Gemini Robotics-ER 1.6: зачем Google дала роботам новый API
Google DeepMind выпустила Gemini Robotics-ER 1.6 для рассуждений в физическом мире: API полезен роботам, но не делает их автономными сам по себе.

Gemini Robotics-ER 1.6 - не «робот Gemini» и не готовый мозг для гуманоидов. Это новая версия модели Google DeepMind для рассуждений в физическом мире: она смотрит на изображения, видео или аудио, понимает естественные команды и возвращает структурированный результат, который можно передать контроллеру робота, VLA-модели или пользовательской функции.
14 апреля 2026 года Google DeepMind представила Robotics-ER 1.6 как обновление для задач робототехники: пространственное рассуждение, понимание нескольких камер, чтение приборов и соблюдение физических ограничений безопасности. В журнале изменений Gemini API модель указана как `gemini-robotics-er-1.6-preview`, а документация Google AI Developers называет её предварительной версией, доступной для экспериментов через Gemini API и Google AI Studio.
По состоянию на 15 апреля 2026 года это релиз для разработчиков. Разработчику дают не потребительский продукт, а новый слой рассуждения для робота. Если нужен общий контекст по линейке Google, у нас есть отдельный разбор про семейство Gemini; здесь важен более узкий вопрос: как LLM-подобная модель становится частью физического агента.
Что вышло 14 апреля 2026
В официальной документации Gemini Robotics-ER 1.6 описана как визуально-языковая модель для робототехники. Она принимает текст, изображения, видео и аудио, а на выходе отдаёт текст. Для предварительной версии Google указывает модельный код `gemini-robotics-er-1.6-preview`, входной лимит 1 048 576 токенов и выходной лимит 65 536 токенов.
Смысл не в том, что модель сама управляет моторами. Она должна понимать сцену и задачу: находить объекты, оценивать отношения между ними, планировать точки или траектории, разбивать длинную команду на подзадачи и вызывать существующие функции робота. Документация прямо говорит, что результат можно использовать с robotics API, VLA-моделью или сторонними пользовательскими функциями.
Это важное разделение. В статье про AI-агентов мы писали о системах, которые не просто отвечают, а выбирают действия. В робототехнике цена ошибки выше: агент действует не в браузере и не в IDE, а рядом с предметами, людьми и оборудованием.
API для роботов, а не готовый робот
Robotics-ER 1.6 лучше воспринимать как верхний reasoning-слой. Он помогает понять, что находится перед роботом и что с этим делать дальше, но не заменяет камеры, приводы, контроллеры, карты окружения, VLA-модель и полевые тесты.
Типичный сценарий выглядит так: робот или стенд передаёт в Gemini API изображение рабочей зоны и текстовую команду. Модель возвращает координаты объектов, рамки объектов, промежуточные точки траектории, план подзадач или аргументы для функции. После этого уже внешний слой решает, можно ли выполнять движение, какой манипулятор использовать, какие проверки безопасности включить и нужно ли запросить подтверждение.
Поэтому громкие формулировки вроде «Google выпустила автономных роботов» здесь вредят пониманию. Google выпустила модель рассуждения для робототехники. Между таким API и надёжным промышленным роботом остаётся длинная инженерная цепочка.
Что улучшилось в рассуждении
Главные улучшения DeepMind группирует вокруг embodied reasoning - рассуждения с учётом тела и среды. В статье Google выделяет пространственное рассуждение, работу с несколькими камерами и чтение промышленных приборов.
Пространственное рассуждение нужно, чтобы модель не просто узнавала объект, а понимала его положение и связь с задачей. Например, она может поставить точки на нужные предметы, не указывать на отсутствующие объекты и использовать эти точки как промежуточные шаги для счёта или оценки расстояний.
Оценка успеха по нескольким камерам - отдельный практический кусок. В роботах часто есть несколько камер: верхняя, фронтальная, камера на запястье манипулятора. Модель должна понять, что это не три независимые картинки, а разные взгляды на одну задачу. DeepMind приводит пример с определением завершения команды «положи синюю ручку в чёрную подставку» по нескольким ракурсам.
