AutoTTS test-time scaling: LLM-агент ищет алгоритмы инференса
AutoTTS переносит дизайн test-time scaling из ручных эвристик в replay-среду: Claude Code пишет контроллер, который распределяет ширину и глубину рассуждения.
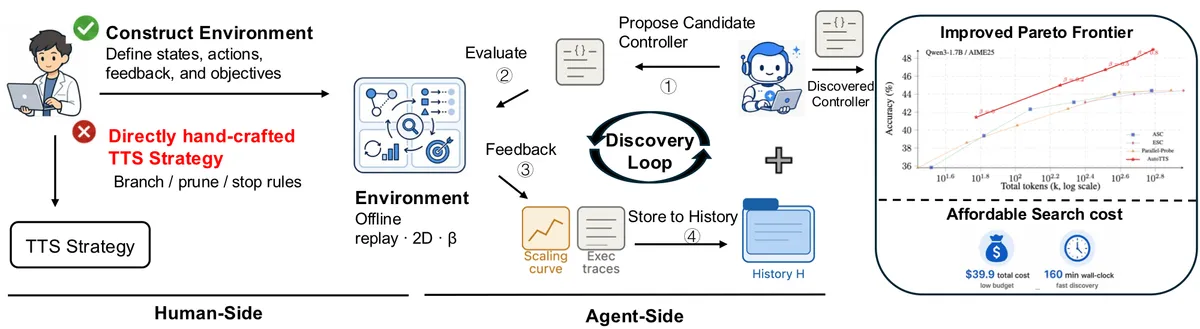
По состоянию на 27 мая 2026 года AutoTTS test-time scaling выглядит как один из самых показательных примеров новой роли LLM-агентов в исследованиях. Команда из Университета Мэриленда, Университета Вирджинии, Washington University in St. Louis, UNC, Google и Meta не просто проверила ещё одну стратегию инференса. Исследователи собрали среду, где агент кодирования сам пишет и перебирает контроллеры, которые решают, когда расширять поиск, когда углубляться и когда остановиться.
Поводом стала статья The Decoder от 24 мая о работе AutoTTS и репозиторий проекта на GitHub. Главная цифра звучит броско: найденный агентом контроллер использовал на 69,5% меньше токенов, чем self-consistency на 64 ветки, при сопоставимом качестве. Но важнее не сама экономия, а способ её получить. AutoTTS переносит часть дизайна test-time scaling из ручных правил в офлайн-среду с дешёвой обратной связью.
Здесь TTS не имеет отношения к синтезу речи. В статье TTS означает test-time scaling: попытку улучшить ответ модели не обучением новых весов, а дополнительными вычислениями во время инференса.
Что произошло
В классическом test-time scaling исследователь сам выбирает стратегию: запустить несколько цепочек рассуждения, продолжить одну цепочку глубже, отрезать слабые варианты, проголосовать по ответам или остановиться раньше. Такие правила работают, но они выглядят как ручная инженерия вокруг модели. Для каждой задачи и каждого бюджета приходится заново решать, сколько ширины и глубины покупать токенами.
AutoTTS предлагает другой контур. Человек задаёт пространство состояний, действий, метрики и ограничения. После этого LLM-агент ищет контроллер, то есть код, который управляет распределением inference-time compute. В экспериментах авторы использовали Claude Code как агент кодирования, а найденные стратегии проверяли в offline replay: на заранее собранных трассах рассуждений, без новых вызовов модели при каждой оценке кандидата.
Это важная развилка. Агент не «улучшает себя» в открытом мире и не переписывает базовую LLM. Он ищет маленькую программу управления в заранее определённой среде. Поэтому результат интересен, но его не стоит продавать как доказательство универсального самоулучшения моделей.
Как устроена среда AutoTTS
Сначала исследователи фиксируют пространство действий. Контроллер может выбирать ширину поиска, глубину рассуждения, pruning слабых веток, продолжение перспективных цепочек и остановку. Затем среда оценивает кандидатов по истории трасс: сколько токенов потрачено, какой ответ получился, как меняется кривая «точность против бюджета».
Авторы подчёркивают две практические детали. Первая: оценка кандидатов в discovery loop работает на replay-данных, поэтому новые LLM-вызовы не нужны. Это резко снижает стоимость перебора. Вторая: агент хранит историю прошлых запусков, включая кривые scaling и execution traces, и использует её при следующей попытке написать контроллер.
На странице проекта указана стоимость одного поиска: $39,9 и около 160 минут реального времени. Это не стоимость применения найденного алгоритма везде, а цена конкретного discovery-запуска в настройке авторов. Для исследовательского перебора это важный сигнал: искать контроллеры можно дешевле, чем запускать тяжёлые онлайн-эксперименты для каждого варианта.
