World Action Models для робототехники: роботы с прогнозом действий
World Action Models связывают прогноз физического будущего с выбором действия робота. Разбираем WAM без обещаний готовой автономности.
По состоянию на 26 мая 2026 года термин World Action Models для робототехники обозначает попытку собрать новый класс подходов вокруг роботов. В препринте World Action Models: The Next Frontier in Embodied AI, опубликованном на arXiv 12 мая 2026 года, исследователи из Fudan University, Shanghai Innovation Institute и National University of Singapore описывают WAM как модели, которые связывают прогноз будущего состояния мира с генерацией действия.
Идея простая: робот не только видит кадр с камеры и выбирает движение, но и заранее оценивает, как сцена изменится после этого движения. Для манипуляции объектами это принципиальная разница. Если система умеет предсказывать последствия, она получает шанс переносить навык на незнакомые предметы и использовать видео, где нет размеченных роботизированных действий.
Из этого нельзя делать вывод, что роботы уже стали автономными или безопасными. Работа Wang et al. — survey и таксономия, а не релиз готового продукта. Но сам поворот важен: после Vision-Language-Action моделей, которые сопоставляли наблюдение и действие, исследователи всё чаще хотят дать роботу внутреннюю модель физического будущего.
Что такое World Action Models
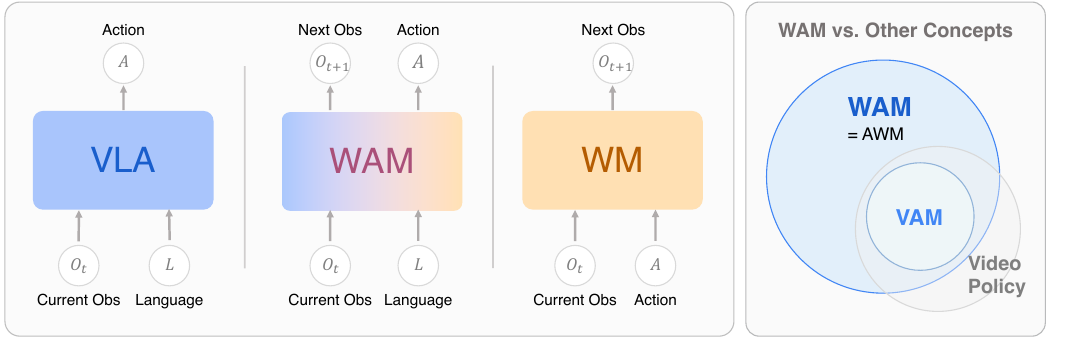
Авторы определяют World Action Models как embodied foundation models, которые объединяют predictive state modeling и action generation. В русском тексте это лучше читать так: WAM пытается одновременно предсказать будущую сцену и подобрать действие, которое к ней ведёт.
| Подход | Что получает на вход | Что выдаёт | Главное ограничение |
|---|---|---|---|
| VLA | Наблюдение и языковую инструкцию | Действие | Не моделирует явно, как изменится физическая сцена |
| World Model | Наблюдение и гипотетическое действие | Следующее состояние сцены | Само по себе не выбирает моторную команду |
| WAM | Наблюдение, инструкцию и контекст задачи | Будущее состояние и действие | Пока дорого считается и плохо проверяется едиными метриками |
В этом месте WAM пересекаются с темой ИИ-агентов. Обычная LLM отвечает текстом; агентная система должна планировать и действовать. В физическом мире действие нельзя откатить так же легко, как текстовый ответ. Поэтому для робототехники особенно важен шаг между «вижу объект» и «двигаю манипулятор»: модель должна хотя бы грубо оценить, что произойдёт после движения. Это хорошо дополняет наш базовый разбор о том, что такое ИИ-агенты и когда они действительно нужны.
