AI-first QA на MCP: почему тестирование уходит в CLI и субагенты
Почему AI-first QA на MCP быстро уходит из браузерного loop в CLI, ARIA snapshots и субагенты.
По состоянию на 3 мая 2026 года у AI-first QA уже есть типичный сценарий входа: разработчик подключает Playwright MCP к Claude Code, Copilot или другому агенту, даёт команду «протестируй приложение» и за десять минут получает убедительную демку. Агент открывает браузер, ходит по интерфейсу, находит кнопки по accessibility tree и даже делает скриншоты. На короткой дистанции это действительно работает.
Проблема начинается позже. Как только тот же агент должен не просто исследовать интерфейс, а пройти длинный сценарий, сохранить артефакты, написать тест, перезапустить его и сверить результат, один и тот же контекст начинает держать слишком много разных сущностей сразу: снимки страницы, логи, изображения, код и промежуточные решения. В этот момент AI-first QA упирается не в «слабый ИИ», а в архитектуру самого контура.
Это уже видно не только по пользовательским кейсам, но и по официальной документации. Playwright прямо разводит роли: playwright-cli назван лучшим вариантом для coding agents, которым важна token-efficient работа, а MCP рекомендован для специализированных agentic loops с постоянным состоянием и итеративным анализом структуры страницы. То есть индустрия сама перестаёт делать вид, что один интерфейс одинаково хорош и для разведки, и для длинного прогона.
Если нужен базовый разбор протокола, у нас уже есть отдельный материал про MCP как стандарт интеграции ИИ с инструментами. Здесь вопрос уже другой: где именно ломается AI-first тестирование веб-приложений на MCP-стеке и почему команды постепенно уводят исполнение в CLI, ARIA snapshots и субагентов.
Почему AI-first QA почти всегда начинается с MCP
Начальный выбор легко понять. Playwright MCP даёт агенту полный браузерный контур через Model Context Protocol: открыть страницу, кликнуть, ввести текст, переключить вкладки, сделать скриншот, сохранить состояние. В документации Playwright отдельно подчёркнуто, что агент работает через structured accessibility snapshots, а не через vision-модель. Для первого знакомства с неизвестным интерфейсом это почти идеальный компромисс: быстро поднять, быстро понять, что вообще происходит на странице.
У MCP есть ещё одно важное свойство: он хорошо сочетается с exploratory automation. Когда сценарий ещё не стабилен, а продукт постоянно меняется, удобнее дать агенту богатый интерактивный слой, чем сразу писать статический тест. В этом режиме агент действительно похож на живого исследователя: смотрит на дерево доступности, пробует пройти путь пользователя, задаёт себе следующую локальную цель.
Именно поэтому MCP остаётся полезным даже после всей критики его стоимости. Он не «неправильный интерфейс». Он просто решает другую задачу. Если команда перепутает разведку с повторяемым прогоном, она начнёт обвинять инструмент там, где на самом деле сломалась граница между фазами работы.
Где MCP перестаёт быть ускорителем
Потолок появляется в тот момент, когда exploratory loop незаметно превращается в производственный контур. У Playwright MCP каждое действие возвращает агенту структурированный снимок состояния страницы. Это удобно, пока у вас пять-шесть шагов и незнакомый интерфейс. Но в длинном прогоне тот же механизм начинает копить контекст, который уже не помогает принимать следующее решение.
Официальная документация Playwright здесь предельно откровенна: playwright-cli лучше подходит coding agents, потому что избегает загрузки больших схем инструментов и объёмных accessibility trees в модельный контекст. Это важная формулировка. Она означает, что проблема не в одном неудачном benchmark, а в самой структуре обмена: MCP удобен как богатый интерфейс, но дорог, когда браузерный цикл становится длинным и повторяемым.
Пользовательские кейсы только делают этот излом видимым. В статье на Хабре от 3 мая 2026 года автор описывает, как подключил Playwright MCP к Claude Code для предрелизной проверки двух веб-приложений и уткнулся в /compact уже на 51-м snapshot, хотя текстовый контекст был заполнен лишь частично. Дальше он связывает это не только с накоплением текстовых снимков, но и с отдельным бюджетом inline-изображений. Anthropic не публиковала официальный числовой лимит такого типа, поэтому этот эпизод можно читать только как атрибутированный кейс, а не как формальную спецификацию Claude Code. Но как диагностический сигнал он важен: visual verification и browser exploration начинают конкурировать с кодовым контекстом внутри одной и той же сессии.
