SOOHAK бенчмарк: почему LLM спотыкаются на задачах без ответа
Новый бенчмарк SOOHAK показывает: сильные LLM уже решают часть исследовательских задач, но плохо распознают некорректные условия.
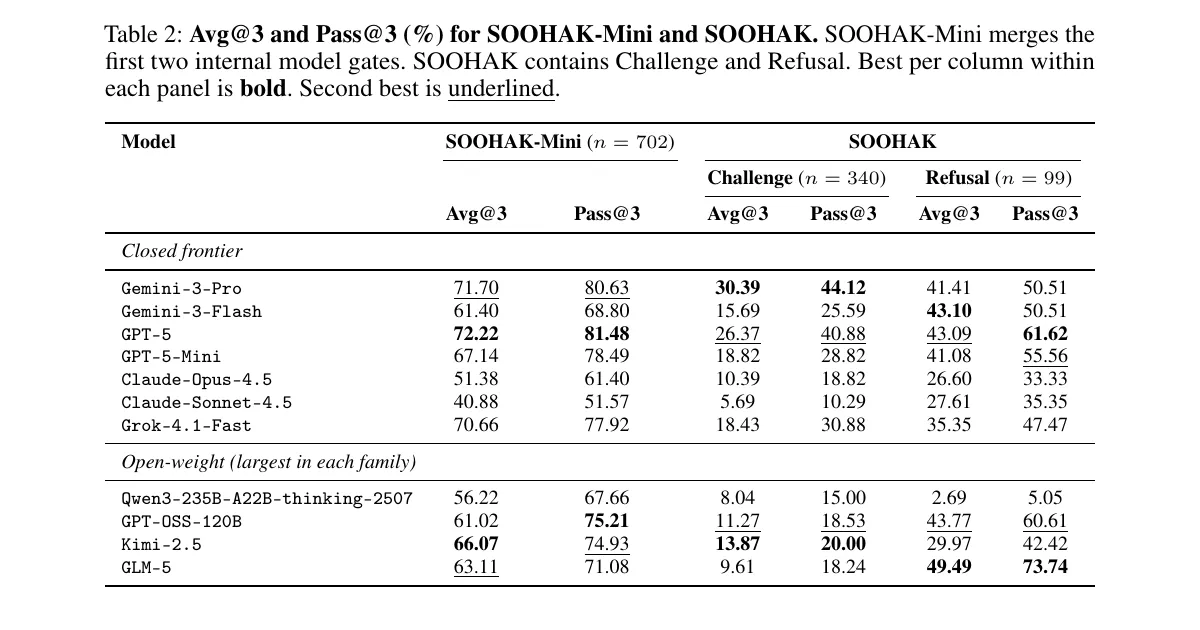
По состоянию на 26 мая 2026 года новый SOOHAK бенчмарк выглядит как более жёсткая проверка для LLM после волны задач уровня олимпиадной математики. Его авторы собрали 439 заданий, написанных с нуля 64 математиками, и разделили их на две части: 340 задач Challenge и 99 задач Refusal, где условие некорректно или не даёт определённого ответа.
Главный результат неприятен для рынка моделей рассуждения. На Challenge лучшая модель, Gemini-3-Pro, набрала 30,39% по Avg@3; GPT-5 — 26,37%; Claude-Opus-4.5 — 10,39%. Но самый полезный сигнал даёт Refusal: по Avg@3 ни одна модель не дошла до 50%, то есть системы всё ещё плохо распознают момент, когда задачу надо остановить, а не уверенно доводить до ответа.
Это хороший контраст к общей истории про модели рассуждения. За последний год LLM стали заметно сильнее в задачах, где нужно долго считать, проверять шаги и держать план. SOOHAK проверяет другой слой: умеет ли модель работать с новой исследовательской задачей и признавать, что в условии есть ошибка.
Что такое SOOHAK
SOOHAK — исследовательский математический бенчмарк из работы Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs. Первая версия препринта появилась на arXiv 9 мая 2026 года, третья версия — 19 мая. Полный датасет авторы обещают открыть в конце 2026 года, чтобы снизить риск попадания задач в обучение моделей; до этого они предлагают оценки по запросу.
