AI search startups: почему поиск для AI-агентов стал рынком
Exa и Parallel подняли крупные раунды не ради ещё одного поисковика, а ради инфраструктуры для AI-агентов. Разбираем, почему поиск снова стал точкой контроля.

По состоянию на 27 мая 2026 года рынок AI search startups вышел за рамки «поисковиков с нейросетью» и превращается в инфраструктурную нишу. Exa Labs объявила о раунде на $250 млн при оценке $2,2 млрд. Parallel Web Systems за несколько недель до этого подняла $100 млн при оценке $2 млрд. Обе компании продают поиск, извлечение и проверку данных для AI-агентов, а не красивую страницу выдачи для пользователя.
Это важный сдвиг. Классический поиск строился вокруг человека: короткий запрос, список ссылок, реклама, переход на сайт. AI-агенту нужна другая механика: быстро найти свежие источники, достать из них нужные фрагменты, вернуть структурированный ответ, приложить цитаты и повторить это тысячи раз внутри рабочего процесса. На таком слое и пытаются вырасти Exa, Parallel и другие стартапы AI-поиска.
Сигнал от инвесторов понятен: если агенты станут массовыми пользователями веба, поиск снова станет точкой контроля. Теперь эта точка смещается с первой страницы Google к API, индексу, цитированию, мониторингу изменений и качеству retrieval для моделей.
Что произошло
20 мая 2026 года TechCrunch выпустил материал AI search startups are blowing up. Инфоповодом стала серия крупных раундов вокруг поиска для AI-систем. Главный пример: официальный анонс Exa. Компания привлекла $250 млн Series C при оценке $2,2 млрд, раунд возглавила Andreessen Horowitz. Это уточнение важно: в первичном RSS-описании задачи фигурировала оценка $2,5 млрд, но официальная цифра Exa — $2,2 млрд.
Exa называет себя «search engine for AIs». По данным компании, её индекс отслеживает более 500 млрд URL, основной поиск работает быстрее 200 мс, а клиентами или пользователями Exa названы Cursor, Cognition, HubSpot, OpenRouter, Monday.com, 5 000+ компаний и 400 000+ разработчиков.
Второй крупный пример: Parallel Web Systems. 29 апреля 2026 года компания объявила о Series B на $100 млн при оценке $2 млрд. Раунд возглавила Sequoia Capital, партнёр Andrew Reed вошёл в совет директоров. Parallel также сообщила, что общий объём привлечённого капитала достиг $230 млн.
Обе сделки идут на фоне давления со стороны крупных платформ. Google на I/O 2026 описал новый этап AI Search: AI Mode, Search Live, information agents, агентное бронирование и сценарии, где поиск помогает выполнить часть задачи за пользователя. Для независимых стартапов это одновременно подтверждение рынка и риск: Google сам перестраивает поиск под AI.
Почему агентам нужен другой поиск
Человеку достаточно хорошего сниппета и списка ссылок. Агенту этого мало. Если модель должна подготовить исследование, заполнить CRM, проверить поставщика, найти публичный документ или следить за изменениями на сайте, ей нужен машинно-читаемый поток данных: найденные страницы, релевантные фрагменты, источники и формат, который можно сразу отдать в следующий шаг.
В таких задачах важны пять вещей:
- свежесть: агенту часто нужны данные за последние часы или дни, а не усреднённый ответ из старого корпуса;
- извлечение контента: модель должна получить не только ссылку, но и релевантные фрагменты страницы;
- структура: результат должен помещаться в JSON, таблицу, карточку CRM или контекстное окно LLM;
- проверяемость: без цитат и исходных URL агент превращается в генератор уверенных догадок;
- стоимость и задержка: один пользовательский запрос может запускать десятки поисковых операций внутри цепочки агента.
Поэтому Exa и Parallel продают инфраструктуру для разработчиков. Это другой рынок, чем потребительские answer engines вроде Perplexity. Exa делает ставку на индекс и быстрый search API для AI-приложений. Parallel описывает свои API как слой для web research и агентных задач, где система сама ищет, ранжирует, извлекает и возвращает проверяемый результат.
