Shopify входит в AI-first режим и перестраивает инженерную организацию
Shopify превращает AI из набора инструментов в модель инженерной работы: общий шлюз к моделям, Tangle, SimGym и новый bottleneck в review и CI/CD.

Shopify еще весной 2025 года закрепила «рефлекторное использование ИИ» как базовое ожидание для сотрудников. По состоянию на 26 апреля 2026 года видно, что история давно вышла за рамки громкого меморандума Тоби Лютке. Публичные материалы Shopify, разбор Bessemer Venture Partners и интервью CTO Михаила Парахина показывают более глубокий сдвиг: компания перестраивает не только повседневную разработку, но и сам инженерный контур вокруг AI-first режима.
Официальная статья Shopify News от 28 октября 2025 года фиксирует универсальное использование ИИ-редакторов кода, тысячи лицензий Cursor и безлимитный доступ команд к топовым моделям. В материале BVP от 2 апреля 2026 года руководитель инженерного направления Фархан Тавар оценивает эффект примерно в 20% роста продуктивности. А интервью Latent Space от 22 апреля 2026 года добавляет следующий слой: главным ограничением становится уже не генерация кода, а ревью, CI/CD и стабильность выката.
В этом и состоит отличие кейса Shopify от общего разговора про «агентов для разработчиков». Мы уже разбирали AI-first разработку на примере Zencoder и Stripe, где фокус был на ускорении выпуска. Здесь акцент другой. Shopify строит модель работы, в которой ИИ становится частью инфраструктуры, внутренних сервисов и системы экспериментов, а не просто еще одним помощником в редакторе.
Что у Shopify уже подтверждено публично
По состоянию на 26 апреля 2026 года открытые источники дают уже не набор цитат из X, а вполне связную техническую картину.
| Сигнал | Что подтверждено | Источник |
|---|---|---|
| Поворот к AI-first | Shopify официально пишет, что в апреле 2025 года Тоби Лютке зафиксировал «reflexive AI usage» как базовое ожидание для компании. | Shopify News, 28 октября 2025 года |
| Масштаб внедрения | Компания говорит об универсальном использовании ИИ-редакторов кода, тысячах лицензий Cursor и безлимитном доступе каждой команды к топовым моделям. | Shopify News, 28 октября 2025 года |
| Инфраструктурный слой | BVP описывает централизованный LLM-proxy, MCP-серверы, внутреннюю библиотеку рабочих промптов, AI-reflexive оценки и небольшую ML-инфраструктурную команду примерно из шести инженеров. | BVP Atlas, 2 апреля 2026 года |
| Платформы экспериментов | Tangle описан как open-source платформа для воспроизводимых ML- и data-pipeline. SimGym запускает simulated A/B tests с сотнями ИИ-покупателей и до 2 000 одновременных Chromium-сессий. | Shopify Engineering, 2025-2026 |
| Новый bottleneck | По словам CTO Михаила Парахина, после скачка качества моделей в декабре генерация кода перестала быть главным ограничением. Теперь все упирается в review, CI/CD и стабильность выката. | Latent Space, 22 апреля 2026 года |
Shopify стандартизирует не инструмент, а слой под ним
Самая взрослая часть этой истории не в том, что Shopify раздает сотрудникам новые модели. Куда важнее другой выбор: компания не пытается насадить один IDE-помощник, а строит общий слой, через который проходят AI-запросы. В разборе BVP это названо централизованным LLM-proxy. Через него идут запросы от Claude Code, GitHub Copilot и других инструментов, а сама Shopify сохраняет контроль над расходами, аналитикой использования и возможностью быстро менять модели под капотом.
Для крупной инженерной организации это намного важнее, чем еще одна лицензия. Когда у вас сотни или тысячи сотрудников работают с разными моделями, главная проблема уже не в покупке доступа. Главная проблема в маршрутизации, правах, надежности, задержке и повторяемости процесса. Shopify решает ее как платформенную задачу, а не как набор локальных лайфхаков отдельных команд.
Следующий слой, который всплывает в BVP, это доступ ИИ к внутреннему контексту через MCP-серверы. Shopify подводит инструменты к wiki, продуктовым системам, GSD и хранилищам данных, но не отменяет обычные права доступа. Агент не должен видеть то, чего не видит сам сотрудник. Это делает ИИ полезнее и одновременно не ломает базовую модель безопасности.
