Claude пишет код Anthropic: почему ей нужен AI pause
Anthropic утверждает, что Claude пишет большую часть её production-кода. Разбираем, где здесь 80%, где 90%+, и почему это ведёт к verifiable pause.

Claude пишет код Anthropic уже не в демо для клиентов, а во внутреннем production-процессе компании. По состоянию на 7 июня 2026 года безопасная формулировка такая: Anthropic утверждает, что в мае 2026 года более 80% строк, принятых в её production-кодовую базу, были написаны Claude. Оценка 90%+ тоже есть, но она шире: руководство Anthropic относит к ней скрипты и экспериментальный код, а не только merged production code.
Если оставить только заголовок «Claude пишет 90% кода», получится эффектная, но скользкая новость. Публикация Anthropic Institute говорит о другом: компания показывает, как ИИ ускоряет разработку ИИ, и одновременно продвигает идею verifiable pause для frontier AI. Под этим Anthropic понимает проверяемый механизм, при котором несколько ведущих AI-лабораторий одновременно замедляют или ставят на паузу разработку при заранее оговорённых условиях.
Главный источник здесь - официальный текст Anthropic Institute When AI builds itself. Медиа вроде The Decoder и TNW полезны как контекст, но ключевые цифры лучше брать у Anthropic и читать вместе с оговорками.
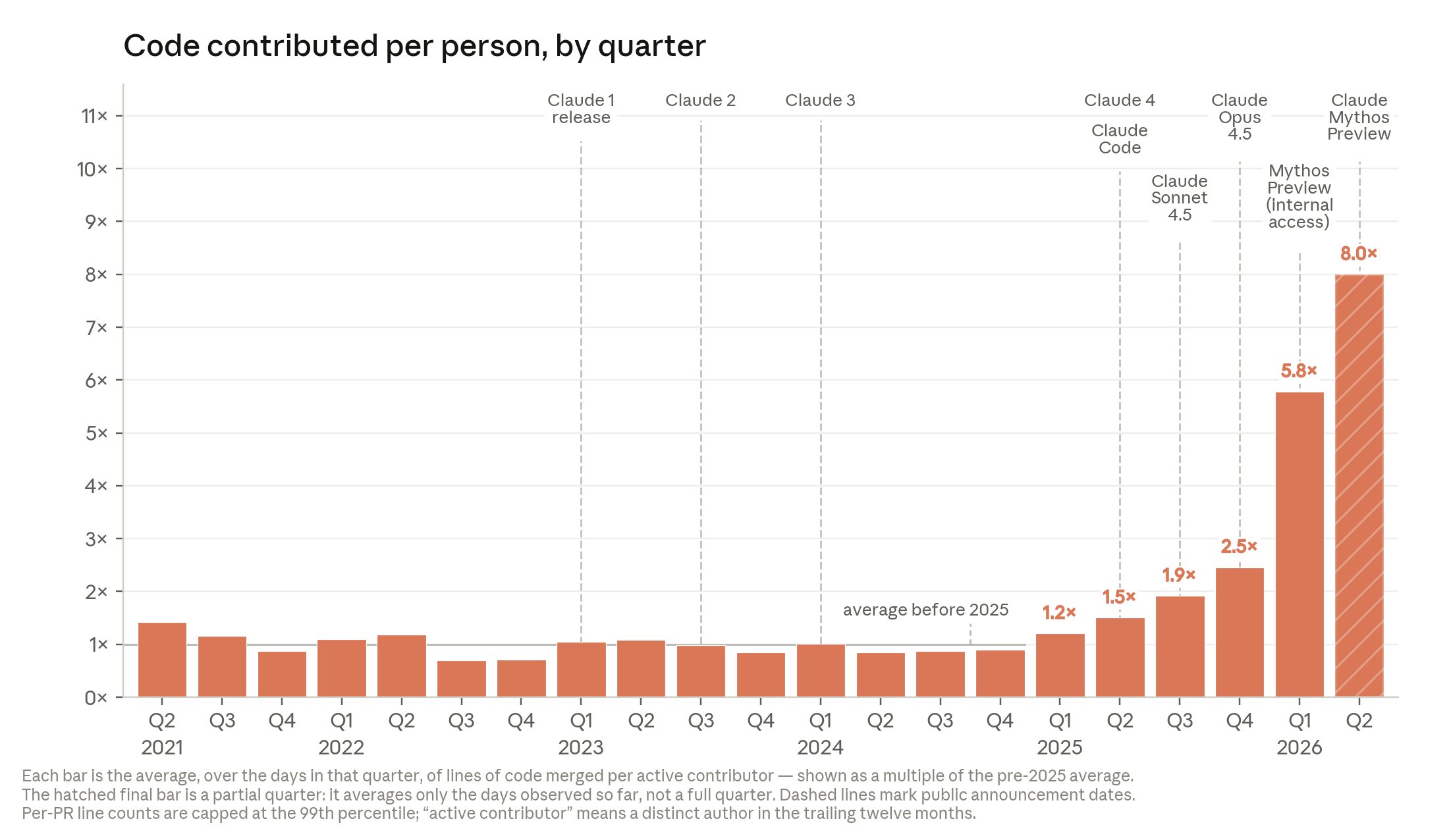
Главная развилка: 80% production-кода и 90%+ широкой оценки
В официальном тексте Anthropic пишет: в мае 2026 года более 80% кода, который компания принимает в свою production-кодовую базу, был написан Claude. До research preview Claude Code в феврале 2025 года эта доля была в «низких однозначных» процентах. Речь идёт о смене рабочего процесса: инженер задаёт цель, направляет и проверяет, а значительную часть реализации делает модель.
Число 90%+ появляется в сноске Anthropic. Там компания уточняет, что руководство публично оценивало долю кода, написанного Claude, в 90% и выше, если считать ещё скрипты и экспериментальный код. Поэтому H1 с прямым «Claude пишет 90% всего кода Anthropic» был бы слишком грубым. Вернее говорить так: Anthropic официально измеряет более 80% для merged production code и отдельно признаёт более широкую leadership-оценку 90%+.