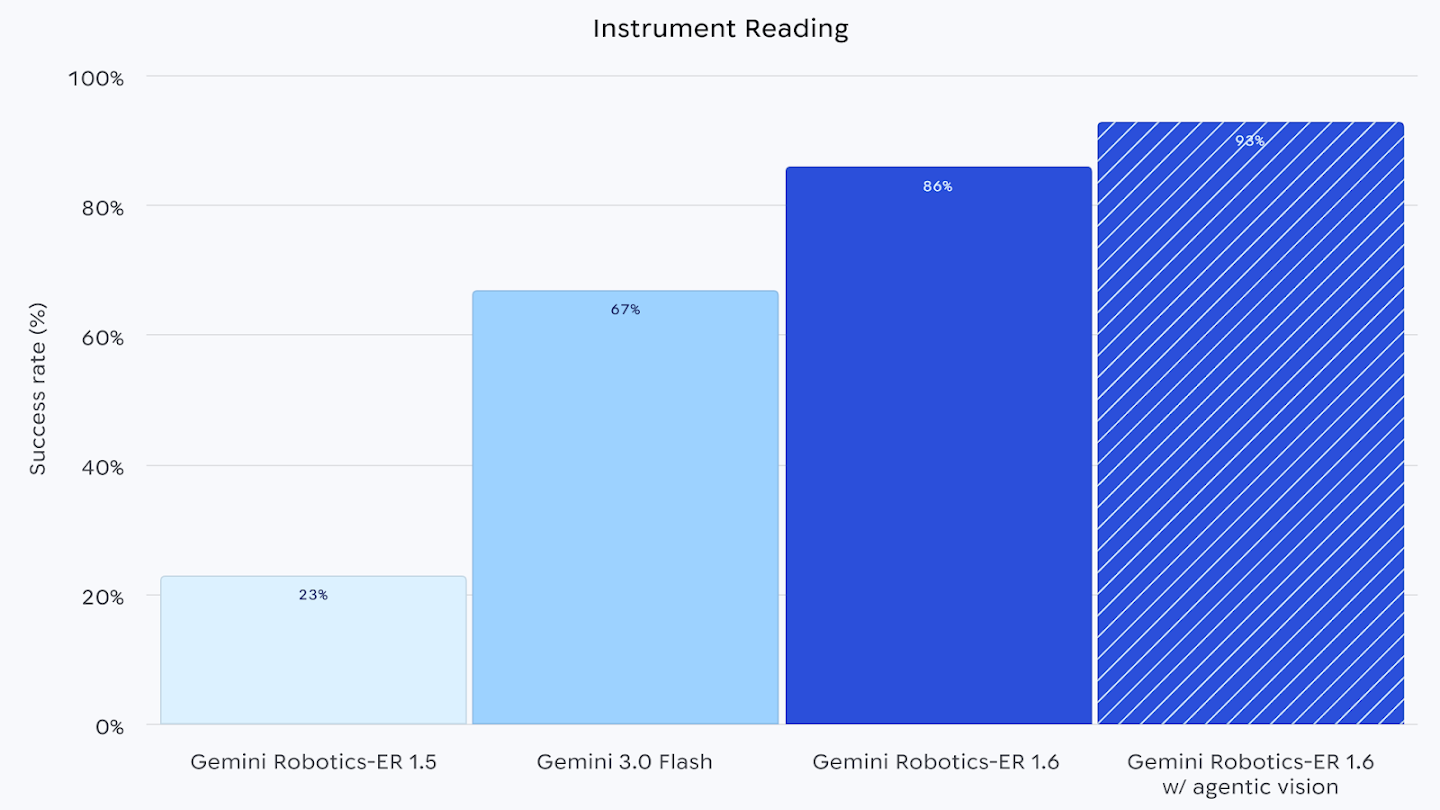
Самый наглядный пример - чтение приборов. DeepMind пишет о манометрах, термометрах, вертикальных уровнях жидкости и цифровых табло в промышленных объектах. Для такого чтения мало «увидеть стрелку»: нужно разобрать шкалу, деления, единицы измерения, перспективное искажение, несколько стрелок и текст на приборе. По графику Google DeepMind, Robotics-ER 1.6 показывает 86% успешных ответов на этой задаче, а связка с agentic vision - 93%.