Авторы прямо объясняют, почему им понадобился новый набор. Олимпиадные задачи хорошо проверяют пошаговое решение, но исследовательская математика устроена иначе: там больше неопределённости, меньше шаблонов и чаще нужно заметить, что вопрос сформулирован плохо. Поэтому SOOHAK не пытается заменить AIME, IMO или другие привычные тесты. Он закрывает другой участок карты.
Состав бенчмарка тоже важен. Challenge содержит задачи уровня магистратуры, аспирантуры и близкой к исследовательской математике. Refusal собран из заданий, которые не прошли контроль качества, потому что в них есть противоречие, отсутствующее допущение или другой дефект. Модель получает балл только тогда, когда находит проблему в условии и объясняет, почему корректного ответа нет.
Почему олимпиадных задач уже мало
Олимпиадная математика остаётся сильным тестом, но она поощряет короткий путь к решению. Именно поэтому успешный результат на таких задачах не всегда означает, что модель готова к исследовательской работе. В SOOHAK есть задачи с длинным хвостом тем: алгебра, теория чисел, комбинаторика, анализ, геометрия, топология и смежные области.
У SOOHAK есть понятное ограничение: многие задания требуют чистого финального ответа, а не полного доказательства, построения или контрпримера. Авторы сами признают, что для части высшей математики лучше подошли бы формальные доказательства, экспертная проверка или системы проверки доказательств. Но даже в таком формате SOOHAK показывает, где заканчивается привычный прогресс на задачах с известным типом решения.
На этом фоне отдельные победы LLM в математике стоит читать осторожно. У Toolarium уже был материал о том, как ChatGPT помог решить 60-летнюю задачу Эрдеша. Такие кейсы важны, но они не доказывают широкую исследовательскую автономность. SOOHAK полезен именно как массовая проверка: не один красивый пример, а сотни задач, где модель должна работать без опоры на публичную историю решения.
Какие модели показали лучший результат
В основной таблице авторы используют две метрики: Avg@3 и Pass@3. Avg@3 усредняет три независимых ответа модели на каждую задачу. Pass@3 засчитывает задачу, если хотя бы один из трёх ответов оказался правильным. Поэтому цифры Pass@3 выше и их нельзя смешивать с тезисом про «ни одна модель не выше 50%» на Refusal: это утверждение относится к Avg@3.
На SOOHAK Challenge лидирует Gemini-3-Pro: 30,39% Avg@3 и 44,12% Pass@3. GPT-5 идёт следом с 26,37% Avg@3 и 40,88% Pass@3. У Claude-Opus-4.5 результат заметно ниже — 10,39% Avg@3 и 18,82% Pass@3. Среди моделей с открытыми весами сильнее всех выглядит Kimi-2.5: 13,87% Avg@3 на Challenge.
На Refusal картина меняется. GLM-5 получает лучший Avg@3 — 49,49%, хотя на Challenge он набирает только 9,61%. GPT-5 показывает 43,09% Avg@3 на Refusal, Gemini-3-Pro — 41,41%. Иными словами, способность решать сложные задачи и способность остановиться на некорректной задаче пока не идут вместе.
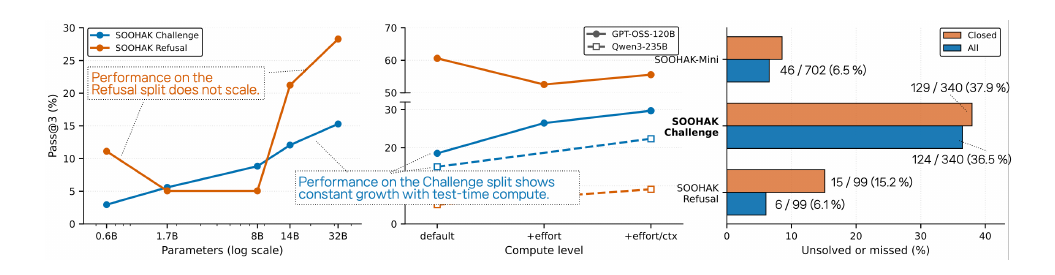
Почему Refusal важнее красивых процентов
Для обычного пользователя ошибка в математике часто выглядит как неверное число. Для исследователя хуже другая ситуация: модель уверенно строит решение там, где задача не имеет корректного ответа. Refusal как раз ловит этот тип сбоя. Если модель не видит противоречие в условии, она может написать аккуратный, длинный и полностью бесполезный вывод.