Все цифры в этом блоке self-reported: они идут от Anthropic, собраны внутри Anthropic и описывают работу Anthropic. Компания сама предупреждает, что строки кода плохо измеряют настоящую продуктивность. Во втором квартале 2026 года типичный инженер, по её данным, принимал в день в 8 раз больше строк кода, чем в 2024-м, но Anthropic прямо пишет: такой множитель почти наверняка завышает реальный прирост продуктивности.
Что заявила Anthropic и что это не доказывает
| Заявление или число | Что оно значит | Что оно не доказывает |
|---|---|---|
| Более 80% production-кода | В мае 2026 года большая часть строк, принятых в кодовую базу Anthropic, была атрибутирована Claude. | Это не внешний аудит качества кода и не доказательство, что инженеры стали не нужны. |
| 90%+ по широкой оценке | Руководство Anthropic относит к этой оценке также скрипты и экспериментальный код. | Это не то же самое, что «90% production-кода». |
| 8x строк кода на инженера | Во втором квартале 2026 года объём принятого кода на типичного инженера вырос кратно к уровню 2024 года. | Строки кода не равны производительности, качеству или ценности для продукта. |
| 76% успеха на open-ended задачах | В мае 2026 года Claude Code, по внутренней оценке Anthropic, заметно лучше справлялся с плохо специфицированными задачами. | Это не означает, что Claude сам выбирает, какие исследования нужны компании. |
| Пауза только при проверяемой синхронизации | Anthropic говорит о замедлении или паузе, если другие frontier-разработчики сделают то же самое проверяемым образом. | Компания не объявляла, что уже останавливает разработку ИИ. |
Таблица отделяет инженерно интересный факт от удобной легенды. Claude уже пишет много кода внутри Anthropic. Из этого не следует, что он «сам пишет следующего Claude» без людей, целей, ревью и инфраструктуры.
