LLM Elias Thorne LLM: почему нейросети пишут один сюжет Разбираем, почему Elias Thorne стал повторяющимся персонажем LLM, что показало исследование на 20 000 историях и как проверять разнообразие генераций.
Anthropic Anthropic рискует стать платформой, которая конкурирует со своими клиентами Разбираем, почему запуск Claude Fable 5 превратил Anthropic в пример платформенного риска для клиентов, партнёров и AI-стартапов.
Google Google AI Overviews и ответственность: что решил суд Немецкий суд решил, что ложные ответы Google AI Overviews могут быть собственными утверждениями Google. Разбираем, почему это важно для ИИ-поиска.
безопасность AI Security Institute Германии: зачем Берлину свой AISI Германия создаёт AI Security Institute по модели UK AISI. Разбираем, что должен делать DE-AISI, где связь с AI Act и почему всё упрётся в доступ к frontier-моделям.
OpenAI Третья фаза OpenAI: AGI для всех и AI researcher OpenAI описала третью фазу компании: AI researcher, персональный AGI и доступный advanced AI. Разбираем, почему рядом важны Microsoft Lens и AI sovereignty.
DeepSeek DeepSeek в расходах компаний США: что показал Ramp Ramp увидел прямые платежи американских компаний DeepSeek. Разбираем, почему дешёвая LLM теперь конкурирует с enterprise-безопасностью.
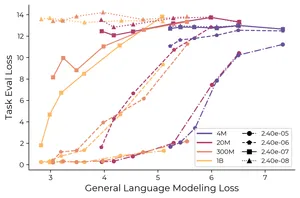
LLM Редкие навыки LLM: почему большие модели не забывают то, что малые теряют Работа Anthropic, Stanford и партнёров показывает, почему редкие навыки LLM теряются в малых моделях и как частота задачи в обучающей смеси может быть важнее грубого роста данных.