Две архитектуры: сначала представить или всё считать вместе
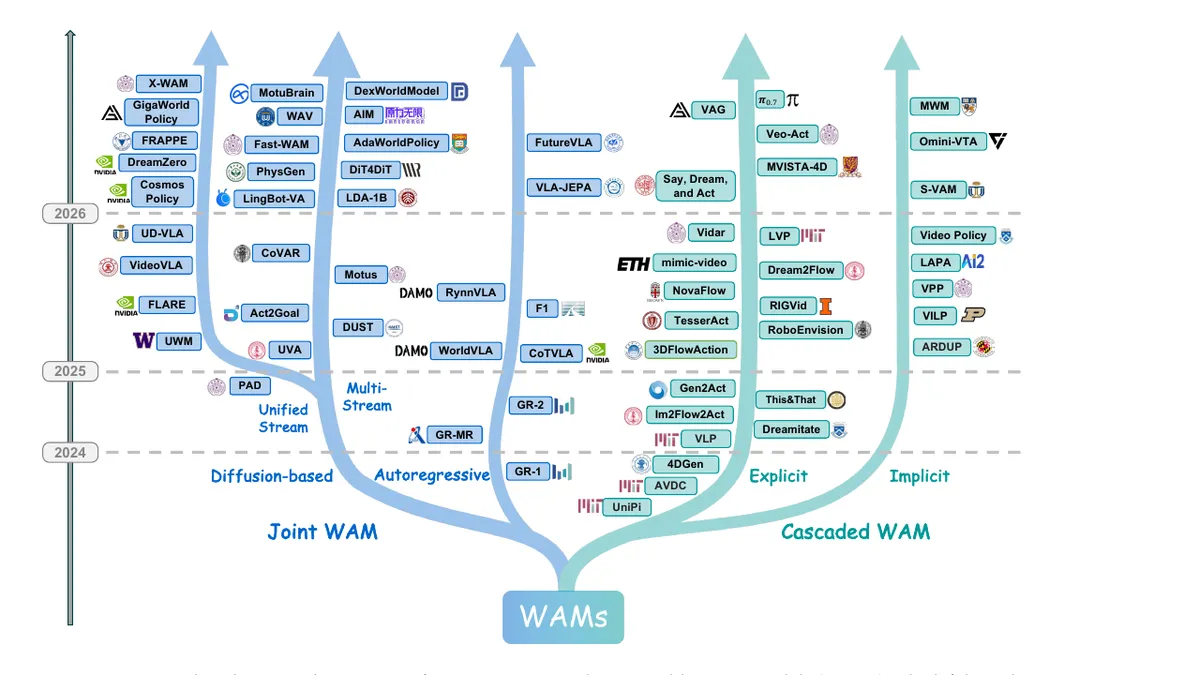
В survey авторы разводят WAM на две большие ветки: Cascaded WAM и Joint WAM. Разница не косметическая, потому что от неё зависит задержка, качество прогноза и то, насколько легко объяснить поведение системы.
Cascaded WAM работает в два этапа. Сначала world model генерирует будущую сцену: кадр, видео, плотное поле движения или латентное представление. Затем отдельный модуль извлекает из этого плана конкретные команды. В эту линию попадают UniPi, VLP, AVDC, VPP, LAPA и другие работы из списка OpenMOSS.
Joint WAM пытается связать прогноз и действие внутри одной модели. В одних вариантах изображения и действия превращаются в общую последовательность токенов, как у GR-1, GR-2 или WorldVLA. В других будущее состояние и движение генерируются параллельно, например в diffusion-based подходах вроде PAD, UWM или DreamZero. Такой путь потенциально быстрее на уровне пайплайна, но сложнее для обучения и проверки.
На практике это похоже на развилку между прозрачностью и плотной интеграцией. Cascaded-подход проще объяснить: сначала «воображаем» будущую сцену, затем выбираем движение. Joint-подход меньше похож на конвейер, но сильнее зависит от того, как именно модель кодирует действия, изображения и будущие состояния.
