Yandex ARGUS рекомендации: как Яндекс уходит от каскадов
Яндекс показал, как ARGUS переводит рекомендации от каскадов и ручных признаков к генеративной модели пользовательских последовательностей.
По состоянию на 27 мая 2026 года запрос «Yandex ARGUS рекомендации» стоит читать не как очередной анонс нейросети Яндекса, а как инженерный сюжет про рекомендательные системы. 21 мая Яндекс опубликовал на Хабре разбор того, как ARGUS переводят от ручных признаков и каскадов к генеративной sequential-модели, которая работает с длинной историей пользователя и кросс-сервисными сигналами.
Важная оговорка сразу: ARGUS не является YandexGPT и не похож на чат-бота. Если вам нужен обзор языковых моделей Яндекса, он живёт в отдельном кластере: мы уже разбирали YandexGPT, сценарии и ограничения моделей Яндекса. ARGUS решает другую задачу: какие треки, товары, объявления, документы или другие объекты показать пользователю дальше.
Сама тема не новая. В сентябре 2025 года Yandex уже представлял ARGUS как метод обучения рекомендательных трансформеров размером до 1 млрд параметров. Свежий текст интересен другим: он показывает, что произошло после первого анонса, какие части рецепта Яндекс упростил, где продакшен упёрся в задержки и почему генеративные рекомендации сложнее, чем красивая аналогия с LLM.
Что произошло
Исходный материал Яндекса вышел 21 мая 2026 года в корпоративном блоге на Хабре. Автор, Николай Савушкин, описывает год адаптации ARGUS под разные домены внутри Яндекса: Музыку, Маркет, Рекламу, Поиск и другие сервисы с рекомендациями.
Главный тезис простой: классические рекомендательные системы в крупных компаниях со временем становятся тяжёлыми. Они держатся на каскадах, десятках сервисов, тысячах ручных признаков и отдельных моделях под разные продукты. Такой стек надёжен, но его всё сложнее улучшать. Новая фича даёт всё меньше прироста, а операционная сложность растёт.
ARGUS пытается изменить постановку. Вместо того чтобы бесконечно наращивать ручные фичи, модель читает пользовательскую историю как последовательность событий и учится восстанавливать её распределение. Это близко к логике языковых моделей, только «словами» здесь становятся действия: просмотр, клик, покупка, пропуск трека, реакция на объявление.

Что такое ARGUS без маркетингового тумана
ARGUS расшифровывается как AutoRegressive Generative User Sequential modeling. В официальном пресс-релизе Yandex 2025 года компания описывала его как архитектуру, которая использует трансформеры для рекомендательных систем и анализирует более длинную историю взаимодействий пользователя, чем прежние подходы.
Если убрать аббревиатуры, смысл такой: пользователь представлен не статическим профилем и не набором признаков, а цепочкой событий. Модель смотрит на эту цепочку и предсказывает, какой объект или реакция вероятны дальше. Отсюда и слово «генеративная»: модель не только оценивает пару «пользователь — объект», а пытается моделировать историю целиком.
В первоначальной схеме событие кодировалось тройкой: контекст, item и действие пользователя. Контекстом может быть поверхность показа, устройство или сценарий; item — трек, товар, документ или объявление; действие — клик, покупка, лайк, пропуск и другие сигналы. В свежем разборе Яндекс пишет, что на практике часто использует упрощённую схему, где эти части упакованы компактнее.
Здесь полезна аналогия с pretrain и fine-tuning в языковых моделях, но только как аналогия. ARGUS проходит генеративный претрейн на пользовательских историях, а затем дообучается под конкретную задачу ранжирования в продукте. Это не делает его LLM. Это делает его рекомендательным трансформером с похожей двухступенчатой логикой обучения.
Почему каскады стали узким местом
Классический стек рекомендаций обычно делится на генерацию кандидатов и ранжирование. Сначала лёгкая модель быстро выбирает сотни или тысячи объектов из огромного каталога. Затем более тяжёлая модель сортирует этот набор под конкретного пользователя и контекст. На практике между этими стадиями много фильтров, сервисов и ручных признаков.
Это нормально, пока продукт небольшой или команда хорошо понимает, какие признаки действительно работают. Проблемы начинаются на масштабе Яндекса. У разных сервисов разные каталоги, разные реакции пользователя, разная частота событий и разные ограничения по задержке. Музыка, Маркет и Реклама не похожи друг на друга, но пользователь один и тот же.
Именно здесь генеративная постановка выглядит заманчиво. Если модель может учиться на обезличенной истории действий сразу из нескольких доменов, она получает сигнал шире, чем один сервис. Покупки в Маркете, поисковые действия, музыкальные реакции и рекламные показы не становятся одной «магической» фичей, но помогают лучше представить пользователя.