Рассуждение о безопасности и ASIMOV
Второй крупный блок - безопасность. DeepMind называет Gemini Robotics-ER 1.6 своей самой безопасной моделью для робототехники на момент анонса. Компания отдельно говорит о физических ограничениях: не брать жидкости, не поднимать объекты тяжелее 20 кг, учитывать материал и ограничения захвата.
Это не абстрактная «этика ИИ». Для робота safety reasoning означает, что модель должна связать текстовую инструкцию, картинку и физические последствия. «Возьми чашку» и «возьми горячую чашку рядом с ребёнком» - разные задачи. Ошибка здесь может быть не просто неправильным ответом, а повреждением вещи или травмой.
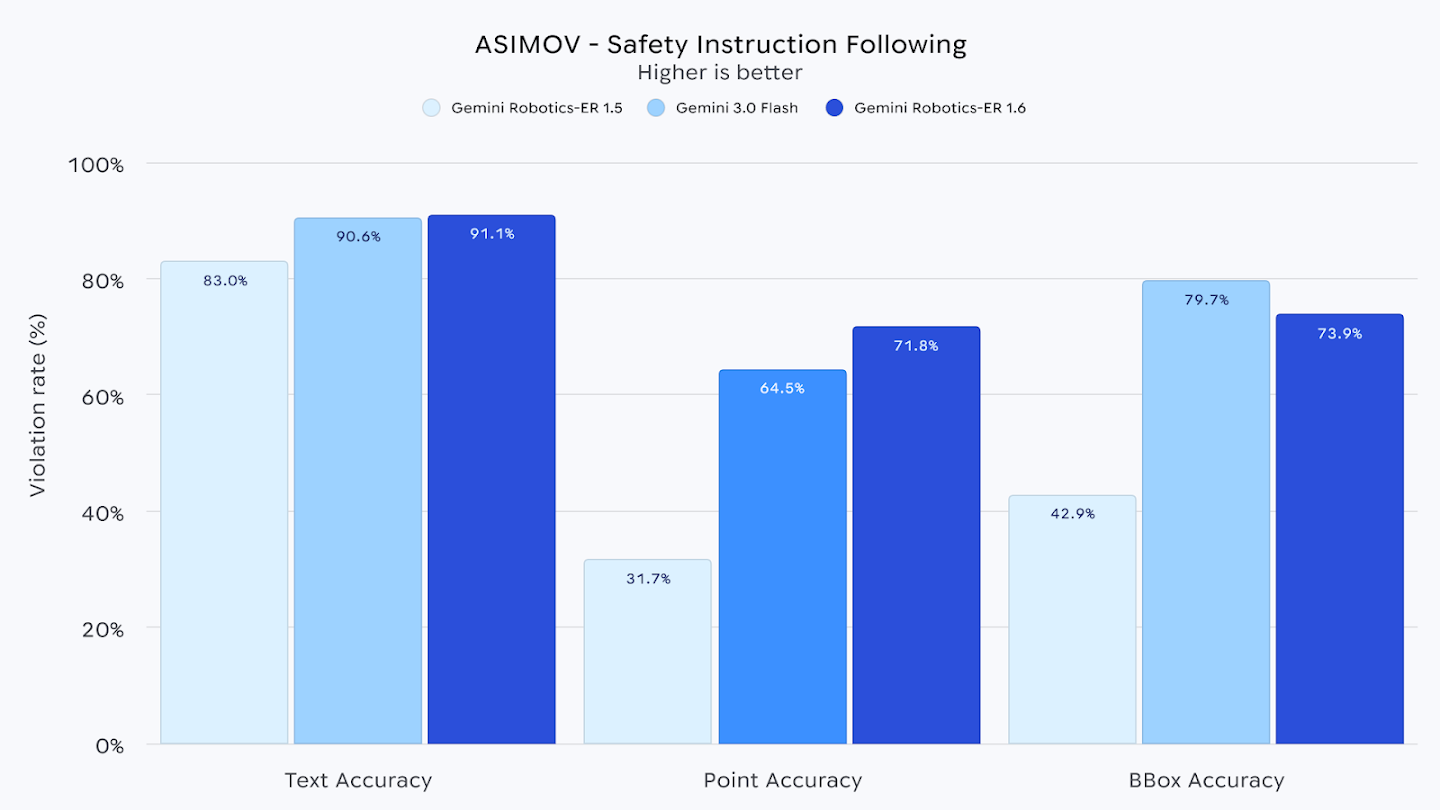
Для проверки Google использует сценарии ASIMOV Benchmark. Проект ASIMOV формулирует вопрос жёстко: может ли ИИ распознать физическую опасность и вмешаться. В анонсе DeepMind пишет, что Robotics-ER-модели улучшили восприятие рисков относительно Gemini 3.0 Flash на текстовых и видеосценариях, основанных на реальных отчётах о травмах: +6% в тексте и +10% в видео.
Но это не снимает ответственность с разработчика. Документация Google отдельно предупреждает: модель находится в предварительном статусе, генеративный ИИ может ошибаться, а физические роботы способны причинить ущерб. Там же есть уведомление о конфиденциальности: если робот собирает голос, изображение или другие данные людей, оператор должен уведомлять людей, получать согласие там, где это требуется, и минимизировать сбор данных, например размывать лица.
Границы релиза
Главная граница - статус предварительной версии. Google прямо пишет, что API и возможности могут меняться, а критичные для эксплуатации применения требуют тщательного тестирования. Для робототехники это не формальность: модель может галлюцинировать, запрос влияет на качество ответа, сложные задачи и большой thinking budget увеличивают задержку и стоимость.
