Редкие навыки LLM: почему большие модели не забывают то, что малые теряют
Работа Anthropic, Stanford и партнёров показывает, почему редкие навыки LLM теряются в малых моделях и как частота задачи в обучающей смеси может быть важнее грубого роста данных.
Проверено 7 июня 2026 года. Редкие навыки LLM — это задачи или правила, которые встречаются в обучающей смеси настолько редко, что модель должна удерживать слабый сигнал между разнесёнными примерами. Новая работа исследователей из Goodfire, Stanford University, Kempner Institute at Harvard University, MIT и Anthropic объясняет, почему крупные модели справляются с этим лучше: частые задачи меньше затирают редкий сигнал, и модель успевает накопить его до обобщения.
Практический вывод не сводится к «берите модель побольше». Авторы показывают более полезную механику: иногда целевой навык можно закрепить повышением его частоты в обучающей смеси. Такой приём не закрывает весь разговор о масштабе, зато хорошо спорит со слепым подходом «добавим ещё токенов и подождём».
Что именно нашли исследователи
Работа Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention появилась на arXiv 28 мая 2026 года, последняя версия вышла 1 июня. 7 июня её разобрал The Decoder. В центре статьи — не общий спор о том, «почему большие языковые модели умнее», а узкая причина: как модель распределяет ограниченные параметры между частыми, простыми, редкими и сложными задачами.
Авторы сначала строят синтетическую постановку с набором задач разной частоты и сложности. В такой смеси малая модель охотнее тратит параметры на частые или простые признаки. Редкая задача может быть выразима в архитектуре, но всё равно не закрепиться: она слишком редко появляется, чтобы выдержать конкуренцию с регулярными обновлениями от основной массы данных.
Если отвечать коротко: большие LLM лучше удерживают редкие навыки, потому что после освоения частых задач их градиентные обновления меньше мешают редким признакам. Модель может не начинать заново при каждом редком примере, а накапливать слабый сигнал между появлениями задачи.