Это связывает ARGUS с потребительскими сценариями Яндекса, но не сводит его к ним. Например, мы отдельно писали про ИИ-агента Яндекса для покупок; там фокус на пользовательском e-commerce-сценарии. В ARGUS фокус ниже уровнем: как обучить модель, которая даёт более сильные сигналы для таких сервисов.
Как устроен новый рецепт ARGUS
Самая важная часть свежего разбора — не само слово «генеративный», а изменения в рецепте обучения. Яндекс пишет, что первые версии ARGUS работали офлайн: модель раз в сутки прогоняла пользовательские и item-представления, а затем использовалась как источник сигналов и кандидатов. Это удобно для инфраструктуры, но плохо видит свежие действия пользователя и сжимает историю в один вектор.
Дальше команда перешла к context-aware-постановке. Контекст перестал быть чем-то, что подставляют только на последнем шаге. Его стали включать в саму последовательность: сначала контекстный токен, затем события, связанные с этим контекстом. Так модель раньше видит, где именно происходит действие, а не пытается восстановить эту связь в конце.
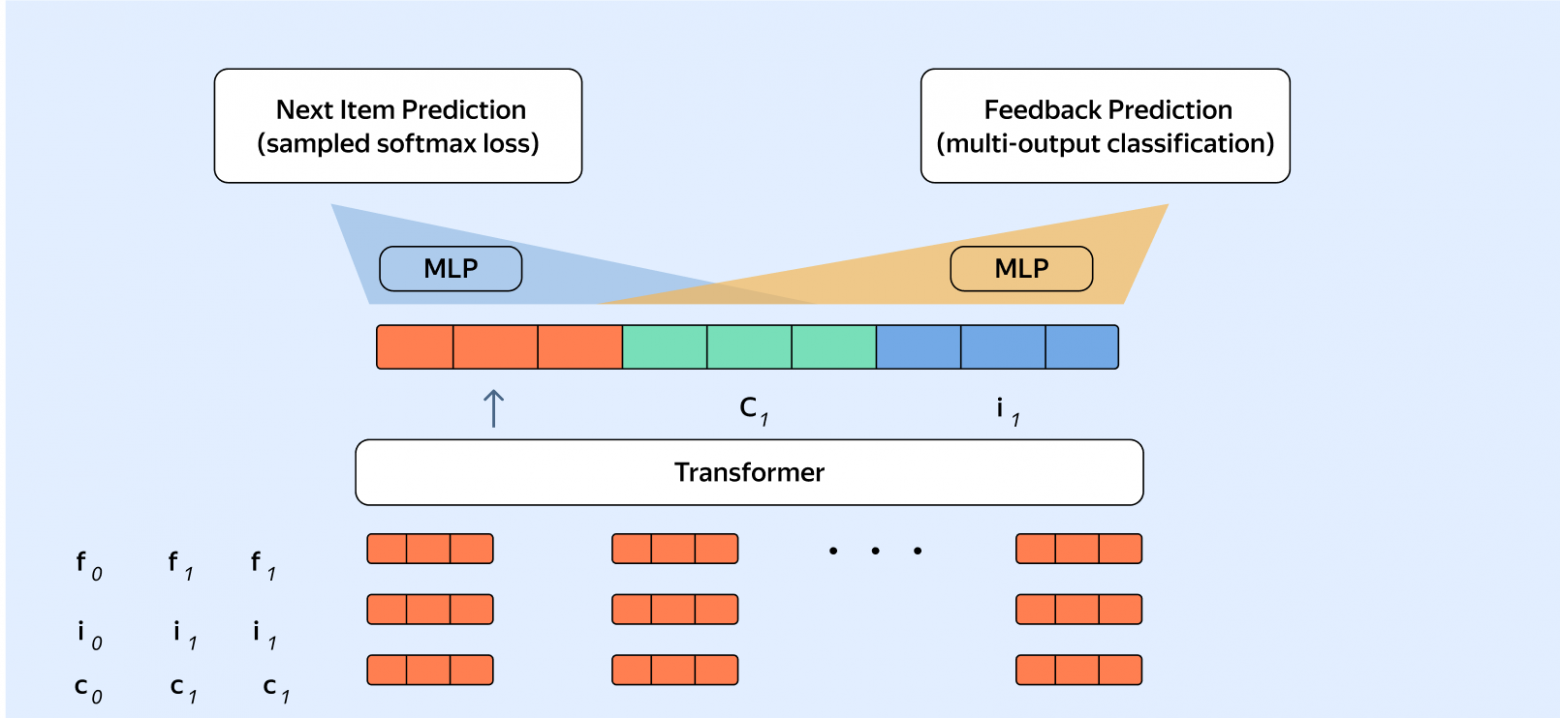
Ещё один важный сдвиг — кросс-сервисный претрейн. В свежем рецепте ARGUS добавляет Next-Item Prediction не только для целевого сервиса, но и для событий из дополнительных доменов. По словам Яндекса, именно эта часть даёт особенно заметный рост качества в downstream-ранжировании.