Вторая граница - зависимость от внешней системы. Robotics-ER 1.6 может найти объект и предложить точки траектории, но физическое действие выполняет не она. Нужны контроллеры, ограничения движения, аварийная остановка, валидация сенсорами, тесты на конкретном оборудовании и понятная политика, что делать при неопределённости.
Третья граница - рынок. Сейчас это не массовый робот, а модельный слой для команд, которые уже строят робототехнические системы. На фоне новостей вроде Amazon Fauna Robotics и робота Sprout это менее зрелищно, зато ближе к тому, что реально нужно разработчикам: не обещание «универсального робота», а API, который можно встроить в существующую архитектуру.
Почему это важно для разработчиков
Для разработчиков Robotics-ER 1.6 показывает, куда смещается интерфейс робототехники. Раньше большая часть логики жила в специализированных цепочках компьютерного зрения, правилах и контроллерах. Теперь появляется слой, который может понимать естественную команду, смотреть на несколько сенсоров, вызывать инструменты и возвращать структурированный результат.
Это удобно, но опасно, если воспринимать модель как магический модуль автономности. Правильнее думать о ней как о компоненте в цепочке: восприятие, рассуждение, планирование, действие, проверка безопасности, журналирование. Чем ближе система к физическому миру, тем меньше права на «модель вроде бы поняла».
Практический вывод простой: если команда тестирует Robotics-ER 1.6, ей нужен не только API-ключ. Нужны наборы изображений из реальной среды, сценарии отказов, тесты на границы, журналирование запросов и отдельные проверки для ситуаций, где ошибка может повредить объект или человека.
Итог
Gemini Robotics-ER 1.6 - важный релиз не потому, что Google «выпустила робота». Важен другой сдвиг: Gemini API получает модель, специально настроенную на физический мир, промышленное зрение, многоракурсное понимание и safety constraints.
Если коротко: это шаг к роботам, которые лучше понимают сцену перед собой. Но автономность всё ещё создаётся всей системой вокруг модели, а не одной моделью в API.