К этому добавляется ещё одна неприятность: один и тот же агент пытается одновременно быть исследователем, исполнителем и автором теста. Пока он ходит по приложению, он держит в голове прошлые снимки страницы. Пока пишет тест, он держит локаторы. Пока перезапускает сценарий, он уже тащит в тот же разговор артефакты выполнения. На короткой дистанции это кажется гибкостью. На длинной дистанции это превращается в шум.
| Фаза | Что нужно агенту | Где MCP силён | Где начинается перегруз |
|---|---|---|---|
| Разведка | Понять структуру страницы, найти путь пользователя, быстро проверить гипотезу | Структурированные accessibility snapshots и интерактивный browser loop | Обычно ещё нет |
| Длинный сценарий | Пройти 20-50 шагов без потери нити | Сохраняется удобство живого исследования | В контекст копятся схемы tools, снимки страниц и история шагов |
| Визуальная проверка | Понять, сломался ли layout, модалка или diff | Можно попросить скриншот прямо в ходе работы | Скриншоты начинают конкурировать с кодом и логами за место в сессии |
| Повторяемый прогон | Запускать один и тот же тест детерминированно | MCP ещё может выполнять шаги | Цена и шум выше, чем у статического теста или CLI-команд |
Почему CLI меняет экономику QA-контура
CLI решает эту проблему не тем, что делает магию, а тем, что убирает лишний обмен между моделью и браузером. В документации Playwright CLI сказано, что после каждой команды агент получает короткое описание страницы и ссылку на snapshot-файл. Сам accessibility tree лежит на диске в YAML, а не заливается в контекст как обязательная часть каждого следующего шага. Это и есть главный сдвиг: модель сама решает, когда ей снова нужен снимок страницы, а не получает его по умолчанию после каждого действия.
Отсюда вытекает сразу несколько практических эффектов. Во-первых, CLI лучше уживается с большой кодовой базой и параллельной работой по репозиторию. Во-вторых, снимки и скриншоты становятся артефактами файловой системы, а не вечными жителями разговора. В-третьих, Playwright CLI поддерживает named sessions: можно держать несколько изолированных browser instances с разными cookies, localStorage и историей навигации. Для QA это важно не как красота интерфейса, а как способ развести роли и окружения.
Именно поэтому зрелый контур начинает выглядеть иначе. MCP остаётся сверху как быстрый bootstrap для исследования незнакомого интерфейса. Но как только путь найден, агенту выгоднее перейти к CLI-командам или сразу к статическому Playwright Test. Повторяемый сценарий не должен жить как бесконечный диалог с браузером, если его уже можно превратить в воспроизводимый файл.
Этот вывод хорошо рифмуется и с более широким сдвигом в developer tooling. OpenAI описывает Codex CLI как coding agent, который работает локально на машине разработчика, а Google называет Gemini CLI terminal-first open-source агентом с built-in tools и поддержкой MCP. То есть рынок в целом идёт не к одному «универсальному агентному протоколу», а к сборке из нескольких слоёв: терминал, локальные артефакты, отдельные агенты, точечно подключаемые MCP-серверы.
ARIA snapshots полезнее пикселей там, где нужен детерминизм
Самый полезный урок из Playwright в 2026 году звучит скучно, но очень по делу: для большого числа QA-задач текст лучше картинки. Отдельная документация Playwright по ARIA snapshots описывает их как YAML-представление accessibility tree, которое можно сравнивать через expect(locator).toMatchAriaSnapshot(). Это важная точка поворота, потому что многие проверки, которые раньше пытались решать глазами агента, на самом деле лучше формализуются как структурное сравнение.
Если задача состоит в том, чтобы понять, появился ли баннер, сохранилась ли иерархия элементов, исчезла ли нужная кнопка или сломался ли текстовый контур страницы, accessibility snapshot часто даёт более проверяемый результат, чем новая порция скриншотов. Скриншот нужен там, где реально важен layout, overlap, цветовой контраст или визуальный diff. Всё остальное выгоднее переводить в текстовый или тестовый слой.
Отсюда и взрослая схема AI-first QA. Агент сначала проходит интерфейс через accessibility tree, собирает опорные ref и сценарии, после чего генерирует или обновляет обычный Playwright Test. Дальше уже npx playwright test делает работу, для которой не нужен постоянный агентный разговор. Это не отказ от ИИ. Это перенос ИИ туда, где он полезен, а не туда, где он просто дорог.
Для более широкого контекста про стоимость лишних tool-вызовов полезен наш разбор tokenmaxxing и tool-overuse у AI-агентов. В browser QA эта проблема видна особенно быстро: каждый лишний снимок страницы кажется безобидным, пока не сложится в длинную историю сессии.
Без субагентов схема всё равно остаётся хрупкой
Даже после перехода в CLI остаётся другая проблема: кто именно должен читать шумные артефакты. Если главный агент одновременно пишет тесты, смотрит логи, открывает скриншоты и сравнивает diffs, он всё равно забивает собственный контекст. Здесь и появляются субагенты.
