Whisper, TTS и голосовой ИИ: обзор технологий распознавания и синтеза речи
Обзор голосовых ИИ-технологий: распознавание речи Whisper, синтез речи ElevenLabs, OpenAI TTS. Практическое применение и сравнение.

Голосовые технологии — одна из самых зрелых областей ИИ. Распознавание речи (STT — speech-to-text) и синтез речи (TTS — text-to-speech) прошли путь от роботизированных голосов и 70% точности до моделей, которые транскрибируют лучше людей и генерируют речь, неотличимую от человеческой.
Распознавание речи: Whisper
OpenAI выпустила Whisper в сентябре 2022 года как open-source модель для распознавания речи. За два года Whisper стал де-факто стандартом для транскрибации — и не без причины.
Что умеет Whisper
- Транскрибация — превращение аудио в текст с точностью, превосходящей коммерческие сервисы на многих языках
- Перевод — транскрибация с переводом на английский в одном шаге
- Определение языка — автоматическая детекция среди 99 языков
- Временные метки — привязка текста к моментам в аудио (word-level timestamps)
Whisper обучен на 680 000 часов аудио с разметкой, собранных из интернета. Модель мультиязычная: поддерживает русский, украинский, белорусский и десятки других языков.
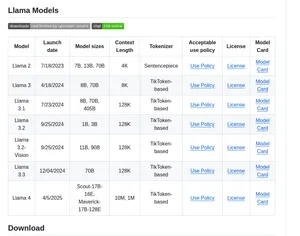
Размеры модели
Whisper доступен в пяти размерах:
- tiny (39M параметров) — быстрый, но менее точный. Подходит для предварительной обработки.
- base (74M) — баланс скорости и качества для простых задач
- small (244M) — хорошее качество на потребительском железе
- medium (769M) — высокое качество, заметно лучше на сложных акцентах и шуме
- large-v3 (1.5B) — максимальное качество. Для русского языка заметно точнее, чем меньшие версии
Запуск Whisper
# Установка
pip install openai-whisper
# Транскрибация
whisper audio.mp3 --model large-v3 --language ru# Python API
import whisper
model = whisper.load_model("large-v3")
result = model.transcribe("audio.mp3", language="ru")
print(result["text"])Для ускорения — faster-whisper: реализация на CTranslate2, которая работает в 4 раза быстрее оригинала при том же качестве. Whisper large-v3 через faster-whisper транскрибирует час аудио за 3–5 минут на GPU.
Whisper через API
OpenAI предоставляет Whisper через API: $0.006 за минуту аудио. Не нужен GPU — загружаете файл, получаете текст. Для задач, где нет требований к конфиденциальности, это простейший вариант. Подробнее о возможностях — в нашем материале Whisper от OpenAI: транскрибация, перевод и распознавание речи.
Синтез речи: от роботов к живым голосам
Синтез речи за последние три года совершил качественный скачок. Голоса нового поколения передают интонации, паузы, эмоции. Не все — некоторые по-прежнему звучат синтетически. Но лучшие — почти неотличимы от человеческой речи.
OpenAI TTS
OpenAI TTS (ноябрь 2023) — два голосовых движка:
- tts-1 — оптимизирован для скорости и потоковой передачи. Используется в реальном времени (чат-боты, ассистенты). Качество хорошее, но при внимательном прослушивании слышна синтетичность.
- tts-1-hd — оптимизирован для качества. Для подкастов, аудиокниг, озвучки видео.
Шесть голосов на выбор. Стоимость: $15 за миллион символов (tts-1), $30 за миллион (tts-1-hd). Поддержка русского языка — есть, но качество заметно ниже английского.
ElevenLabs
ElevenLabs — стартап, который стал лидером в качестве голосового синтеза. Ключевые возможности:
- Voice cloning — создание цифровой копии голоса по 1–5 минутам аудиозаписи. Клонированный голос сохраняет тембр, интонации, акцент оригинала.
- Мультиязычность — один клонированный голос говорит на 29 языках, включая русский, сохраняя характеристики оригинала
- Эмоции и стили — управление интонацией: нейтральная, весёлая, серьёзная, шёпот
Стоимость: от $5/месяц (30 минут аудио) до $330/месяц (200 часов). Бесплатный тариф: 10 минут в месяц.
ElevenLabs используется для дубляжа фильмов, озвучки аудиокниг, создания голосовых ассистентов и клонирования голосов для людей, потерявших способность говорить.
Open-source: Coqui TTS, Bark, XTTS
Coqui XTTS — open-source модель с поддержкой клонирования голоса. Качество ниже ElevenLabs, но модель можно запустить локально и дообучить на своих данных. Поддерживает русский.
Bark от Suno — open-source модель, генерирующая не только речь, но и музыку, звуковые эффекты, смех. Нестабильна в качестве, но уникальна по возможностям.