Почему ширина и глубина важны
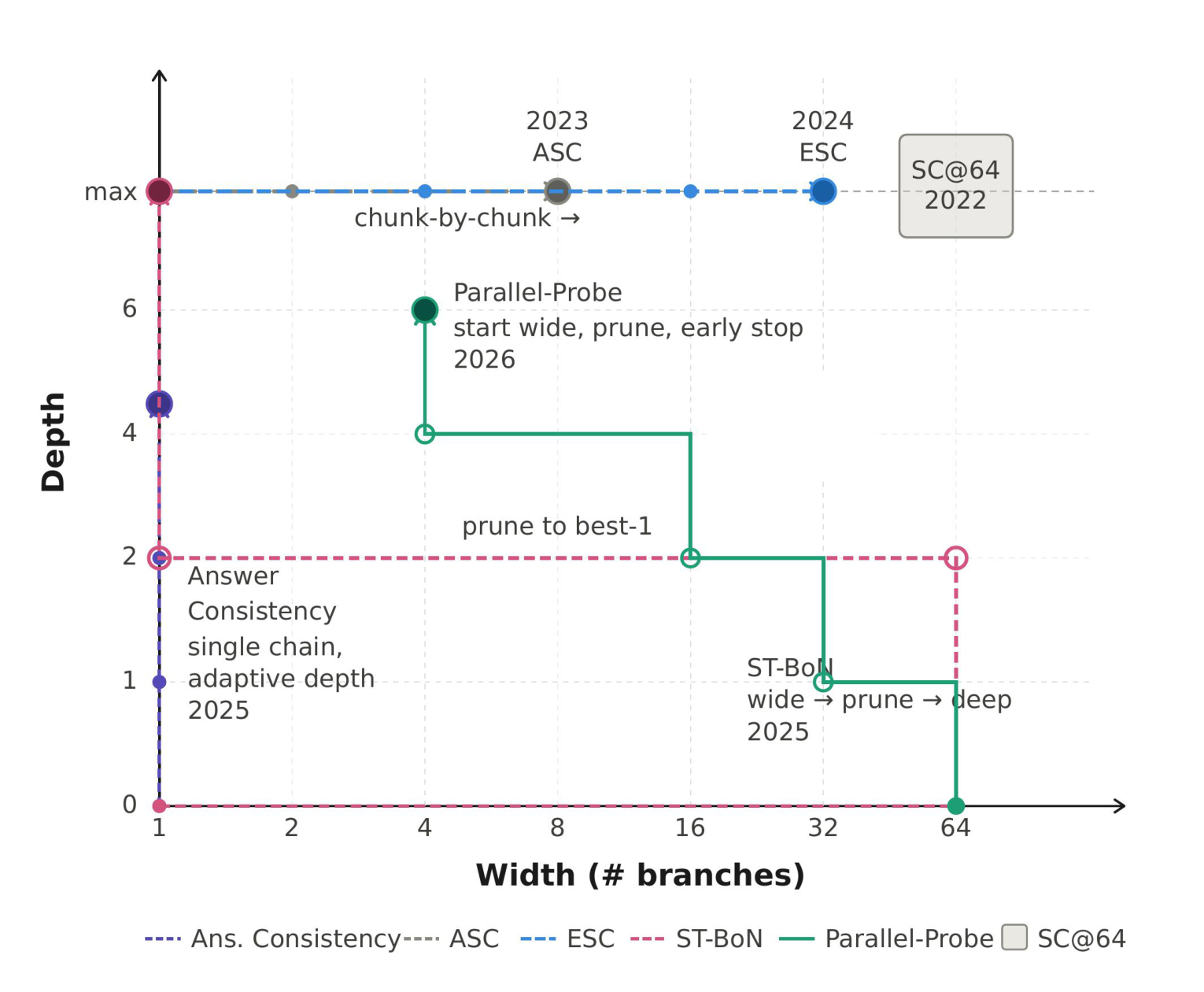
У test-time scaling есть две базовые ручки. Ширина означает несколько независимых попыток: модель решает задачу разными цепочками, а система выбирает итоговый ответ. Глубина означает продолжение рассуждения: одна или несколько цепочек получают больше шагов перед финальным ответом.
Self-consistency делает ставку на ширину: запустить много попыток и выбрать наиболее согласованный ответ. Answer Consistency и Early Stopping Continuation добавляют более адаптивные правила. Parallel-Probe начинает широко, затем отрезает часть вариантов и продолжает перспективные цепочки. AutoTTS интересен тем, что не выбирает один из таких шаблонов заранее, а даёт агенту искать новый контроллер в том же пространстве решений.
В результате авторы получили стратегию CMC. Судя по описанию в статье, она управляет ветвлением и продолжением более гибко, чем фиксированные эвристики. Важная оговорка: CMC не новая базовая модель и не новый способ обучения. Это алгоритм распределения вычислений во время ответа.