В документации Claude Code субагенты описаны как отдельные исполнители со своим контекстным окном, системным промптом, набором tools и независимыми permissions. Anthropic прямо советует использовать их там, где побочная задача иначе завалит основной разговор логами, результатами поиска или содержимым файлов, к которым вы больше не будете возвращаться. Это почти буквальное описание QA-работы с артефактами прогона.
Есть и второй важный слой. В той же документации Claude Code можно запустить субагент в режиме isolation: worktree, чтобы он получил временную изолированную копию репозитория. На практике это означает, что исследовательский или ремонтный поток можно отцепить не только по контексту, но и по рабочему дереву. Один агент разбирает падение теста, второй обновляет spec, третий смотрит на screenshot diff. Главный разговор получает только сводку и решение, а не весь сырой шум.

Зрелый AI-first QA уже похож не на чат, а на конвейер
Лучше всего это видно по Playwright Test Agents. Официальная документация Playwright теперь уже не крутится вокруг идеи «один агент сидит в браузере до победного конца». Вместо этого платформа предлагает три раздельных роли: planner исследует приложение и строит markdown-план, generator превращает его в Playwright tests, healer прогоняет suite и чинит падающие тесты. Это и есть взрослая архитектура AI-first QA: планирование, генерация, исполнение и ремонт разведены, а не свалены в одну бесконечную сессию.
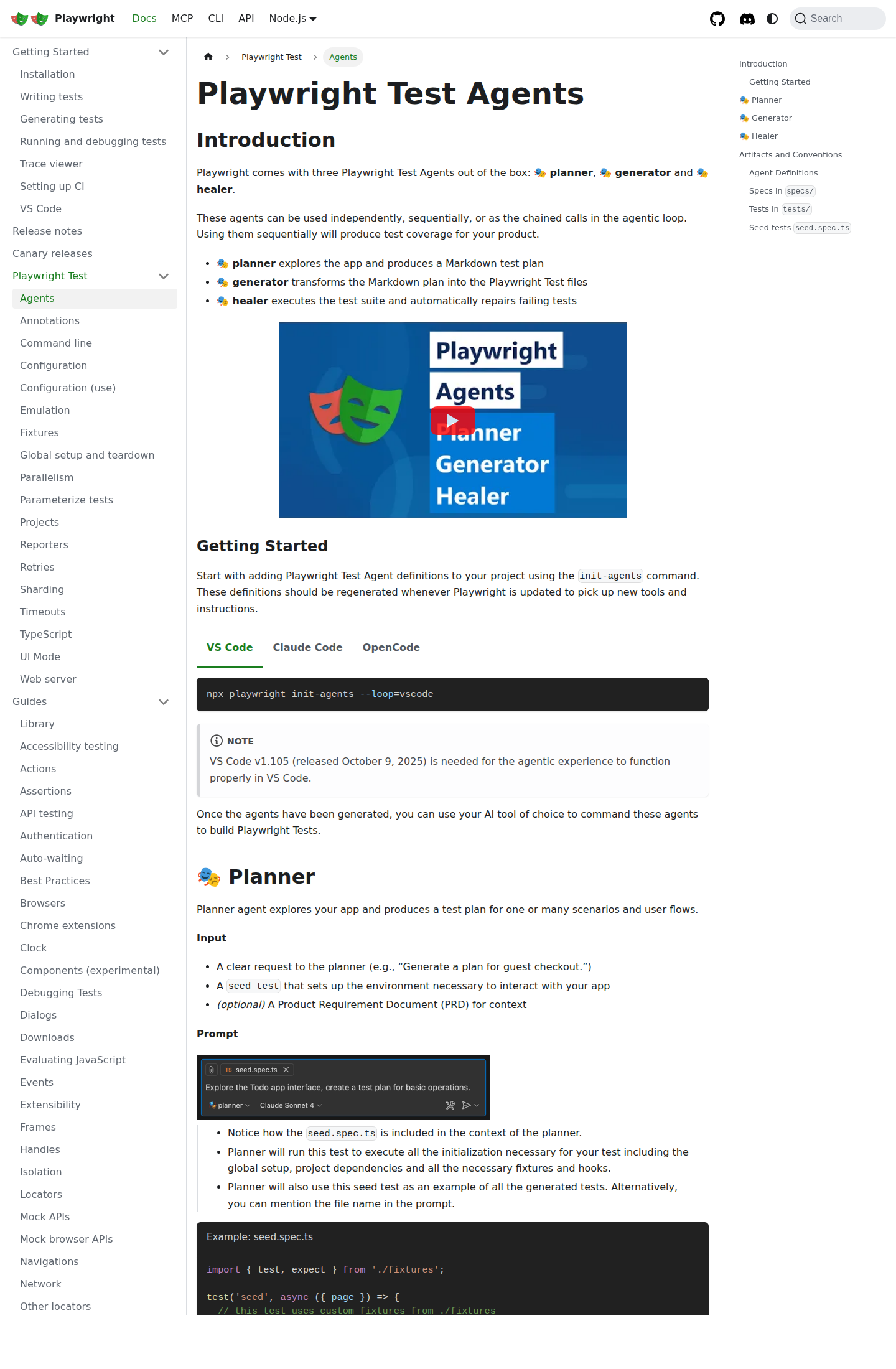
Такой контур выигрывает сразу по трём параметрам. Он дешевле, потому что не тратит дорогой агентный контекст на повторяемое исполнение. Он надёжнее, потому что статический тест можно прогнать ещё раз без новой импровизации модели. И он прозрачнее, потому что артефакты остаются в репозитории: test plan, spec, diff, лог падения.