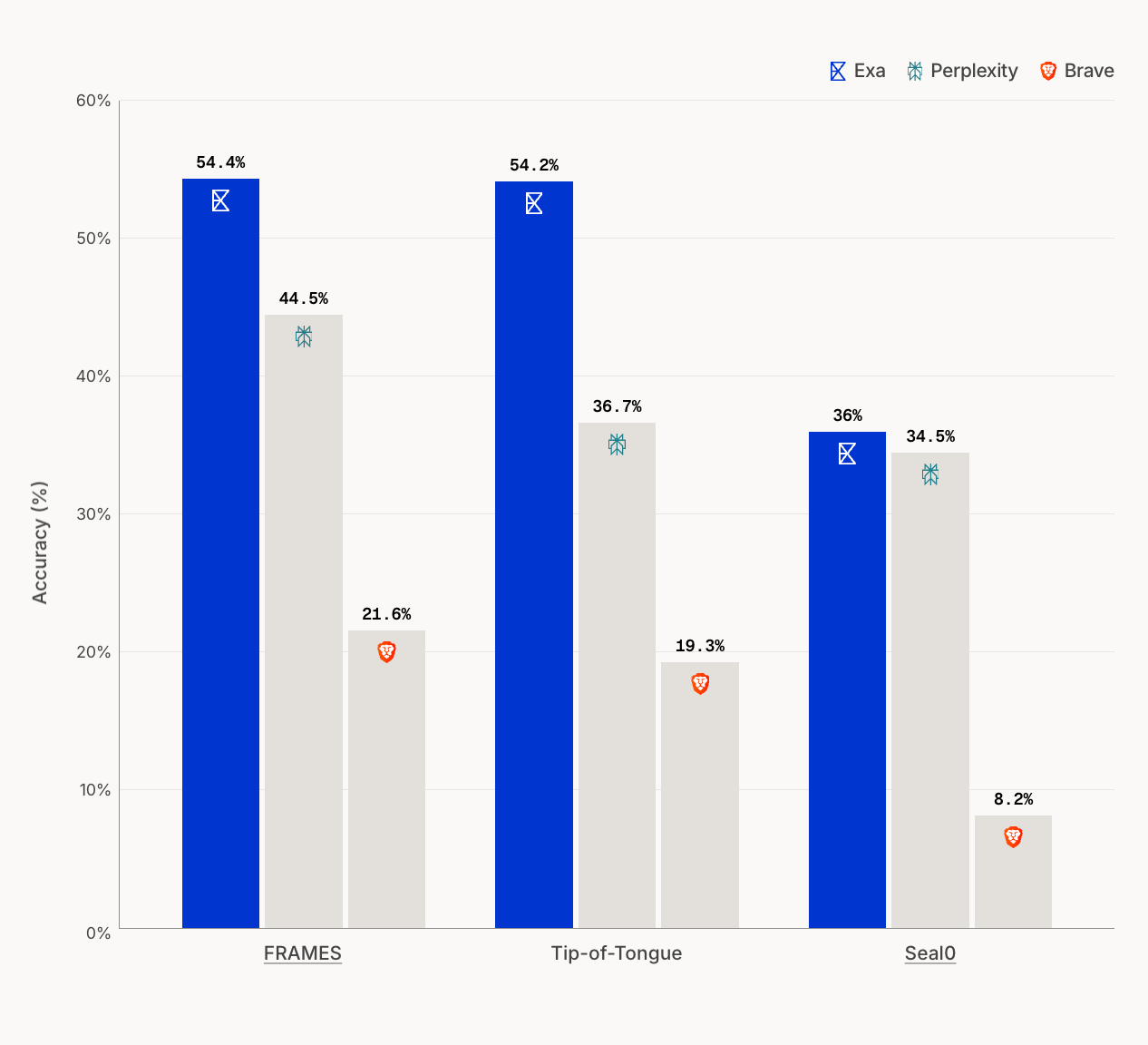
На практике это близко к тому, что разработчики уже делают в продуктах: встраивают поиск, retrieval и обогащение данных внутрь приложения. Мы отдельно разбирали, как встроить ИИ-поиск в приложение с эмбеддингами. Новый слой отличается масштабом: вместо локальной базы знаний он пытается стать внешним веб-индексом для агентов.
Google усиливает спрос, но не закрывает весь рынок
Самый сильный аргумент против независимых AI search startups звучит просто: если Google перестроит Search под AI, зачем кому-то отдельная инфраструктура? Ответ зависит от того, кто пользователь.
Для массового человека Google и дальше будет основным входом в веб. На I/O 2026 компания прямо связала поиск с AI Mode, голосовым и визуальным Search Live, агентами для сбора информации и задачами вроде бронирования. Это защищает потребительский поиск и даёт Google огромный распределительный канал.
Но разработчику агентного продукта нужен другой контроль. Ему важно управлять источниками, получать результаты через API, настраивать задержку и качество, хранить цитаты, вписывать ответ в собственный интерфейс и не зависеть от продуктовой логики Google Search. Поэтому рядом с большим потребительским поиском появляется рынок машинного поиска: он меньше по аудитории, но глубже встроен в рабочие процессы.
Здесь проходит граница с материалами про пользовательские поисковики. В сравнении Perplexity и Google AI главный вопрос: как человек получает ответ вместо списка ссылок. В этой статье вопрос другой: какой слой будет искать и проверять информацию за агента, пока пользователь видит только готовое действие или отчёт.
Чем Exa и Parallel отличаются друг от друга
Exa сильнее говорит языком поискового индекса. В официальном анонсе компания подчёркивает масштаб URL, скорость поиска, собственные модели ранжирования и задачу «питать всех агентов качественным web search». Это ближе к инфраструктурной версии поисковой системы: индекс, качество retrieval, API, контент для LLM.