Голосовые ассистенты нового поколения
Объединение STT + LLM + TTS создаёт голосовых ассистентов, которые слушают, думают и отвечают голосом. GPT-4o от OpenAI обрабатывает аудио нативно — без промежуточной транскрибации. Модель «слышит» интонацию, определяет эмоции говорящего и генерирует ответ с соответствующей интонацией. Задержка — менее 500 мс.
Для собственного голосового ассистента:
# Минимальный голосовой ассистент: Whisper + Claude + OpenAI TTS
import whisper
import anthropic
from openai import OpenAI
# 1. Распознавание
stt_model = whisper.load_model("base")
result = stt_model.transcribe("user_audio.wav", language="ru")
user_text = result["text"]
# 2. Генерация ответа
claude = anthropic.Anthropic()
response = claude.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=300,
messages=[{"role": "user", "content": user_text}]
)
answer = response.content[0].text
# 3. Синтез речи
openai_client = OpenAI()
audio = openai_client.audio.speech.create(
model="tts-1", voice="nova", input=answer
)
audio.stream_to_file("response.mp3")Применение в бизнесе
Транскрибация встреч. Whisper + LLM для суммаризации: запись совещания превращается в протокол с задачами и дедлайнами. Компании вроде Otter.ai и Fireflies.ai построили на этом целый продукт — но с Whisper и LLM можно собрать аналог за вечер.
Транскрибация звонков и аналитика колл-центров. Whisper транскрибирует записи звонков, а LLM анализирует тональность, выделяет проблемные обращения и формирует отчёты. На практике это работает так: запись из АТС попадает в пайплайн, faster-whisper обрабатывает её за секунды, затем GPT или Claude классифицирует обращение и извлекает ключевые сущности — номера заказов, жалобы, запросы на возврат. Крупные колл-центры обрабатывают десятки тысяч записей в сутки — ручной анализ невозможен, а автоматический окупается за недели.
Контент. Подкасты озвучиваются синтетическим голосом. Статьи превращаются в аудиоформат. Видеоконтент получает закадровый голос на десятках языков.
Поддержка клиентов. Голосовые боты на основе LLM + TTS обрабатывают типовые обращения. Стоимость — кратно ниже живого оператора при круглосуточной доступности.
Доступность. Синтез речи для людей с нарушениями зрения. Транскрибация для людей с нарушениями слуха. Голосовое управление для людей с ограниченной подвижностью.
Этические вопросы
Клонирование голоса поднимает серьёзные вопросы. Deepfake-аудио — подделка голоса политика, руководителя, родственника — уже используется в мошеннических схемах. ElevenLabs и другие провайдеры внедряют меры защиты: верификация личности при клонировании, watermarking синтетического аудио, детекторы искусственной речи. Но технология опережает защитные механизмы, и ответственное использование остаётся на стороне пользователей.
Модели Whisper: характеристики
| Модель | Параметры | VRAM | Скорость (CPU) | WER (RU) |
|---|---|---|---|---|
| tiny | 39M | ~1GB | ~32x realtime | ~15% |
| base | 74M | ~1GB | ~16x realtime | ~10% |
| small | 244M | ~2GB | ~6x realtime | ~7% |
| medium | 769M | ~5GB | ~2x realtime | ~6% |
| large-v3 | 1550M | ~10GB | ~1x realtime | ~5% |
| turbo (large-v3-turbo) | 809M | ~6GB | ~8x realtime | ~5% |
Какую модель Whisper выбрать под задачу
Выбор модели зависит от трёх факторов: требуемая точность, доступное железо и допустимая задержка.
tiny и base — подходят для быстрого поиска по аудиоархиву, индексации подкастов и предварительной фильтрации. Ошибки будут, но скорость компенсирует: base обрабатывает час записи за 4 минуты на CPU. Если текст нужен не для публикации, а для внутреннего поиска — этого достаточно.
small — оптимальный выбор для разработчиков на ноутбуке. 2 ГБ VRAM, 7% WER на русском — для большинства задач хватает. Работает на MacBook с M1/M2 без проблем.
medium — production-вариант, когда есть GPU. Заметно лучше на шумных записях, акцентах и быстрой речи. Если транскрибируете звонки или интервью — берите medium.
large-v3 — максимальная точность. Для медицинских, юридических и академических задач, где каждое слово имеет значение. 10 ГБ VRAM, но зато WER около 5% на русском.
turbo (large-v3-turbo) — компромисс: точность large-v3 при скорости в 8 раз быстрее на CPU. OpenAI сократила количество декодер-слоёв с 32 до 4 (по аналогии с Distil-Whisper), сохранив качество распознавания. Для production-пайплайнов — лучший выбор по соотношению скорость/качество на начало 2026 года.
faster-whisper: ускорение в 4 раза
faster-whisper — оптимизированная реализация Whisper на CTranslate2 с INT8 квантизацией. Скорость в 2–4 раза выше оригинала при том же качестве. Рекомендуется для production: меньше VRAM, быстрее, поддерживает батчевую обработку.