Почему это больше, чем новость про Claude Code
В публичной дискуссии Claude Code часто всплывает как инструмент для разработчиков: подключил к репозиторию, попросил поправить баг, получил pull request. Мы уже разбирали другой край этой истории в материале про 20 млн коммитов Claude Code и 90% кода в репозиториях без звёзд. Там речь была о массовом следе AI coding в публичном GitHub.
Новая публикация Anthropic про другое. Здесь Claude работает не на случайном пет-проекте и не в демонстрационном репозитории, а внутри компании, которая строит frontier-модели. Поэтому интереснее не само число строк, а изменение процесса. Инженер всё меньше печатает код вручную и всё больше становится постановщиком задачи, ревьюером, оператором эксперимента и владельцем решения.
У Anthropic есть яркий внутренний пример: в апреле 2026 года Claude, по словам компании, сделал более 800 исправлений, которые снизили один класс API-ошибок в тысячу раз. Инженер, курировавший работу, оценил ручной эквивалент в четыре года. Нельзя переносить этот множитель на любую задачу. Зато хорошо виден класс работы, где модель выигрывает у человека объёмом контекста, терпением и способностью перебирать технические варианты без усталости.
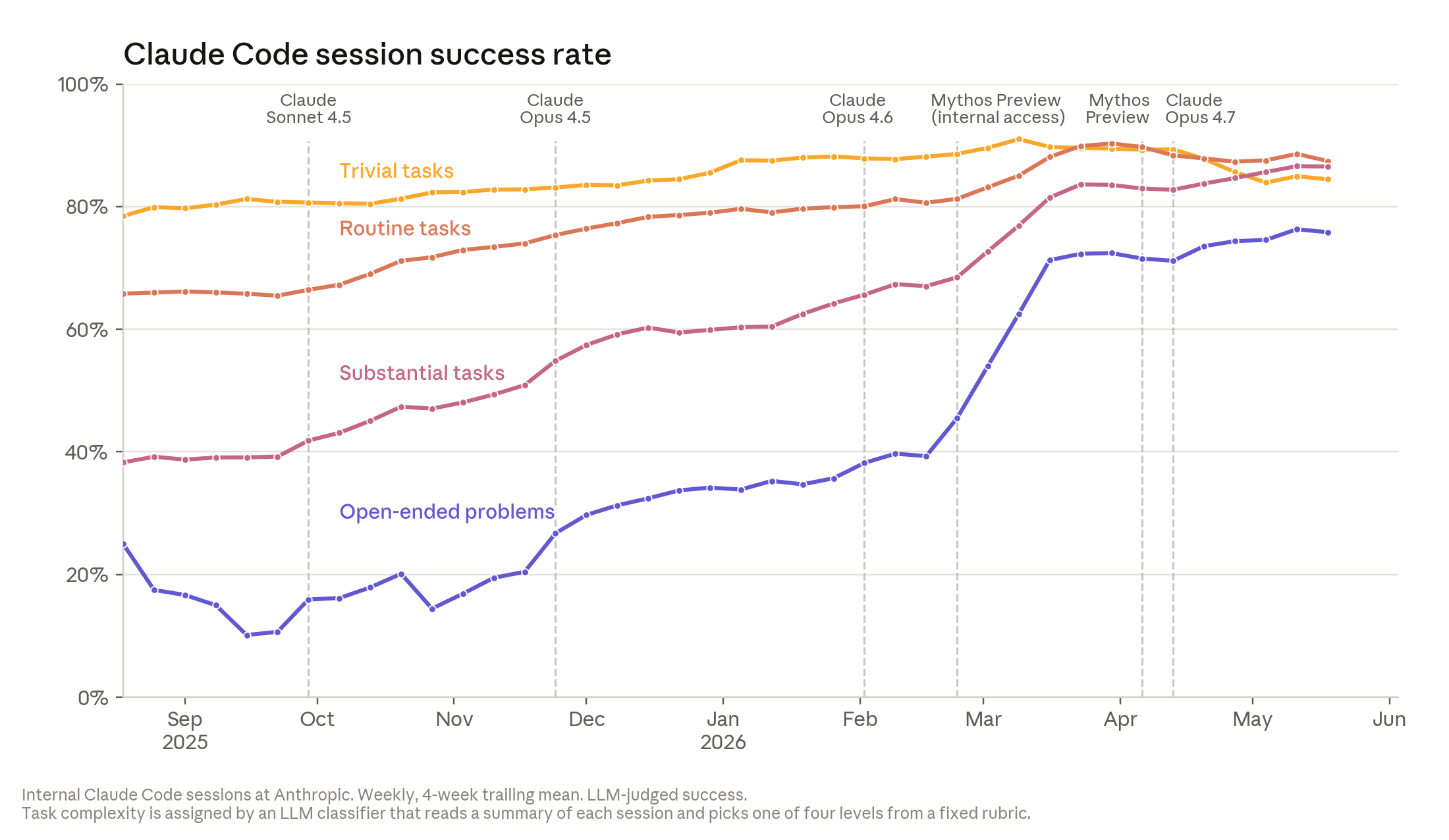
От кода к исследовательскому циклу
Самая интересная часть текста Anthropic начинается там, где заканчивается обычная история про автокодинг. Компания показывает, что Claude уже работает с кусками исследовательского цикла: ускоряет тренировочный код, запускает эксперименты, проверяет гипотезы, предлагает следующие шаги.
В одном внутреннем тесте Claude должен был ускорить код обучения небольшой модели при фиксированных проверках корректности. В мае 2025 года Claude Opus 4 давал около 3x ускорения. К апрелю 2026 года Mythos Preview дошёл примерно до 52x. Для ориентира Anthropic пишет, что сильному человеческому исследователю понадобилось бы 4-8 часов, чтобы получить 4x на той же задаче. Абсолютный множитель не стоит переносить на реальные training runs, но как сравнение моделей на одном стенде он полезен.