На этом фоне пользовательский кейс с Хабра ценен не как «новый идеальный фреймворк», а как живое подтверждение того же тренда. Автор начал с одного агента в браузерном loop, а пришёл к схеме, где исследование идёт через ARIA-first подход, визуальные проверки выносятся в отдельные чтения, а повторяемый прогон живёт уже в обычном npx playwright test. Это не частная причуда. Это естественная реакция на то, как устроены контекст, изображения и стоимость tool-вызовов в 2026 году.
Тот же принцип уже работает и в более широком developer stack. В хабе ИИ для разработчиков мы как раз показывали, что главный выигрыш теперь приходит не от «ещё одной сильной модели», а от правильной раскладки труда между агентами, терминалом, репозиторием и автоматическими проверками.
Что оставить в MCP, а что увести в CLI и тесты
Практическое правило выглядит так.
- Оставляйте MCP там, где нужно быстро понять незнакомый интерфейс, найти путь пользователя, проверить гипотезу или провести короткое исследование с живым браузером.
- Уводите в CLI то, что требует длинного сценария, работы с несколькими сессиями, хранения snapshot-файлов и более дешёвой связки с кодовой базой.
- Переносите в статические Playwright tests всё, что уже стало повторяемым прогоном и не должно зависеть от новой импровизации модели.
- Выделяйте субагентов на шумные побочные задачи: чтение логов, просмотр screenshot diff, разбор падений, генерацию тест-плана, подготовку починки.
- Оставляйте визуальные проверки только там, где структура страницы не заменяет картинку: layout, overlap, pixel diff, критические UI-регрессии.
Если сказать ещё короче, MCP сегодня удобен как разведчик, CLI как рабочая лошадь, а обычный Playwright Test как слой исполнения. Ошибка начинается тогда, когда один и тот же агент пытаются заставить играть все три роли одновременно.
Вывод
AI-first QA на MCP ломается не потому, что протокол плохой, а потому, что командам слишком легко спутать быстрый exploratory интерфейс с производственным контуром тестирования. MCP отлично подходит для первых шагов в незнакомом приложении. Но длинные browser loops, визуальные проверки, код и артефакты прогона быстро начинают мешать друг другу внутри одной сессии.
Поэтому зрелая схема в 2026 году выглядит уже иначе: MCP для разведки, CLI для управляемого browser automation, ARIA snapshots для структурных проверок, статические Playwright tests для повторяемого исполнения и субагенты для шумных побочных задач. Это менее эффектно, чем обещание «один агент сам протестирует всё», зато именно такая сборка ближе к реальной инженерной работе.
Источники и дата проверки
- Playwright: Coding agents / getting started CLI, проверено 3 мая 2026 года.
- Playwright CLI: Snapshots, проверено 3 мая 2026 года.
- Playwright CLI: Sessions & Dashboard, проверено 3 мая 2026 года.
- Playwright MCP: getting started, проверено 3 мая 2026 года.
- Playwright: ARIA snapshots, проверено 3 мая 2026 года.
- Playwright Test Agents, проверено 3 мая 2026 года.
- README Playwright на GitHub, проверено 3 мая 2026 года.
- Claude Code Docs: subagents, проверено 3 мая 2026 года.
- Claude Code Docs: common workflows, проверено 3 мая 2026 года.
- OpenAI Codex CLI на GitHub, проверено 3 мая 2026 года.
- Google Gemini CLI на GitHub, проверено 3 мая 2026 года.
- Хабр: «Хотел протестировать веб-приложение через AI — за три дня собрал свой инструмент», проверено 3 мая 2026 года.