Есть и организационная часть. BVP пишет, что сотрудников оценивают по тому, насколько они AI-reflexive, то есть насколько быстро по умолчанию тянутся к ИИ, когда сталкиваются с задачей. Формулировка может раздражать, но как управленческий сигнал она предельно ясна: AI-first в Shopify встроен в регулярную оценку сотрудников, а не живет только в красивых презентациях.
Еще одна деталь особенно показательна. По словам Тавара, всю эту внутреннюю поддержку держит небольшая ML-инфраструктурная команда примерно из шести инженеров. Shopify не строит вокруг ИИ отдельную тяжелую бюрократию. Она строит компактный внутренний слой, который снимает трение для остальных.
Узкое место сместилось в review, CI/CD и выкаты
Интервью Михаила Парахина Latent Space ценно не громким заголовком, а тем, что оно честно называет следующую проблему. Когда модели становятся достаточно хорошими, вы больше не боретесь за каждую строку сгенерированного кода. Вы боретесь с последствиями: лавиной pull request, флейками в тестах, задержками CI и ростом риска продакшн-багов.
Парахин говорит об этом прямо. В Shopify стало намного больше кода, а вместе с ним выросла вероятность, что хотя бы часть тестов упадет, придется искать проблемный PR, выкидывать его из очереди и гонять все заново. В итоге цикл выката удлиняется. Его логика проста: иногда выгоднее потратить больше времени на более «думающую» модель в начале, чем потом расплачиваться за это на этапе тестирования и отката.
Это важный холодный душ для индустрии. Внешне AI-first часто продают как историю про кратный рост выпуска. Но кейс Shopify показывает другую сторону: больше сгенерированного кода не делает инженерный процесс здоровее автоматически. Если агент ускоряет генерацию быстрее, чем команда ускоряет ревью и деплой, бутылочное горлышко просто переезжает дальше по конвейеру.
Этот тезис хорошо стыкуется с нашим разбором OpenAI Codex как среды для агентного программирования. Рынок уходит от простого автодополнения к агентам, которые сами ходят по задачнику, терминалу, браузеру и репозиторию. Но чем самостоятельнее агент, тем дороже ошибка на последних этапах. Для Shopify это уже не теория, а часть ежедневной модели работы.
По тому же интервью видно, что компания уже использует стековые PR и Graphite. То есть проблема не в том, что Shopify «еще не дошла» до более продвинутых процессов. Проблема в том, что даже у продвинутой команды взаимодействие с кодовой базой и CI/CD остается главным ограничением, когда скорость генерации резко растет.
На этом фоне полезно держать рядом и наш материал про Stripe Minions и 1 300 PR в неделю. Stripe хорошо показывает масштаб автоматизации. Shopify, в свою очередь, публично проговаривает, что происходит после такого масштаба: ревью, тесты и выкаты становятся отдельной инженерной задачей.
Tangle и SimGym превращают эксперименты в фабрику
Если смотреть на конкретные инструменты, история становится еще интереснее. В конце 2025 года Shopify открыла Tangle, платформу с открытым кодом для воспроизводимых ML- и data-workflow. В официальном описании заявлены работа с любым языком, запуск в любом облаке или локальной инфраструктуре без модификации кода и content-based caching. Shopify отдельно приводит практический пример: десятичасовой pipeline можно сократить до двадцати минут, если по факту изменилась только одна часть графа.
Это уже не похоже на игрушку для хакатона. Tangle решает скучную, но важную проблему: как сделать эксперименты воспроизводимыми, дешевыми и коллективными. Если перевести это на обычный инженерный язык, Shopify вытаскивает исследовательскую работу из режима «у кого сохранился блокнот на ноутбуке» в режим общей платформы.

SimGym двигает ту же логику уже в симуляции покупателей. В инженерном материале Shopify от 27 февраля 2026 года система описана как simulated A/B testing with synthetic customers at scale. Для одного прогона запускаются сотни ИИ-покупателей, а под капотом работают до 2 000 одновременных Chromium-сессий. Идея проста: тестировать изменения storefront за минуты, а не ждать недели, пока классический A/B test накопит статистику.
