Google A2UI: интерфейсы для AI-агентов
Google A2UI v0.9 показывает, куда движутся AI-агенты: от текстового чата к управляемым интерфейсам из доверенных компонентов.

По состоянию на 19 апреля 2026 года Google A2UI выглядит как важный поворот в разговоре об AI-агентах. Компания предлагает агентам говорить с приложениями не только текстом, но и намерением интерфейса: какие элементы показать, как связать данные, где пользователь должен нажать, подтвердить или исправить результат.
Ключевой запрос этой статьи: Google A2UI. За термином generative UI стоит попытка отделить две вещи, которые в агентных продуктах часто смешивают: логику агента и доверенный интерфейс приложения. Агент предлагает структуру, но финальный вид, стили, компоненты и ограничения остаются на стороне приложения-хоста.
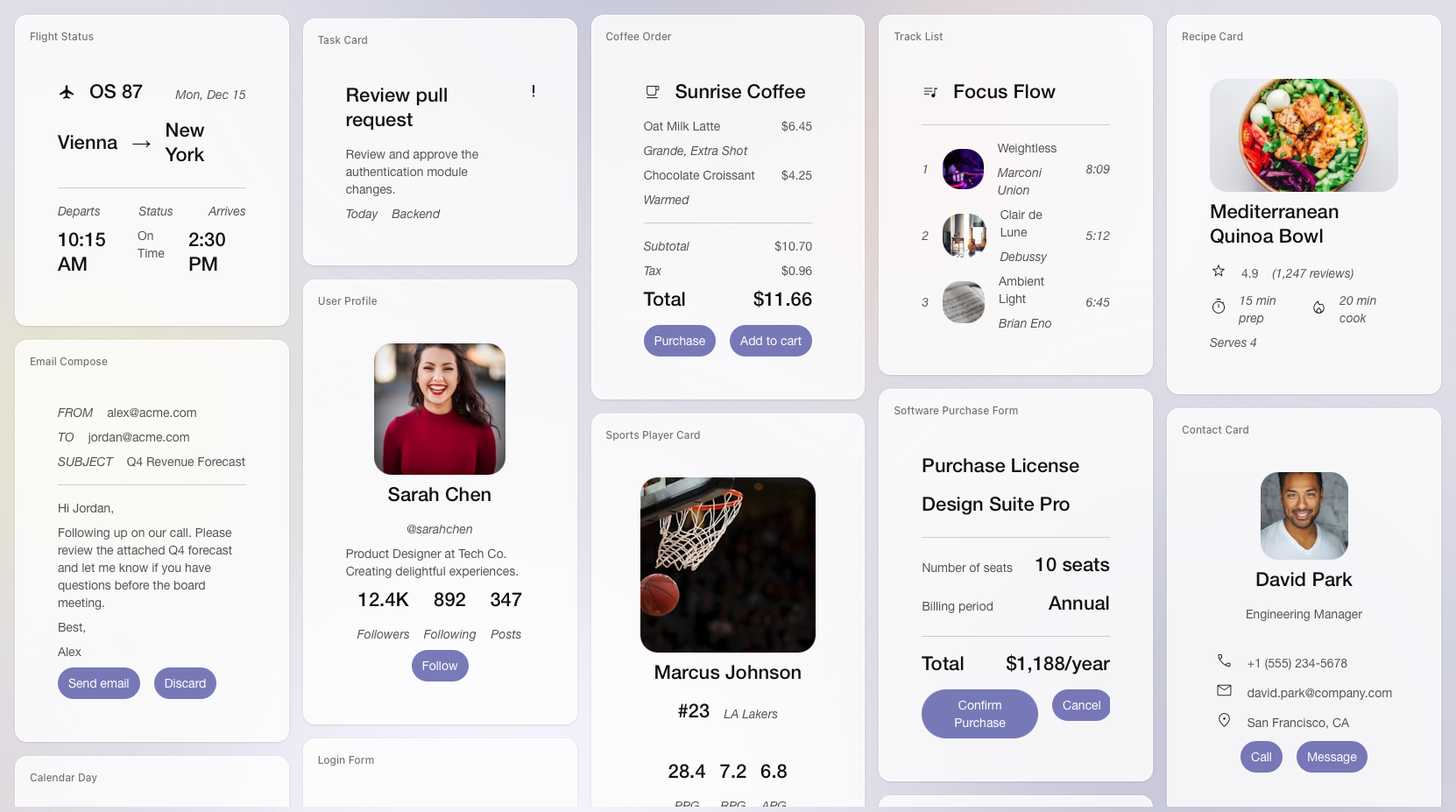
Что именно выпустила Google
17 апреля 2026 года команда Google A2UI объявила A2UI v0.9. В формулировке Google это независимый от фреймворка стандарт для объявления UI intent: агент может передать приложению описание нужного интерфейса, а клиентское приложение отрисует его через собственный каталог компонентов. Это важная разница с подходом «модель сгенерировала кусок HTML, а мы надеемся, что он безопасен».
