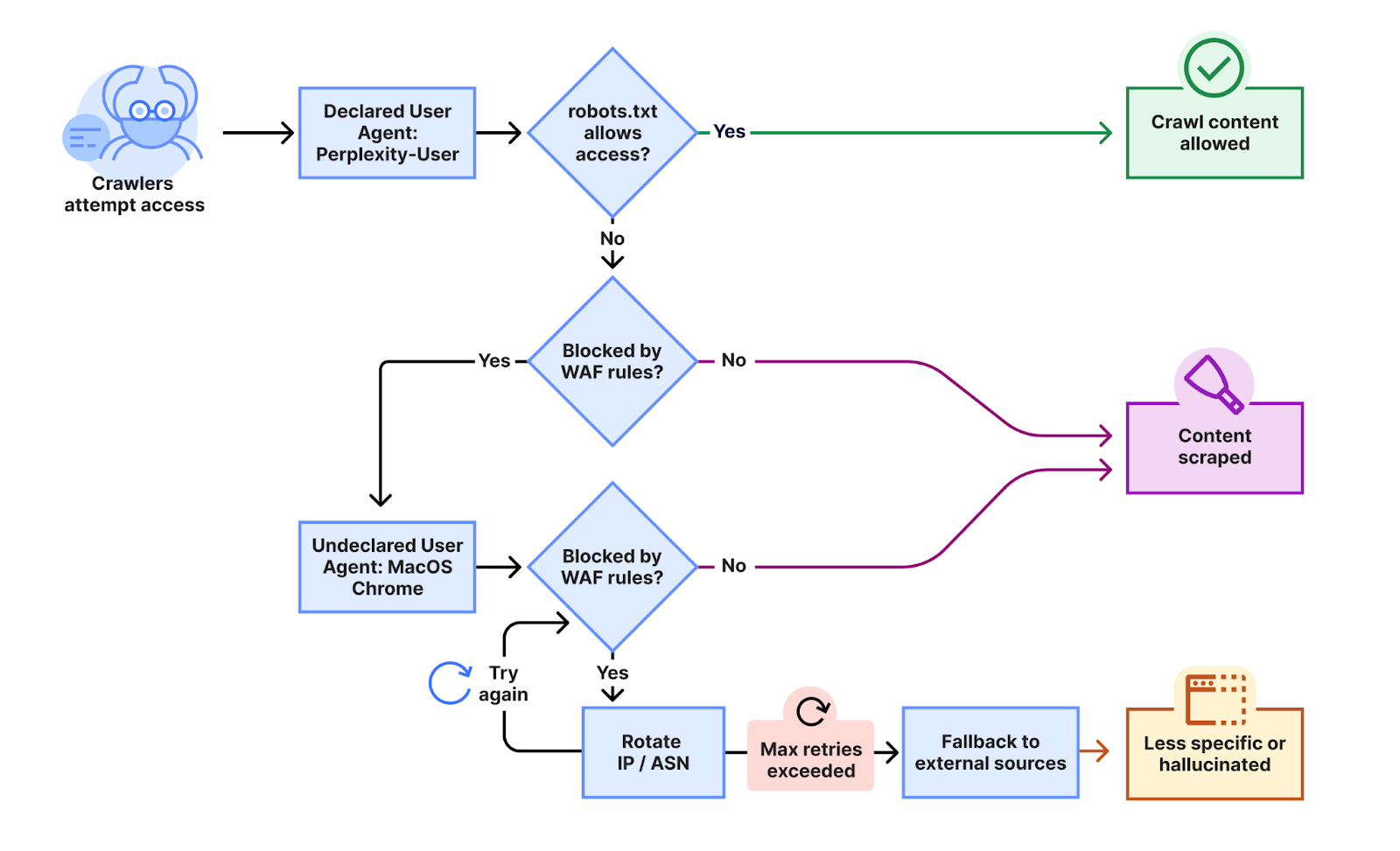
Для этого материала важен не спор вокруг одной компании. Важен общий вывод: управление доступом к сайту больше нельзя строить только на тексте в /robots.txt. Нужны проверяемые IP-диапазоны, подписи запросов, поведенческие сигналы, лимиты, WAF-правила и понятная политика: кого пускаем для поиска, кого для обучения, кого только по платному или договорному доступу.
Почему это бьёт по открытому вебу
Классический обмен был простым: поисковик индексирует страницу, сайт получает переходы, читателей, подписчиков или рекламный доход. AI-поиск меняет баланс. Сайт может получить нагрузку от краулинга, но пользователь увидит готовую выжимку в интерфейсе ассистента и не перейдёт к источнику. Этот конфликт уже виден в соседнем материале Toolarium про ИИ-поисковики и экономику переходов из поиска.
Cloudflare в 2025 году запустила Pay Per Crawl и новую модель разрешений для AI-краулеров. В пресс-релизе компания прямо пишет, что старый обмен «индексация в обмен на трафик» сломан: AI-краулеры собирают тексты, изображения и статьи, чтобы генерировать ответы без перехода на исходный сайт. Это позиция Cloudflare, а не универсальный закон рынка. Но само появление Pay Per Crawl показывает, насколько далеко спор ушёл от обычного SEO.