Самое сильное место в этом тексте, пожалуй, экономика. Shopify пишет, что 94% всех токенов в SimGym приходятся на input. Компания также измерила, что снижение средней задержки LLM примерно на 20% сократило стоимость одного merchant run примерно на 10% и подняло дневной throughput примерно на 12%. Это уже разговор не про красивую демку, а про физику расходов и пропускной способности.
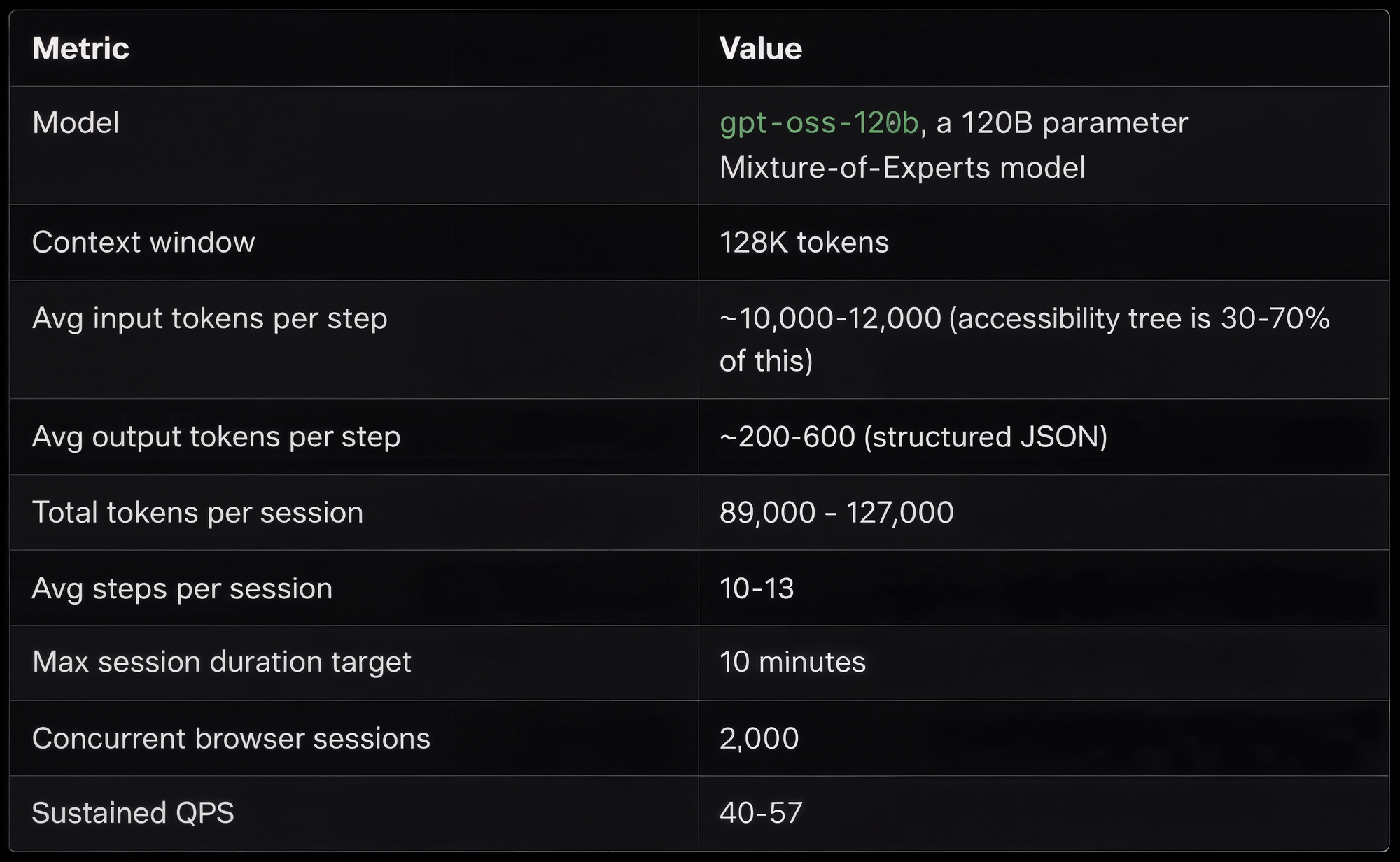
Именно здесь особенно хорошо видно, что Shopify строит не набор модных ИИ-функций, а фабрику экспериментов. Tangle делает воспроизводимыми внутренние исследовательские конвейеры. SimGym превращает проверку интерфейсных изменений в вычислимую задачу. А интервью Парахина добавляет к этому Tangent и более широкие циклы автооптимизации. Вместе это уже похоже на системную перестройку, а не на очередной период энтузиазма вокруг новых моделей.