Почему WAM важны для данных
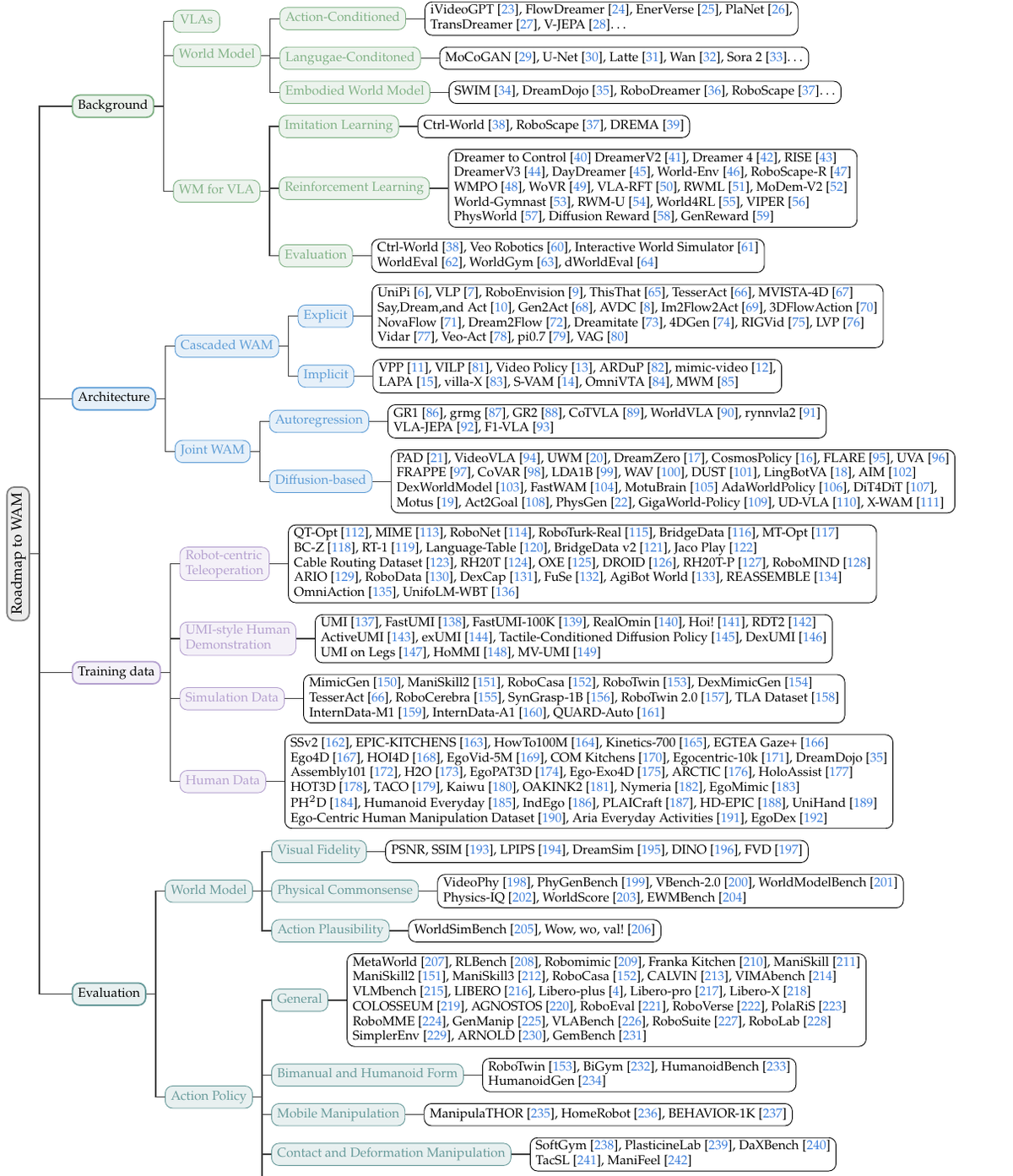
Практическая ценность WAM — расширить источники обучающих данных, а не просто получить красивое видео будущего. Робототехника годами упирается в дорогую разметку: чтобы обучить манипулятор, нужно собрать траектории, команды, состояния захвата, данные сенсоров и повторить это в разных сценах. Обычные видео людей полезны, но в них нет прямой команды для робота.
Survey выделяет четыре крупных источника данных для WAM: теледействия роботов, переносимые человеческие демонстрации, симуляции и интернет-масштабные egocentric video. У каждого источника свой компромисс. Теледействия дают точные действия, но дорого масштабируются. Симуляции дают идеальные глубину, столкновения и позы объектов, но страдают от разрыва между симуляцией и реальным миром. Видео от первого лица дают разнообразие, но почти всегда лишены роботизированных action labels.
Здесь WAM выглядят особенно полезно. Если модель учится предсказывать изменение сцены, ей можно дать видео без размеченного моторного действия. В работе приведены характерные масштабы: Ego4D содержит более 3600 часов egocentric video, HowTo100M — 136 млн клипов, DreamDojo — 44 000 часов crowdsourced activities, а набор данных рядом с RDT2 даёт примерно 10 000 часов демонстраций в сотнях реальных сцен. Эти числа не делают задачу решённой, но показывают, почему исследователи смотрят за пределы классических роботизированных датасетов.