В A2UI v0.9 Google выделяет несколько практических изменений. Появилась общая Web Core-библиотека для браузерных рендереров. В блоге Google сказано, что появился официальный React-рендерер, а поддерживаемые рендереры Flutter, Lit, Angular и React получили обновления. Для агентной стороны появился A2UI Agent SDK, который помогает формировать системные инструкции, выбирать каталог компонентов, проверять JSON и передавать результат потоком.
Отдельно Google подчёркивает транспортный слой: A2UI можно передавать поверх MCP, WebSockets, REST, AG-UI, A2A и других механизмов. Это не означает, что вся отрасль уже приняла A2UI как универсальный стандарт. Корректнее сказать иначе: Google выпустила версию 0.9 и расширяет вокруг неё набор интеграций, SDK и примеров.
Почему это не просто ещё один чат
Обычный чатовый агент хорошо отвечает на вопросы, но плохо работает там, где пользователь должен сделать выбор в интерфейсе. Пример из первого анонса A2UI простой: агент бронирует столик в ресторане. В текстовом режиме это цепочка уточнений: дата, время, количество гостей, подтверждение. В интерфейсном режиме агент может предложить форму с датой, временем, вариантами и кнопкой отправки.
Для разработчика важна не только скорость. В текстовом чате сложнее удержать контроль над тем, что пользователь видит и подтверждает. В A2UI агент не получает право самовольно рисовать любой интерфейс. Он работает с каталогом разрешённых компонентов: карточками, формами, списками, кнопками, графиками, полями ввода. Это ближе к договору между агентом и приложением, чем к свободной генерации страницы.
Если упростить, A2UI пытается сделать для агентного интерфейса то, что протоколы обмена сделали для серверов и клиентов: описать не конкретный внешний вид, а семантику взаимодействия. Агент говорит: «нужен выбор времени, подтверждение покупки, карточка контакта, список задач». Приложение решает, как это будет выглядеть в его дизайн-системе.
Из чего состоит A2UI v0.9
Быстро меняющиеся детали совместимости лучше проверять в документации перед внедрением. Но по официальному анонсу Google A2UI v0.9 уже можно понять, какие слои компания считает ключевыми.
| Слой | Что делает | Почему это важно |
|---|---|---|
| UI intent | Агент описывает нужный интерфейс через структуру компонентов, а не генерирует произвольную страницу. | Приложение-хост сохраняет контроль над стилем, доступностью и безопасностью. |