Autoresearch показывает, как меняется сама инженерная культура
Пожалуй, самый живой публичный сигнал о том, как Shopify мыслит внутри, это статья Autoresearch isn’t just for training models от 15 апреля 2026 года. Формально она не про Tangent, но именно она показывает культурную почву, на которой такие инструменты вообще могут расти.
Инженер David Cortes пишет, что он вместе с Тоби Лютке обобщил подход Autoresearch для улучшения более чем 40 метрик внутри Shopify. В одном из примеров базовое время сборки Polaris составляло 19,1 секунды, а итоговое улучшение дало 65% ускорения. Дальше история становится почти слишком показательной: Тоби присылает 32-коммитный pull request в side project инженера, проект быстро уходит в open source, а внутренний канал #autoresearch-wins начинает собирать новые кейсы ускорения по всей компании.
Здесь важна не романтическая история про CEO, который снова пишет код. Важнее другое. Shopify отдает агентам не только рутинное производство функций, но и скучную работу по постоянному поиску улучшений. То есть AI-first здесь означает не только «быстрее писать код», но и «быстрее находить, что именно стоит улучшать».
С Tangent стоит быть аккуратнее. Публичной документации по этому внутреннему инструменту пока нет, и не нужно делать вид, будто мы знаем его устройство в деталях. Но Autoresearch хорошо подтверждает, что сама логика длинных циклов оптимизации внутри Shopify уже живая: агенту дают метрику, допускают серию гипотез и смотрят не на эффектный демо-ролик, а на измеримое изменение числа.
Что это значит для остальных engineering-команд
Главный вывод из кейса Shopify звучит довольно прозаично: копировать надо не memo, а последовательность слоев под memo. Лозунг «используйте AI по умолчанию» сам по себе ничего не дает, если под ним нет общего шлюза к моделям, нормальной системы прав доступа, дисциплины ревью, устойчивого контура тестирования и хотя бы базовой платформы для экспериментов.
Кейс Shopify полезен по трем причинам:
- Компания централизует AI-трафик через инфраструктурный слой, а не раздает инструменты наугад.
- Она встраивает ИИ в оценку сотрудников и внутренний контекст, а не оставляет его личной инициативой отдельных энтузиастов.
- Она инвестирует в платформы вроде Tangle и SimGym, где ИИ ускоряет не только кодинг, но и весь цикл эксперимента.
Для большинства компаний это одновременно плохая и хорошая новость. Плохая в том, что «просто купить всем Cursor» не превращает организацию в Shopify. Хорошая в том, что этот кейс наконец показывает, где лежит взрослая работа: в перестройке ревью, CI/CD, внутренних данных и циклов обратной связи, а не в охоте за очередным модным агентом.
Если коротко, Shopify входит в AI-first режим не как стартап с громким лозунгом, а как большая инженерная машина, которая переносит ИИ из категории «помощник разработчика» в категорию «часть производственного контура». Именно поэтому этот кейс стоит читать отдельно, а не как еще одну вариацию на тему общего роста продуктивности.
Источники и проверка фактов
- Shopify News: Serious results, unserious methods: Shopify’s AI playground, опубликовано 28 октября 2025 года, проверено 26 апреля 2026 года.
- Bessemer Venture Partners: Inside Shopify’s AI-first engineering playbook, опубликовано 2 апреля 2026 года, проверено 26 апреля 2026 года.
- Shopify Engineering: Tangle: An open-source ML experimentation platform built for scale, проверено 26 апреля 2026 года.
- Shopify Engineering: 2,000 robots walk into a shop: Simulated A/B testing, опубликовано 27 февраля 2026 года, проверено 26 апреля 2026 года.
- Shopify Engineering: Autoresearch isn’t just for training models, опубликовано 15 апреля 2026 года, проверено 26 апреля 2026 года.
- Latent Space: Shopify’s AI Phase Transition with Mikhail Parakhin, опубликовано 22 апреля 2026 года, проверено 26 апреля 2026 года.