Почему малая модель учит и тут же забывает
В статье это называют update-and-forget loop: модель получает редкий пример, немного двигается в правильную сторону, а затем следующие батчи с частыми задачами откатывают этот сдвиг. Когда похожий редкий пример встречается снова, обучение почти начинается с нуля.
У большой модели конкуренция мягче. Частые задачи быстрее занимают свои устойчивые представления, а их последующие обновления становятся слабее. За счёт этого редкий признак не выбивается из параметров сразу после появления. В терминах статьи, масштаб снижает градиентную интерференцию: обновления от общей языковой задачи меньше конфликтуют с направлением, нужным для редкого навыка.
| Механика | Малая модель | Большая модель | Что делать с датасетом |
|---|---|---|---|
| Частые задачи | Забирают большую часть параметров | Быстрее стабилизируются | Не мерить качество только общим loss |
| Редкие задачи | Сигнал легко стирается | Сигнал дольше держится между примерами | Проверять удержание навыка, а не только первое попадание |
| Повышение частоты | Может быть дешевле роста модели, но не гарантирует успех | Помогает быстрее накопить правило | Аккуратно увеличивать долю целевой задачи и смотреть на обобщение |

Что показали эксперименты на OLMo
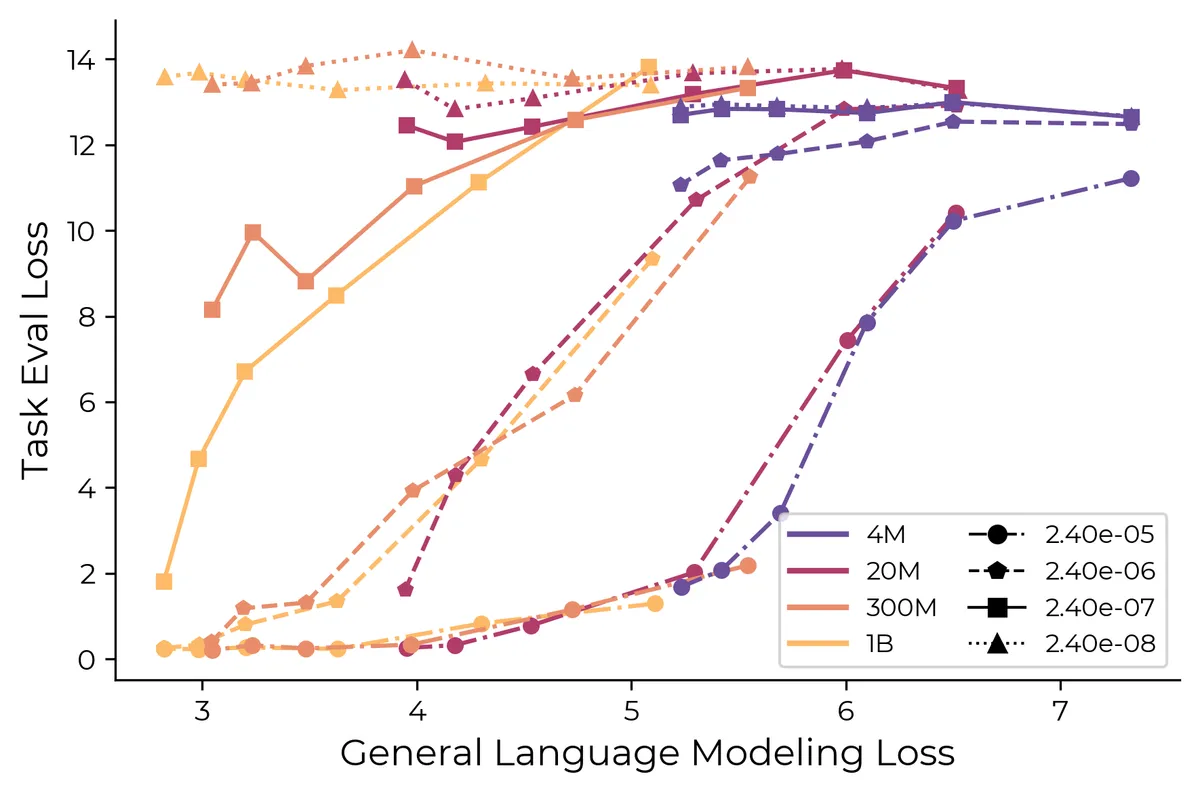
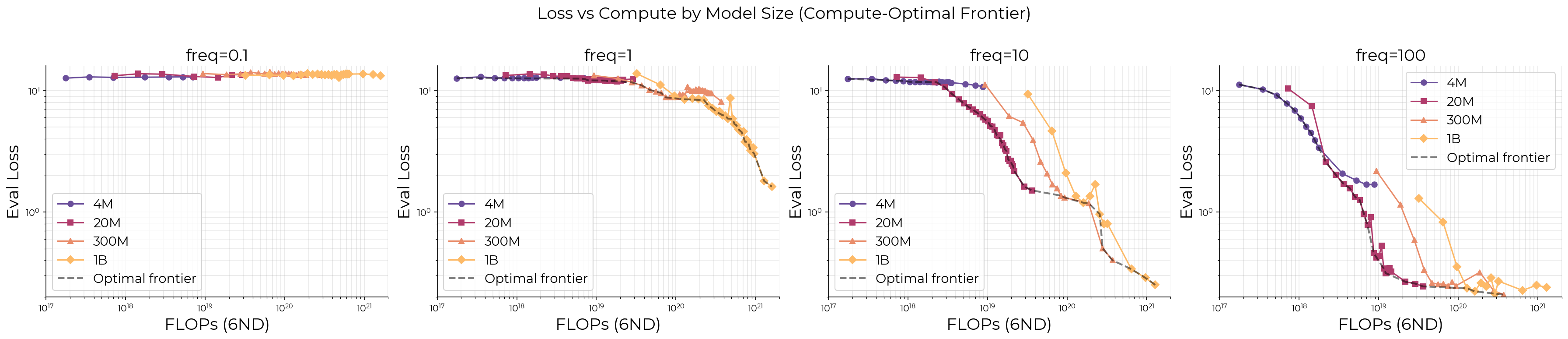
Чтобы проверить механизм не только на игрушечной постановке, авторы обучали модели семейства OLMo размером 4M, 20M, 300M, 1B и 4B параметров. Корпус — Dolma v1.7, объём обучения — до 210 млрд токенов, примерно 50 тыс. шагов. В данные добавляли две искусственные задачи: сравнение чисел и модульное сложение.
Частоту этих задач контролировали жёстко: от 7,8 × 10-3 до 2,4 × 10-8 на токен. В пересчёте авторов это диапазон примерно от тысячи примеров на батч до одного примера на десять батчей. У каждой искусственной задачи было 10 тыс. экземпляров, разделённых поровну на обучение и тест. Такой дизайн нужен, чтобы отличить запоминание отдельных примеров от настоящего обобщения правила.