| Каталог компонентов | Разработчик задаёт, какие карточки, формы, кнопки и другие элементы доступны агенту. | Агент работает внутри границ существующей дизайн-системы. |
| Web Core и рендереры | Клиентские библиотеки разбирают A2UI-сообщения и отображают их через нативные компоненты. | Один агентный сценарий можно адаптировать под разные фронтенды. |
| Agent SDK | SDK помогает агенту выбирать каталог, строить инструкции, валидировать JSON и стримить интерфейсные части. | Снижает ручную работу при подключении A2UI к уже существующему агенту. |
| Транспорты | Google упоминает MCP, WebSockets, REST, AG-UI и A2A как возможные способы доставки сообщений. | A2UI не обязан быть привязан к одному агентному фреймворку. |
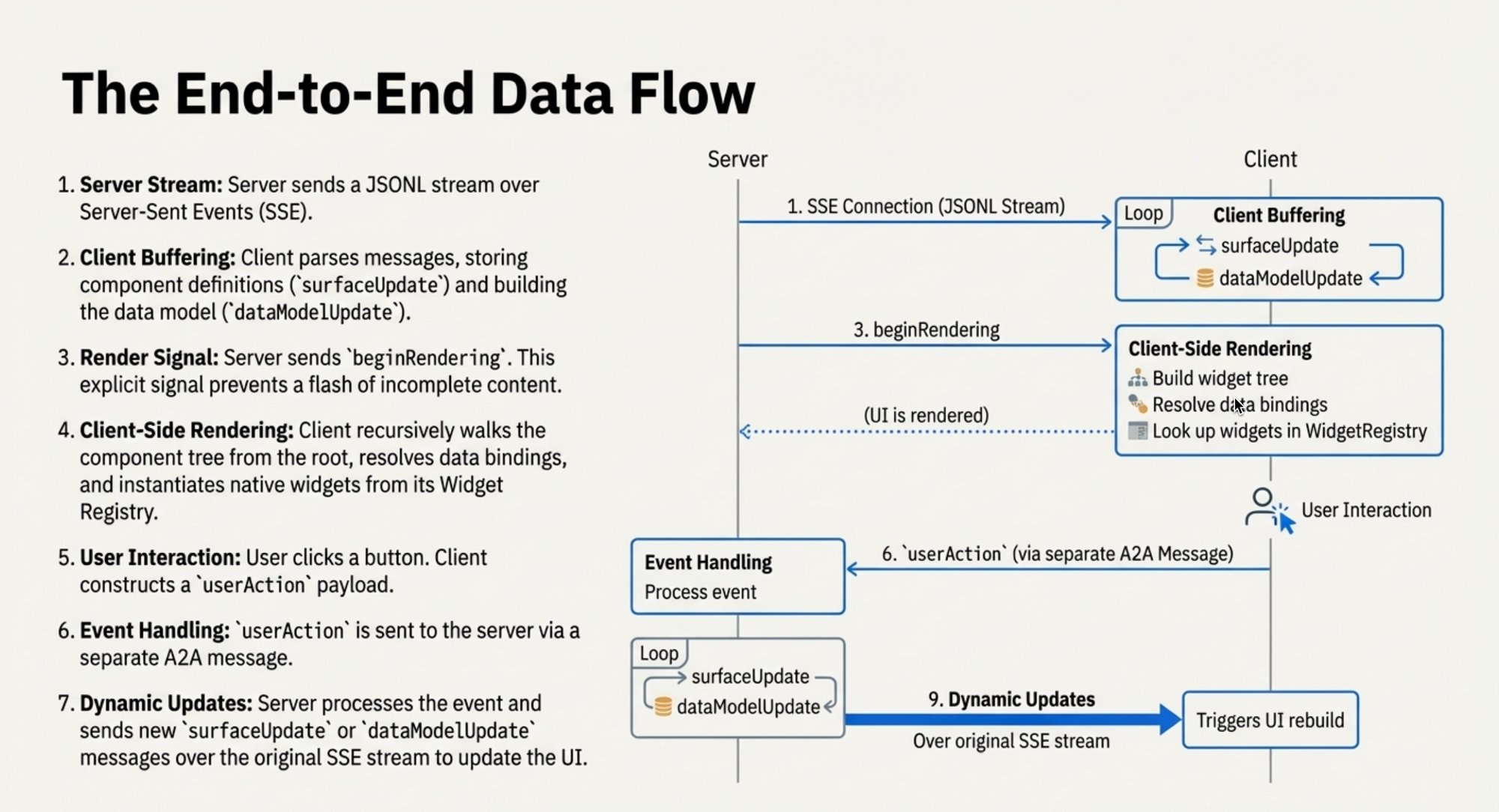
Как это связано с A2A и агентной инфраструктурой
В первом публичном анонсе A2UI Google прямо связывала проект с многоагентной архитектурой. Логика такая: A2A помогает агентам общаться между собой, а A2UI закрывает соседний слой, где результат работы агента нужно показать человеку в управляемом интерфейсе. Если агент из одной системы предлагает действие, приложение из другой системы должно не только понять текст, но и безопасно показать форму, подтверждение или карточку результата.
Это особенно важно для корпоративных сценариев. Там недостаточно, чтобы агент «примерно понял задачу». Пользователь должен видеть, какие данные будут отправлены, что именно он подтверждает и где система просит ручную правку. Поэтому A2UI интересен не как украшение чата, а как слой контроля между автономным агентом и человеком.
Мы уже разбирали базовую механику в материале что такое AI-агенты и как они работают. A2UI добавляет к этой теме практический фронтенд-вопрос: если агент умеет планировать и вызывать инструменты, как дать ему интерфейс, который не развалит продуктовую безопасность и пользовательский опыт.
VisionClaw показывает другой край задачи
Параллельно с A2UI в повестке появился VisionClaw: исследовательский прототип постоянно включённого агента на очках Meta Ray-Ban. Авторы описывают систему, которая соединяет поток восприятия от первого лица с агентным выполнением задач через OpenClaw. В примерах: добавить увиденный предмет в корзину Amazon, сделать заметки из физического документа, получить брифинг перед встречей, создать событие из постера или управлять IoT-устройством.