Есть и более тонкий тест: Anthropic взяла 129 моментов из реальных исследовательских сессий, где человек уходил в неудачную сторону, и проверила, предложила бы модель лучший следующий шаг. Opus 4.5 в ноябре 2025 года был лучше человеческого выбора в 51% таких моментов, Mythos Preview в апреле 2026 года - в 64%. Здесь много методологических оговорок: выборка специально состоит из мест, где решение человека было неидеальным, а оценку делал другой Claude. Но для тренда это всё равно сигнал.
Так Anthropic связывает AI coding с recursive self-improvement. По словам самой компании, Claude ещё не создаёт следующую версию себя автономно. Пока заметен другой сдвиг: модели всё лучше берут на себя реализацию, тестирование и часть экспериментального поиска, а человеческая роль уходит к постановке целей, вкусу, выбору направлений и проверке. Мы похожую границу обсуждали в материале про SIA self-improving AI: менять код, менять веса и самостоятельно выбирать исследовательскую программу - это разные уровни автономии.
Verifiable pause: не кнопка стоп, а проверяемая договорённость
Самая политическая часть публикации Anthropic касается уже не строк кода. Компания говорит, что миру было бы полезно иметь возможность замедлить или временно поставить на паузу разработку frontier AI, чтобы общественные институты и alignment-исследования успели за технологией. Anthropic сразу ставит условие: односторонняя пауза одного игрока мало что решит, если менее осторожные конкуренты просто догонят или обгонят его.
Отсюда формула verifiable pause. В ней должны участвовать несколько хорошо обеспеченных лабораторий на frontier-уровне, желательно в нескольких странах. Участники должны договориться о триггерах, условиях остановки, условиях снятия паузы и механизмах проверки. Главная трудность в том, что обучение ИИ легче скрыть, чем, например, ракетные шахты. Входы универсальны, вычисления можно распределять, а стимул нарушить договорённость огромен.