Результат совпал с теорией. Крупные OLMo-модели лучше учили низкочастотные задачи и чаще доходили до обобщения. На модульном сложении авторы наблюдали grokking: сначала модель запоминает примеры, а позднее резко начинает применять правило. Но этот переход появлялся только у больших моделей и только тогда, когда задача встречалась достаточно часто.
Чем это отличается от fine-tuning
Здесь легко сделать неправильный вывод: будто исследование просто говорит «добавьте больше примеров нужного класса». На самом деле речь о pre-training-смеси и о том, как редкий навык выживает среди огромного потока других обновлений. Это рядом с темой fine-tuning языковых моделей, но не то же самое. Дообучение обычно происходит уже после базового обучения и решает задачу адаптации; работа Huang et al. разбирает, почему часть навыков вообще не закрепляется в базе.
Для команд, которые обучают или дообучают модели под редкие корпоративные сценарии, важен не только объём данных. Нужны отдельные проверки на удержание: модель должна сохранять навык после длинного промежутка обычных задач. Иначе можно увидеть красивый результат сразу после примеров целевого класса, а затем потерять его в реальном потоке.
Где малые модели остаются полезны
Исследование не доказывает, что малые модели бесполезны. Наоборот, оно помогает точнее говорить, где их граница. Малые специализированные модели по-прежнему могут быть выгодны по цене, задержке и контролю, особенно если задача частая и узкая. Мы уже разбирали это на примере материала про малые модели против frontier API.
Но если нужный навык редкий, сложный и должен обобщаться за пределы виденных примеров, одной экономии может быть мало. В таком случае стоит проверять не только среднюю точность, но и хвост распределения: какие задачи модель видит редко, что она с ними делает через тысячи обычных запросов и не появляется ли тот самый цикл «выучила — забыла».
Контекст Anthropic здесь тоже важен. Компания много говорит о pre-training как о стратегическом уровне качества модели; мы отдельно писали о том, почему ставка на pre-training Claude отличается от косметической настройки поведения. Новая работа добавляет к этому разговору конкретную механику: не все навыки одинаково переживают смесь данных.
Где границы исследования
Авторы аккуратно ограничивают выводы. OLMo-эксперименты проводились на специально добавленных задачах, а не на полном наборе естественных навыков production-моделей. В статье прямо сказано, что поведение более крупных или переобученных языковых моделей не проверялось. Частоты задач тоже выбраны так, чтобы соответствовать наблюдаемым задачам в OLMo pre-training, но это не покрывает все возможные режимы обучения.
Поэтому сильная формулировка такая: исследование даёт data-centric объяснение, почему масштаб помогает некоторым редким навыкам закрепляться. Оно не отменяет другие причины успеха больших моделей — выразительность, sample efficiency, архитектурные детали и качество корпуса. Но оно показывает, почему общий loss может скрывать важную проблему: модель улучшается в среднем и всё равно теряет хвостовые навыки.
Короткий вывод
Редкие навыки LLM стоит оценивать отдельно. Если задача появляется редко, малая модель может не «не понимать» её в принципе, а постоянно терять слабый сигнал между появлениями. Большая модель выигрывает не магией масштаба, а меньшей интерференцией: частые задачи перестают так сильно стирать редкие признаки.
Для исследователей это аргумент внимательнее проектировать смеси данных. Для продуктовых команд — повод тестировать удержание редких сценариев, особенно если модель должна работать с длинным хвостом запросов. Иногда правильный вопрос не «насколько модель большая», а «достаточно ли часто она видит навык, который мы от неё ждём».
Читайте также
- Fine-tuning LLM: когда дообучение оправдано и как выбрать метод
- Специализированные малые модели против frontier API: что показал DharmaOCR
- Андрей Карпатый в Anthropic: ставка на pre-training Claude
Источники и проверка фактов
- Jing Huang et al. — Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention, arXiv:2605.29548v2, submitted 28 May 2026, revised 1 Jun 2026, проверено 7 июня 2026 года.
- Hugging Face Papers — карточка arXiv:2605.29548, проверено 7 июня 2026 года.
- The Decoder — Researchers pinpoint why larger language models pick up skills that small ones miss, опубликовано 7 июня 2026 года, проверено 7 июня 2026 года.