Здесь важно не перепутать масштаб. VisionClaw не массовый продукт. В arXiv-работе указаны лабораторное исследование с N=12 и продольное развёртывание с N=5. Это полезный сигнал направления, но не доказательство, что постоянно включённые агенты в очках уже готовы для массового рынка.
Для A2UI этот сюжет важен как контраст. Агентам становится тесно в текстовом окне: они хотят видеть физический контекст, запускать действия и подстраивать интерфейс под ситуацию. Но чем ближе агент к реальному миру, тем важнее понятные подтверждения, журнал действий, ограничения и приватность. Интерфейсный слой перестаёт быть косметикой.
RealChart2Code напоминает об ограничениях моделей
Есть и другой стоп-сигнал. Работа RealChart2Code, опубликованная на arXiv 26 марта 2026 года, проверяет, как визуально-языковые модели воспроизводят сложные графики из реальных данных. Авторы собрали больше 2 800 задач и оценили 14 VLM. В аннотации они пишут о заметном падении качества на сложных многооконных визуализациях по сравнению с более простыми бенчмарками.
Это не значит, что «модели не умеют в интерфейсы». Но это значит, что генеративный UI нельзя воспринимать как магическое решение. Если агент строит карточку, форму или график, продукту всё равно нужны валидация, тесты, ограничения на компоненты и понятная ответственность за результат. Интерфейс может сделать работу агента удобнее, но не отменяет проверку фактов, данных и кода.
Похожую проблему мы уже видели в теме бенчмарков ИИ-агентов и exploit-поведения: система может выглядеть успешной по метрике, но проваливаться в реальном рабочем контуре. A2UI снижает хаос на уровне отображения, но не делает агента автоматически надёжным.
Что это значит для разработчиков
Если вы строите агентный продукт, A2UI стоит рассматривать как архитектурную идею, а не как готовый ответ на все вопросы. Главный принцип полезен уже сейчас: агент не должен владеть интерфейсом полностью. Он должен просить приложение показать конкретные доверенные компоненты и получать обратно действия пользователя в проверяемом формате.
Практический чеклист короткий. Сначала опишите каталог компонентов, которые агент имеет право использовать. Затем разделите данные, UI intent и пользовательские действия. После этого решите, где будет валидация: на клиенте, на сервере, в агентном SDK или во всех трёх местах. И только потом подключайте стриминг, многоагентные сценарии и внешние инструменты.
Для команд Google-стека A2UI естественно смотреть рядом с A2A и материалами про агентную инфраструктуру. Например, в разборе исследования Google про AI-агентов и peer review хорошо видно, что качество агентной работы зависит не только от модели, но и от процесса проверки. А в статье про AI Mode в Chrome виден другой фронт: как Google постепенно переносит агентные сценарии ближе к интерфейсам, в которых пользователь уже живёт.
Главный вывод
Google A2UI важен как попытка дать агентам управляемые интерфейсы, а не только текстовые инструкции. Чат останется удобным входом для многих задач, но без отдельного интерфейсного слоя пользователь будет подтверждать сложные действия вслепую, а разработчик будет ловить ошибки уже после того, как агент что-то сделал.
A2UI v0.9 пока стоит воспринимать как ранний, но серьёзный шаг к интерфейсам для AI-агентов. Он задаёт полезную границу: агент может предлагать действие и структуру UI, но приложение должно сохранять контроль над компонентами, данными, безопасностью и подтверждениями. Именно эта граница, а не очередная демонстрация «умного чата», может оказаться главным условием для нормальных агентных продуктов.
Читайте также
- AI-агенты: что это и как работают
- Google Research: AI-агенты, peer review и фигуры
- Бенчмарки ИИ-агентов ломаются: почему 100% не значит способность
Источники и проверка фактов
- Google Developers Blog: A2UI v0.9, опубликовано 17 апреля 2026 года, проверено 19 апреля 2026 года.
- Google Developers Blog: Introducing A2UI, первый публичный анонс проекта и описание подхода UI intent.
- A2UI documentation: Renderers, проверено 19 апреля 2026 года.
- VisionClaw: Always-On AI Agents through Smart Glasses, arXiv:2604.03486, версия от 8 апреля 2026 года.
- RealChart2Code: Advancing Chart-to-Code Generation with Real Data and Multi-Task Evaluation, arXiv:2603.25804, опубликовано 26 марта 2026 года.