безопасность xAI, Grok и национальная безопасность: DOJ вступился за турбины дата-центра Маска DOJ вступился за xAI в иске NAACP о газовых турбинах Colossus 2. В центре спора: Grok, Clean Air Act, военное применение ИИ и энергоснабжение дата-центров.
безопасность LiteLLM CVE: как пользователь захватывает AI-шлюз Три LiteLLM CVE дают пользователю с низкими правами путь к proxy_admin и RCE. Разбираем риск для LLM-шлюза, ключей, callbacks и AI-агентов.
LLM Gemma 3 на спутнике YAM-9: VLM на орбите Gemma 3 запустили на спутнике YAM-9 через NAVI-Orbital. Разбираем, почему VLM на орбите важен для спутниковых сенсоров и edge AI.
Anthropic Суверенный ИИ: почему кейс Anthropic стал сигналом для Индии Кейс Anthropic показал Индии, что доступ к frontier-модели не равен контролю над ней. Разбираем, зачем нужен суверенный ИИ и где помогают open-source модели.
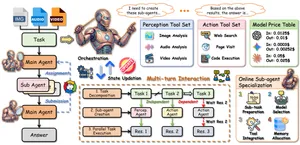
AI-агенты Orchestra-o1: arXiv-препринт об omnimodal AI-агентах Orchestra-o1 обещает оркестрацию для omnimodal AI-агентов. Главное — отделить заявления авторов и snapshot OmniGAIA от доказанного качества в реальных системах.
LLM Kimi K2.7 Code: открытые веса против закрытых coding-моделей Kimi K2.7 Code делает ставку на цену, открытые веса и самостоятельный запуск. Fable/Mythos здесь важны только как контраст риска закрытых API.
LLM Elias Thorne LLM: почему нейросети пишут один сюжет Разбираем, почему Elias Thorne стал повторяющимся персонажем LLM, что показало исследование на 20 000 историях и как проверять разнообразие генераций.