В этом смысле WAM близки к более широкому кластеру physical AI. У нас уже был текст о том, зачем Яндексу Physical AI Garage: там фокус на людях, стендах и инженерной среде. Здесь фокус другой — на модели, которая должна связать физическое предсказание и действие. Оба направления упираются в одну проблему: без данных, железа и проверки на реальных сценах красивый термин мало что значит.
Оценка пока отстаёт от разработки
Сейчас WAM хуже всего проверяются. Авторы прямо пишут, что визуальные метрики вроде PSNR, SSIM или FVD могут оценивать правдоподобие картинки, но плохо отвечают на вопрос, поможет ли этот прогноз управлять роботом. Видео может выглядеть реалистично и всё равно нарушать физику: предмет зависает в воздухе, столкновение не учитывается, контакт с поверхностью выглядит красиво, но не даёт исполнимой траектории.
Часть новых бенчмарков закрывает отдельные фрагменты: VideoPhy проверяет физические взаимодействия, Physics-IQ — события из реальных видео, WorldSimBench — применимость сгенерированного будущего для манипуляции. Но единой метрики причинной согласованности между «воображаемым будущим» и реальным действием пока нет. Для робототехники это серьёзнее, чем для генерации видео: ошибка модели может перейти в длинную цепочку движений.
Есть и вычислительная проблема. В разделе open challenges авторы пишут, что DreamZero приблизил WAM inference к 7 Hz, но это всё ещё заметно ниже 50 Hz, которые они называют стандартом современных non-generative VLA policies. Для робота, работающего в замкнутом контуре, задержка — не мелочь. Чем медленнее модель предсказывает будущее, тем труднее использовать её в быстрых контактных задачах.
Что это меняет для робототехники
World Action Models хорошо объясняют, почему API для роботов и пространственное рассуждение решают только часть задачи автономности. Например, в материале про Gemini Robotics-ER 1.6 речь шла о том, как Google даёт разработчикам доступ к reasoning-слою для embodied задач. WAM добавляют к этой картине другой вопрос: проверяет ли система последствия своего действия до того, как распознанная сцена превратится в команду.
Для разработчиков и исследователей отсюда выходит три практичных вывода. Во-первых, надо проверять не только точность действия, но и качество физического прогноза. Во-вторых, стоит отдельно измерять action plausibility: можно ли из предсказанного будущего получить исполнимую траекторию. В-третьих, контактные задачи потребуют не только камеры, но и силу, тактильные сенсоры, проприоцепцию и более строгую проверку безопасности.
Самый интересный сценарий — prediction-integrated safety. Если модель умеет предсказывать будущее, она может выбирать движение и заранее отбрасывать опасные варианты. Пока это скорее направление исследований, чем готовый промышленный контур. В такой роли WAM становятся полезнее обычной «видеофантазии»: ценность прогноза в более осмысленном действии, а картинка — только один из способов этот прогноз выразить.
Главное
World Action Models для робототехники — это попытка сшить две вещи, которые раньше часто жили отдельно: модель мира и генерацию действия. Вместо прямого перехода от кадра к команде WAM добавляет промежуточный слой физического предсказания.
Текущий статус осторожный: есть survey, таксономия, десятки направлений и быстро растущий список работ, но нет доказательства, что WAM уже решают автономность или безопасность роботов. Ценность материала в другом. Он показывает, куда сдвигается робототехника: от реактивных VLA-моделей к системам, которые должны сначала понять возможные последствия движения, а потом действовать.
Читайте также
- Gemini Robotics-ER 1.6: зачем Google дала роботам новый API
- Yandex Physical AI Garage: зачем Яндексу 100 мест для физического ИИ
- ИИ-агенты: что это и когда они действительно нужны
Источники и проверка фактов
- arXiv: World Action Models: The Next Frontier in Embodied AI, v1 от 12 мая 2026 года, проверено 26 мая 2026 года.
- OpenMOSS/Awesome-WAM, репозиторий и таксономия работ по WAM, проверено 26 мая 2026 года.
- The Decoder: World Action Models give robots the ability to simulate consequences before they move, опубликовано 17 мая 2026 года, проверено 26 мая 2026 года.