Есть и редакционно важная деталь. В пресс-релизе 2025 года среди ключевых инноваций упоминались multi-headed learning objectives: next-item prediction и feedback prediction. В свежем тексте Яндекс уточняет, что в актуальном рецепте feedback-loss убрали: он почти не помогал финальному качеству, усложнял реализацию и снижал стабильность обучения. Это хороший пример того, как исследовательский анонс меняется после продакшен-проверки.
Где продакшен ломает красивую идею
На бумаге всё звучит аккуратно: берём длинную историю пользователя, подаём её в трансформер, получаем более сильные рекомендации. В продакшене быстро появляются неприятные детали.
Первая — задержка данных. В распределённой системе событие не мгновенно попадает в профиль пользователя. Если при обучении этого не учитывать, модель начинает видеть то, чего в реальном рантайме ещё нет. Яндекс прямо пишет, что это приводит к переобучению и эффекту «видит будущее».
Вторая — маски внимания. Для context-aware-постановки нужна нетривиальная маска, которая учитывает текущий контекст и не пускает в модель события, ещё недоступные в момент рекомендации. По словам Яндекса, Flash Attention такую маску не поддерживает, а альтернативы замедляют обучение. В итоге лаг решили моделировать ниже по стеку, в downstream-модели, а не усложнять трансформер.
Третья — latency. Свежий контекст требует выполнять трансформер ближе к рантайму, а рекомендации живут в миллисекундах. Поэтому ARGUS не «заменяет всё одной моделью». Он может быть фичегенератором для следующего ранжировщика или дополнительным источником кандидатов. Это важнее громкого тезиса про универсальную модель: в реальном сервисе выигрывает не самая красивая архитектура, а та, которая проходит по задержкам и стоимости.
Что это значит для Яндекса и рынка
Yandex в пресс-релизе 2025 года утверждал, что ранние внедрения ARGUS уже улучшали total listening time, вероятность клика и сценарии discovery. В свежем Хабр-разборе формулировки осторожнее: говорится о заметном росте downstream-метрик в доменах, где контекст особенно важен, например в Рекламе, Поиске и doc2doc-рекомендациях. Для Музыки, где сильнее персональный фактор, прирост скромнее.
Это звучит менее эффектно, зато полезнее. Рекомендации не становятся одинаковыми во всех продуктах. В одном домене важен контекст, в другом — долгосрочный вкус, в третьем — свежесть каталога и сезонность. ARGUS интересен тем, что даёт общую основу, но не отменяет доменные различия.
Для рынка вывод такой: большие рекомендательные системы движутся в ту же сторону, что и языковые модели несколько лет назад. Больше данных, длиннее контекст, трансформеры, претрейн, перенос между доменами. Но ограничения другие. Здесь нельзя просто ждать ответа несколько секунд. Рекомендательная модель должна встроиться в каскад, выдержать миллисекундные бюджеты и не испортить уже работающий бизнес-процесс.
Главное
Yandex ARGUS рекомендации — это не история про «Яндекс выпустил новую LLM». Это история про то, как крупная продуктовая компания пытается заменить часть ручного фичевого труда и каскадной сложности более общей моделью пользовательских последовательностей.
Самое ценное в свежем разборе не обещание универсальности, а честные инженерные детали: context-aware-токенизация, кросс-сервисный претрейн, отказ от feedback-loss, борьба с задержками данных и осторожное применение ARGUS как upstream-модели. Так выглядит не пресс-релиз, а нормальная эволюция технологии после контакта с продакшеном.
Читайте также
- YandexGPT: обзор моделей, цен и сценариев в 2026 году
- ИИ-агент Яндекса для покупок: как Алиса AI ищет дешевле
- Fine-tuning LLM: когда дообучение оправдано и как выбрать метод
Источники и проверка фактов
- Яндекс на Хабре: «От фич и каскадов к генеративной модели: как мы переосмыслили рекомендации с помощью ARGUS», опубликовано 21 мая 2026 года, проверено 27 мая 2026 года.
- Yandex: «Yandex presents a method for training large transformer recommenders with up to 1B parameters», опубликовано 2 сентября 2025 года, проверено 27 мая 2026 года.
- arXiv: «Scaling Recommender Transformers to One Billion Parameters», проверено 27 мая 2026 года.
- Яндекс на Хабре: «ARGUS: как масштабировать рекомендательные трансформеры», опубликовано 20 июня 2025 года, проверено 27 мая 2026 года.