Parallel чаще описывает себя через исследовательские и рабочие процессы. В посте о Series B компания пишет о web search и agentic research API, клиентах вроде Harvey и Notion, а также о задачах в юридической, финансовой, страховой, маркетинговой и аналитической работе. Угол Parallel: агент ищет страницы и собирает часть исследования с проверяемыми источниками.
Разница важна для оценки рынка. Один путь: стать лучшим индексом и search API для AI. Второй путь: стать рабочим слоем для повторяемых исследований, где поиск, извлечение, цитаты и уверенность результата уже собраны в продукт. В реальности эти подходы будут пересекаться: любому research API нужен сильный индекс, а любому индексу нужен удобный способ превратить найденное в полезный ответ.
Кому может понадобиться такой слой
Покупателями или стратегическими партнёрами здесь могут быть несколько типов компаний. Облачным платформам нужен поиск как часть стека для AI-разработчиков. Для продуктовых платформ вроде офисных пакетов и CRM это источник свежих внешних данных для агентов. Для корпоративных AI-команд это проверяемый retrieval без ручной сборки парсеров и краулеров. Для социальных и поисковых платформ это защита своих данных и новый способ монетизации веба.
Из этого не следует, что Exa или Parallel обязательно купят крупные игроки. Сделки такого масштаба зависят от регулирования, цен, темпа роста и того, смогут ли независимые поставщики удержать качество. Но логика интереса понятна: если агент становится интерфейсом к работе, поиск за агентом становится стратегическим слоем.
Для Google, OpenAI, Anthropic, Microsoft, Amazon и корпоративных SaaS-платформ вопрос звучит одинаково: строить свой индекс, полагаться на чужой или купить готовую команду с API, клиентами и данными. После раундов Exa и Parallel этот вопрос стал дороже.
Главные риски
Первый риск: экономика crawling. Индексировать веб дорого. Нужно обходить страницы, очищать контент, бороться с мусором, обновлять данные, выдерживать блокировки и платить за инфраструктуру. Если запросы агентов будут расти быстрее выручки, привлекательная история про «поиск для AI» может упереться в себестоимость.
Второй риск: права на контент. Издатели уже спорят с поисковиками и AI-компаниями о том, кто имеет право забирать, пересказывать и монетизировать их материалы. Агентный поиск усилит конфликт: он показывает ссылку и часто вытаскивает ответ прямо в продукт клиента.
Третий риск: качество. Агенту нельзя дать «примерно релевантный» источник, если результат идёт в юридический отчёт, финансовую проверку или автоматическое решение. Поэтому цитаты, оценка уверенности, контроль свежести и понятные ограничения будут важнее красивой демки.
Четвёртый риск: зависимость от платформ. Крупные модели могут встроить собственный поиск, браузеры получат свои AI-режимы, а сайты закроют доступ для сторонних краулеров. Тогда независимым AI search startups придётся доказывать не только качество, но и устойчивость доступа к данным.
Что это значит для рынка
AI search startups растут из конкретной проблемы: AI-агенты должны работать с живым вебом, а старый поиск плохо приспособлен к машинным рабочим процессам. В этом смысле Exa и Parallel ближе к инфраструктурным компаниям, чем к медийным поисковикам.
У рынка пока больше вопросов, чем ответов. Непонятно, сколько клиентов готовы платить за отдельный search API, выдержит ли экономика индекса, как решатся права на контент и не заберут ли крупные платформы лучшие сценарии внутрь. Но крупные раунды уже показывают, где инвесторы видят следующий узкий слой AI-стека: между моделью и открытым вебом.
Для разработчиков вывод практичный. Если вы строите агента, deep research, мониторинг источников или внешнее обогащение данных, поиск нельзя оставлять «где-нибудь сбоку». Это часть архитектуры продукта: источник данных, цитаты, задержка, стоимость, формат ответа и ответственность за ошибку. Именно за этот слой сейчас и началась новая гонка.
Читайте также
- Perplexity vs Google AI: ИИ-поисковики
- Как встроить ИИ-поиск в приложение с эмбеддингами
- AI Mode в Chrome: Google превращает браузер в ИИ-поиск
Источники и проверка фактов
- TechCrunch: AI search startups are blowing up, опубликовано 20 мая 2026 года, обновлено 21 мая 2026 года, проверено 27 мая 2026 года.
- Exa: Exa Raises $250M Series C to Build the Search Engine for AIs, проверено 27 мая 2026 года.
- Parallel Web Systems: Parallel Raises at $2 Billion Valuation to Scale Web Infrastructure for Agents, опубликовано 29 апреля 2026 года, проверено 27 мая 2026 года.
- Google: AI in Search updates from Google I/O 2026, опубликовано 19 мая 2026 года, проверено 27 мая 2026 года.
- Parallel Web Systems: Parallel Search API is now available in alpha, проверено 27 мая 2026 года.