Машинный трафик уже стал отдельной статьёй расходов не только для медиа, но и для открытой инфраструктуры. Мы видели похожую логику в разборе Toolarium про перегрузку open-source реестров пакетами AI и CI/CD: автоматизация приносит пользу пользователям, но счёт за трафик, хранение, защиту и поддержку часто остаётся у инфраструктурной стороны.
Если этот счёт растёт, у владельцев сайтов остаётся несколько неприятных вариантов: закрывать контент за paywall, агрессивнее блокировать ботов, отдавать доступ только избранным партнёрам или принимать нагрузку как новый налог на видимость. Открытый веб при этом становится менее открытым не из-за одного запрета, а из-за накопления защитных мер.
Что делать владельцам сайтов
Первое: разделить ботов по назначению. Поиск, обучение, пользовательские действия и агентные сценарии должны иметь разные правила. Один общий запрет на «всё AI» может защитить контент, но одновременно убрать сайт из AI-поиска. Один общий allow может открыть слишком много.
Второе: не доверять одному user-agent. Проверяйте опубликованные IP-диапазоны там, где они есть, смотрите ASN, частоту запросов, последовательность URL, чтение robots.txt, реакцию на 403 и 429. Для зрелой инфраструктуры стоит смотреть и на TLS/JA4-фингерпринты. Project Lanterna в апреле 2026 года показал, что разные AI-боты и сканеры можно различать не только по заголовкам, но и по TLS-профилю, хотя это тоже не серебряная пуля.
Третье: считать стоимость. Один визит поискового бота обычно не проблема. Проблема начинается, когда тысячи запросов идут на тяжёлые страницы, параметры фильтров, поиск, старые архивы, картинки и API. Лимиты, кэш, отдельные правила для динамических маршрутов и защита от параметрического краулинга становятся не «паранойей», а нормальной эксплуатацией сайта.
Четвёртое: помнить про CT-логи при выпуске сертификатов. Не размещайте чувствительные панели на поддоменах, которые станут публично видимыми после выдачи сертификата. Для внутренних сервисов используйте нормальную аутентификацию, сетевые ограничения и отдельную модель доступа. Wildcard-сертификат может уменьшить утечку отдельных имён поддоменов в CT, но не заменяет защиту приложения.
Пятое: не смешивать спор о доступе с авторским правом. Юридический вопрос о том, можно ли использовать контент для обучения моделей, требует отдельного разбора. У Toolarium уже есть материал про границу между ИИ и авторским правом. Здесь же практический слой другой: даже легитимный бот может быть инфраструктурной нагрузкой, если сайт не понимает, кто пришёл и зачем.
Главное
Сканирование CT-логов AI-ботами не ломает Certificate Transparency. CT по-прежнему нужен, потому что безопасность сертификатов важнее иллюзии скрытых поддоменов. Но этот кейс показывает, что открытость технических реестров теперь используется не только людьми, браузерами и исследователями, но и автоматическими системами, которым нужно всё больше свежих данных.
Кризис открытого веба ускоряется не одним злым ботом и не одной компанией. Его ускоряет новая арифметика: данных нужно больше, свежесть ценится выше, пользователь остаётся внутри AI-интерфейса, а сайт платит за запросы, защиту и потерянные переходы. В этой среде владельцу сайта придётся управлять доступом к контенту так же внимательно, как раньше он управлял индексацией в поиске.
Читайте также
- Open-source реестры пакетов перегружены: кто платит за AI и CI/CD
- Perplexity vs Google AI: ИИ-поисковики
- ИИ и авторское право: где проходит граница
Источники и проверка фактов
- Хабр: «ИИ-боты сканируют даже логи TLS-сертификатов», опубликовано 24 мая 2026 года, проверено 27 мая 2026 года.
- Benjojo: заметка о запросе OAI-SearchBot после выпуска TLS-сертификата, опубликовано 12 декабря 2025 года, проверено 27 мая 2026 года.
- Certificate Transparency: описание CT-экосистемы, проверено 27 мая 2026 года.
- HUMAN Security: The 2026 State of AI Traffic & Cyberthreat Benchmark Report, проверено 27 мая 2026 года.
- OpenAI: Overview of OpenAI Crawlers, проверено 27 мая 2026 года.
- Cloudflare: Perplexity is using stealth, undeclared crawlers..., опубликовано 4 августа 2025 года, проверено 27 мая 2026 года.
- TechCrunch: Perplexity accused of scraping websites that explicitly blocked AI scraping, опубликовано 4 августа 2025 года, проверено 27 мая 2026 года.
- Cloudflare: Introducing Pay Per Crawl, опубликовано 1 июля 2025 года, проверено 27 мая 2026 года.
- Project Lanterna: AI Agent Fingerprint Discovery, данные захвата 3-4 апреля 2026 года, проверено 27 мая 2026 года.