Именно поэтому SOOHAK хорошо рифмуется с нашим разбором ARC-AGI-3 и системных ошибок frontier-моделей. В обоих случаях проблема не сводится к нехватке знаний. Система может долго рассуждать, но плохо проверять собственные предпосылки. В математике это особенно заметно: ложное допущение в начале превращает все последующие рассуждения в красивую декорацию.
Авторы SOOHAK пишут, что Refusal становится новой целью оптимизации. По их данным, Challenge растёт вместе с размером модели и тестовым вычислительным бюджетом. Refusal так же чисто не масштабируется. Больше токенов и более крупная модель помогают дольше решать, но не гарантируют дисциплину отказа.
Проверка на людях тоже не идеальна
В работе есть отдельная проверка на людях: 25 участников в пяти командах решали набор из 79 задач. Совокупное покрытие всех человеческих команд составило 50,6%; Gemini-3-Pro на том же наборе набрала 60,8%. Но эту цифру нельзя читать как простое «модель сильнее математиков».
Авторы подчёркивают, что людям дали ограничение в 4,5 часа, а команды отличались профилем: от студентов с олимпиадным опытом до PhD-исследователей. Лучшей человеческой группой оказались не узкие исследователи, а математики с сильным IMO-бэкграундом. Это говорит о формате теста: он всё ещё во многом награждает соревнование и скорость, а не только глубокую специализацию.
Для читателя это важная поправка. SOOHAK не даёт окончательный ответ на вопрос, умеют ли LLM делать новую математику. Он показывает более узкую, но полезную вещь: даже сильные модели пока плохо проходят загрязнённый неопределённостью тест, где нужно не только решать, но и отказываться от неправильной постановки.
Что это меняет для оценки LLM
SOOHAK бенчмарк стоит читать как предупреждение против одного удобного заблуждения: если модель стала лучше на олимпиадных задачах, значит она автоматически стала лучше в исследовательском рассуждении. На практике между этими режимами большой зазор. В первом случае задача обычно корректна и имеет элегантный путь. Во втором нужно разбираться с новой постановкой, неполным контекстом и возможной ошибкой в самом вопросе.
Для разработчиков это меняет дизайн проверок. Недостаточно гонять модель только на задачах с правильным ответом. Нужны наборы, где часть запросов должна заканчиваться отказом, уточнением или указанием на дефект условия. Иначе мы оптимизируем модели на производство уверенных решений, но не учим их останавливаться.
Для продуктовых команд вывод ещё проще: в сценариях с высокой ценой ошибки надо тестировать не только способность дать ответ, но и способность не отвечать. В математике это выглядит как Refusal. В инженерии, медицине, финансах и безопасности у этого навыка будут другие названия, но смысл тот же: сильная модель должна уметь сказать, что задача сломана.
Главное
SOOHAK не доказывает, что LLM бесполезны в математике. Он показывает, что после олимпиадного прогресса следующий рубеж сложнее: исследовательские задачи требуют не только длинного рассуждения, но и проверки постановки. Gemini-3-Pro и GPT-5 уже решают заметную часть Challenge, но на Refusal даже лучшие системы по Avg@3 остаются ниже 50%.
Именно этот разрыв делает SOOHAK важным инфоповодом. Рынок привык смотреть на проценты прохождения. Новый бенчмарк напоминает: в сложных задачах умение остановиться иногда важнее, чем умение продолжать.
Читайте также
- Модели рассуждения: o3, DeepSeek-R1 и новая парадигма
- ChatGPT помог решить 60-летнюю задачу Эрдеша
- ARC-AGI-3 показал три системные ошибки frontier-моделей
Источники и проверка фактов
- arXiv: Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs, v1 от 9 мая 2026 года, v3 от 19 мая 2026 года, проверено 26 мая 2026 года.
- The Decoder: New math benchmark reveals AI models confidently solve problems that have no solution, опубликовано 17 мая 2026 года, проверено 26 мая 2026 года.
- Hugging Face Papers: arXiv:2605.09063, проверено 26 мая 2026 года.