Это пересекается с более широким governance-кластером, который мы уже разбирали в материале про frontier AI safety reviews. Но здесь акцент другой. Safety review отвечает на вопрос «как проверять модель перед выпуском». Verifiable pause отвечает на более неприятный вопрос: что делать, если проверка показывает, что темп разработки уже опережает способность общества и самих лабораторий понимать последствия.
Что это значит для разработчиков и менеджеров
Для разработчиков главный вывод прагматичный: AI coding больше нельзя оценивать только по тому, «насколько хорошо модель пишет функцию». Внутри Anthropic модель уже становится частью производственного контура: пишет, правит, прогоняет, помогает ревьюить, ищет баги и закрывает скучные хвосты, до которых люди не доходили годами. Ценность инженера смещается. Быстрый набор кода значит меньше, чем умение сформулировать задачу, поставить ограничения, проверить результат и понять, где модель уверенно ошиблась.
Для менеджеров вывод не менее жёсткий. Если команда внедряет Claude Code или похожие инструменты, считать только строки кода опасно. Anthropic сама показывает почему: LOC растёт быстрее настоящей производительности. Нужны другие метрики: доля задач без человеческих исправлений, время до исправления багов, число регрессий после AI-generated PR, качество ревью, стоимость compute, время инженера на постановку и проверку.
Для рынка ИИ в целом публикация выглядит двойственно. Anthropic одновременно продаёт Claude как рычаг ускорения и предупреждает, что такой рычаг может потребовать глобального тормоза. В этом нет автоматического лицемерия. Это реальное напряжение frontier-рынка: каждая лаборатория обязана ускоряться, потому что конкуренты ускоряются тоже, но именно это ускорение делает разговор о проверяемой паузе менее абстрактным.
Короткие ответы
Claude действительно сам пишет следующий Claude?
Нет в сильном смысле. Anthropic пишет, что Claude уже делает большую долю инженерной реализации и помогает в исследовательских задачах, но люди всё ещё выбирают цели, ставят задачи, проверяют результаты и принимают ключевые решения. До полной recursive self-improvement компания, по её же словам, не дошла.
Anthropic предлагает остановить ИИ прямо сейчас?
Тоже нет. Компания говорит о необходимости иметь проверяемую опцию замедления или паузы для frontier AI. Anthropic ожидает, что сама замедлится или поставит разработку на паузу только если другие разработчики на frontier-уровне сделают то же самое проверяемым образом.
Итог
Claude не «заменил программистов Anthropic». Такая версия слишком плоская. Одна из ведущих AI-лабораторий уже живёт в режиме, где значительная часть инженерной работы делегирована модели, а человеческая работа смещается к постановке целей, ревью и исследовательскому вкусу.
Как история про продуктивность это выглядит приятно: меньше рутины, больше экспериментов, быстрее исправления. Как механизм ускорения самой разработки ИИ - уже тревожнее. Лаборатории получают всё более быстрый внутренний двигатель. Поэтому вопрос Anthropic о verifiable pause звучит не как философия, а как инженерный вопрос ко всей отрасли: кто сможет доказать, что нажал на тормоз, когда тормоз действительно понадобится?
Источники и дата проверки
Факты в материале проверены 7 июня 2026 года. Быстро меняющиеся данные о моделях, внутренних метриках и политике frontier AI могут измениться после этой даты.
- Anthropic Institute: When AI builds itself - основной источник по внутренним данным Anthropic, Claude Code, Mythos Preview и verifiable pause.
- The Decoder - новостной контекст от 5 июня 2026 года и аккуратное разведение 80% production code и 90%+ широкой оценки.
- TNW - дополнительный конкурентный контекст по recursive self-improvement и идее проверяемой паузы.