Какие результаты подтверждены
На AIME 2025 с Qwen3-1.7B AutoTTS построил лучшую Pareto-кривую, чем ASC, ESC и Parallel-Probe. На графике проекта видно, что найденная стратегия даёт более высокую точность при сопоставимом числе токенов. Авторы отдельно сообщают, что AutoTTS с β≈0,5 экономит 69,5% токенов относительно SC@64 при таком же уровне точности.
В статье The Decoder также указано, что CMC лучше переносился на другие модели и GPQA, чем несколько базовых стратегий. Это сильный, но аккуратный вывод: перенос есть внутри набора экспериментов авторов. Он не означает, что один контроллер автоматически станет лучшим для всех моделей, доменов и бюджетов.
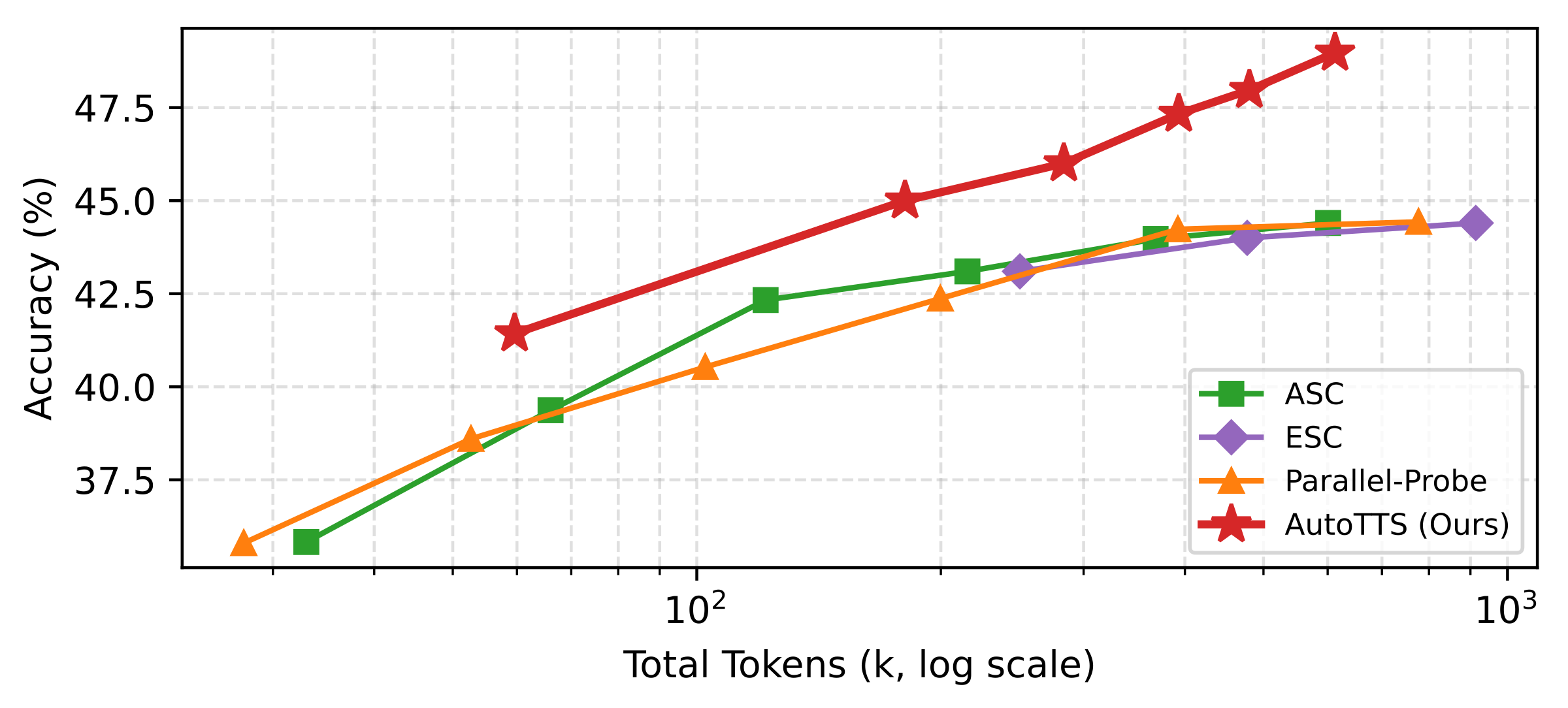
Отдельно стоит смотреть на режим β=1,0. В README репозитория авторы пишут, что CMC даёт лучшую пиковую точность в пяти из восьми сравнений с ручными стратегиями. Для математических бенчмарков это заметный сигнал, но он достигнут через больший и лучше распределённый бюджет инференса, а не через изменение весов модели.