Установка и запуск:
pip install faster-whisperfrom faster_whisper import WhisperModel
# INT8 квантизация — вдвое меньше VRAM, скорость выше
model = WhisperModel("large-v3", device="cuda", compute_type="int8")
segments, info = model.transcribe("audio.mp3", language="ru", beam_size=5)
print(f"Язык: {info.language}, вероятность: {info.language_probability:.2f}")
for segment in segments:
print(f"[{segment.start:.1f}s → {segment.end:.1f}s] {segment.text}")Типы квантизации: float16 — стандартная точность на GPU, int8 — вдвое меньше памяти при минимальной потере качества, int8_float16 — комбинированный режим. Для CPU используйте int8 или auto.
На практике faster-whisper large-v3 с int8 транскрибирует час аудио за 2–4 минуты на RTX 3090 и за 8–12 минут на RTX 3060. Для сравнения: оригинальный Whisper large-v3 на той же RTX 3090 — 8–12 минут за час аудио.
TTS: синтез речи — сравнение решений
| Решение | Качество (RU) | Латентность | Self-hosted | Цена |
|---|---|---|---|---|
| ElevenLabs | ★★★★★ | ~200мс | Нет | $5+/мес |
| Яндекс SpeechKit | ★★★★★ | ~150мс | Нет | ~0.2 ₽/мин |
| OpenAI TTS | ★★★★☆ | ~300мс | Нет | $15/1M знаков |
| Silero TTS | ★★★★☆ | ~200мс (GPU) | Да | Бесплатно |
| Kokoro TTS | ★★★★☆ (EN) | ~100мс | Да | Бесплатно |
| Coqui TTS | ★★★☆☆ | ~500мс | Да | Бесплатно |
Silero TTS: лучший self-hosted для русского
Silero — российская open source TTS-модель с отличным качеством для русского языка. Доступна через PyTorch Hub, работает на CPU (~200мс для коротких фраз). Поддерживает несколько голосов, правильно обрабатывает русские аббревиатуры и числа.
import torch
import soundfile as sf
model, _ = torch.hub.load('snakers4/silero-models', 'silero_tts',
language='ru', speaker='v4_ru')
# Доступные голоса: aidar, baya, kseniya, xenia, eugene
# aidar — мужской, нейтральный; xenia — женский, чёткий
speakers = ['aidar', 'xenia', 'baya', 'eugene']
text = "Привет! Это пример синтеза речи на русском языке."
for speaker in speakers:
audio = model.apply_tts(text, speaker=speaker, sample_rate=24000)
sf.write(f"output_{speaker}.wav", audio.numpy(), 24000)
print(f"Сохранён: output_{speaker}.wav")Silero v4 поддерживает ударения через знак + перед ударной гласной: замо+к (дверной) vs за+мок (крепость). Это критически важно для русского языка, где смена ударения меняет смысл слова.
Интеграция Whisper + Silero для полного офлайн-стека
Whisper large-v3 (ASR) + Silero v4 (TTS) дают полноценный голосовой интерфейс без облака. Производительность на M2 MacBook Pro (16GB): Whisper medium ~3x realtime, Silero TTS ~150мс для фразы. Общая латентность голосового пайплайна — 2–3 секунды. Оптимально для корпоративных решений с требованиями к конфиденциальности.
Генерация субтитров с Whisper
Одна из самых частых задач — автоматические субтитры для видео. Whisper отдаёт временные метки для каждого сегмента, и из них легко собрать SRT-файл:
from faster_whisper import WhisperModel
model = WhisperModel("medium", device="cuda", compute_type="int8")
segments, _ = model.transcribe("video.mp4", language="ru", word_timestamps=True)
with open("subtitles.srt", "w", encoding="utf-8") as f:
for i, seg in enumerate(segments, 1):
start = f"{int(seg.start//3600):02d}:{int(seg.start%3600//60):02d}:{seg.start%60:06.3f}".replace(".", ",")
end = f"{int(seg.end//3600):02d}:{int(seg.end%3600//60):02d}:{seg.end%60:06.3f}".replace(".", ",")
f.write(f"{i}\n{start} --> {end}\n{seg.text.strip()}\n\n")Для YouTube и социальных сетей формат SRT принимается напрямую. Для профессионального видеомонтажа субтитры импортируются в Premiere Pro, DaVinci Resolve или CapCut. При использовании word_timestamps=True можно получить пословную разбивку — это нужно для анимированных субтитров в TikTok и Reels.
Качество автоматических субтитров от Whisper на чистых записях сопоставимо с ручной работой. На зашумлённых записях (конференции, уличный шум) ошибки растут — в таких случаях стоит использовать модель large-v3 и постобработку текста через LLM.
Читайте также
- Как создать голосового ассистента с Whisper и GPT
- ElevenLabs vs Play.ht: синтез речи
- Мультимодальные модели ИИ
Подробнее: Лучшие ИИ-инструменты 2026 года