Почему это больше, чем очередная эвристика
В обычной работе с LLM люди часто спорят о промптах, количестве samples и правилах остановки почти вслепую. AutoTTS предлагает более инженерный режим: описать среду, зафиксировать метрики и дать агенту искать контроллеры как программные артефакты. Это близко к тому, что в другом контексте Toolarium уже называл агентным циклом научного поиска: модель не просто отвечает, а действует внутри среды с проверяемой обратной связью.
Для разработчиков LLM-продуктов это полезный сдвиг. Цена ответа агента часто определяется не одним запросом, а десятками шагов: планирование, вызов инструментов, проверка, повторная попытка, ранняя остановка. Если контроллер умеет раньше отрезать слабые ветки, он снижает стоимость без очевидной потери качества. Мы уже разбирали похожую проблему в материале про tool-use tax у LLM-агентов: агентный цикл легко начинает тратить лишний compute, если его не ограничивать.
Есть и второй вывод. Чем больше таких контроллеров будут искать автоматически, тем важнее станет сама обвязка эксперимента: replay-данные, метрики, логирование, ограничения действий, перенос между моделями. Это уже не статья про «магический Claude Code». Это статья про то, что архитектуры агентного ИИ постепенно заходят в исследовательскую инфраструктуру.
Где границы результата
У AutoTTS несколько ограничений, которые нужно держать в тексте рядом с цифрами. Во-первых, агент ищет в заранее заданном пространстве. Если человек плохо описал состояния, действия и цели, discovery loop будет оптимизировать не ту задачу. Во-вторых, replay-оценка дёшево перебирает кандидатов, но зависит от качества заранее собранных трасс.
В-третьих, math benchmarks удобны для проверки, потому что ответ можно оценивать довольно жёстко. В продуктах с инструментами, веб-действиями или кодом критерий успеха сложнее: нужно учитывать безопасность, права доступа, побочные эффекты и стоимость каждого шага. Наконец, перенос на GPQA и другие модели в работе есть, но это не лицензия ставить CMC в любой продакшен без собственных тестов.
Поэтому корректная формулировка такая: AutoTTS показывает, что LLM-агент может находить полезные стратегии распределения inference-time compute в контролируемой среде. Некорректная формулировка: Claude Code сам открыл универсальный алгоритм мышления.
Что это значит для рынка LLM-агентов
AutoTTS хорошо ложится в более широкий тренд: агентам всё чаще доверяют не только выполнение пользовательских задач, но и поиск рабочих процедур для самих LLM-систем. Раньше исследователь писал правила branch, prune и stop руками. Теперь он может спроектировать среду, в которой агент перебирает такие правила как код и возвращает проверяемый артефакт.
Для команд, которые строят сложные LLM-продукты, практический урок простой. Нужно измерять не только качество финального ответа, но и кривую «качество против токенов». Если две стратегии дают одинаковую точность, но одна тратит на 69,5% меньше токенов в проверенном режиме, это уже продуктовая разница. Особенно там, где агент делает много попыток, вызывает инструменты и работает не один запрос, а целый цикл.
AutoTTS пока не готовый стандарт для всех агентных систем. Но он хорошо показывает направление: ценность будет не только в более сильной базовой модели, а в контроллерах, средах оценки и механизмах ранней остановки. Чем дороже становятся длинные агентные траектории, тем важнее искать не самый длинный reasoning, а самый выгодный.
Главное
AutoTTS test-time scaling важен не тем, что «Claude Code заменил исследователей». Исследователи задали среду, ограничения и метрики, а агент помог перебрать пространство контроллеров дешевле и быстрее. Найденная стратегия CMC показала экономию токенов относительно SC@64, улучшение на AIME 2025 и перенос в пределах экспериментов авторов.
Сильный вывод: часть ручной инженерии inference-time compute можно превратить в agentic discovery. Осторожный вывод: это работает в заданной среде и требует проверки на каждой новой задаче. Для рынка LLM-агентов это как раз полезная новость. Следующий прирост качества может прийти не только от новой модели, но и от того, кто лучше управляет её вычислениями во время ответа.
Читайте также
- Tool-use tax у LLM-агентов: где tool-calling начинает вредить
- Агентный ИИ: архитектуры AI-агентов, ReAct и tool use
- Qiushi Discovery Engine: AI-агент дошёл до физического эксперимента
Источники и проверка фактов
- The Decoder: Researchers let Claude Code discover AI scaling algorithms that humans probably wouldn't have designed, опубликовано 24 мая 2026 года, проверено 27 мая 2026 года.
- arXiv: LLMs Improving LLMs: LLMs Discover More Efficient Test-Time Scaling Algorithms, версия 2 от 12 мая 2026 года, проверено 27 мая 2026 года.
- AutoTTS project page, проверено 27 мая 2026 года.
- GitHub: zhengkid/AutoTTS, проверено 27 мая 2026 года.



