Галлюцинации ИИ в судах: почему агентам нужны проверки
В Нью-Йорке судьи нашли в апелляционном брифе как минимум три несуществующих дела и потребовали объяснить, почему юристов не нужно санкционировать. Это не запрет на ИИ, а показатель провала проверки источников.

По состоянию на 5 июня 2026 года галлюцинации ИИ в судах уже не выглядят экзотикой из первых историй про ChatGPT. В Нью-Йорке апелляционные судьи публично разобрали бриф, где, по их словам, были как минимум три дела, похожие на фиктивные, и ещё десять ссылок, искажающих право.
Галлюцинации ИИ в судах - это случаи, когда LLM или AI-инструмент создаёт правдоподобные, но несуществующие судебные решения, цитаты или правовые принципы, а человек включает их в процессуальный документ без проверки. В обычном чате такая ошибка раздражает. В суде она превращается в риск санкций, потерю доверия и лишнюю работу для судей и другой стороны.
История важна не потому, что судьи «запрещают ИИ». Они этого не делали. В деле Landberg v. City of New York проблема была проще и жёстче: кто-то подал документ с неподтверждёнными ссылками, а профессиональный процесс не поймал ошибку до заседания. Это ровно тот тип сбоя, который ждёт компании при внедрении AI-агентов без проверки источников, журналов действий и понятного владельца ответственности.

Что произошло в деле Landberg
Основной эпизод описала 404 Media 4 июня 2026 года. На заседании 20 мая в Supreme Court of the State of New York, Appellate Division: Second Judicial Department судьи Валери Братуэйт Нельсон и Гектор Ласаль больше двадцати минут разбирали апелляционный бриф по делу Judith Landberg v. City of New York.
Истец, Джудит Ландберг, подала иск после падения на кирпиче в tree well на тротуаре у собственности Whitman Owner Corp. Её представитель Майкл Сандерс из Law Offices of Michael S. Lamonsoff, PLLC пытался спорить о границе между sidewalk и tree well. Судья Нельсон сказала, что при подготовке к аргументам суд обнаружил в брифе как минимум три дела, которые выглядели фиктивными; сами дела и процитированные формулировки, по её словам, не находились.
На этом претензия не закончилась. Суд также указал на десять других ссылок, которые, как минимум предварительно, искажали правовой принцип. Вопрос был адресован не только Сандерсу, но и другой стороне. Адвокат города Нью-Йорка Элизабет Фридман объяснила, что читала брифы, но сфокусировалась на вопросе prior written notice и не поймала проблему со ссылками.
В тот же день суд выпустил order to show cause: все стороны должны были до 3 июня 2026 года объяснить, почему не нужно вводить sanctions and/or costs против counsel for the appellant, включая Law Offices of Michael S. Lamonsoff, PLLC и Майкла Сандерса, за briefs containing fabricated and/or erroneous legal authority and/or citations.
Здесь легко смешать два результата. 3 июня Appellate Division действительно оставил в силе решение о прекращении иска против Whitman Owner Corp. и города Нью-Йорка. Итог по существу дела был связан с tree well, обязанностями собственника, prior written notice и исключениями из муниципальной ответственности. Санкционный вопрос по ссылкам шёл отдельным ордером.
Почему ИИ выдумывает судебные дела
LLM не хранит юридическую базу как Westlaw или Lexis. Она генерирует текст, который статистически похож на ответ. В праве это особенно опасно: название дела, номер репортера, цитата и формулировка нормы могут выглядеть правдоподобно даже тогда, когда такой authority не существует.
Юридическая ссылка работает только как проверяемый указатель. Судья, оппонент и собственная команда должны иметь возможность открыть дело, прочитать контекст и понять, стоит ли оно за тезисом. Если модель выдала «похожую» ссылку, а юрист не дошёл до первоисточника, в документ попадает не исследование, а имитация исследования.
ABA в октябре 2025 года описывала ту же проблему как уже регулярный риск для судебных подач: адвокаты, судьи и даже эксперты оказывались вовлечены в документы с несуществующими ссылками или неверными цитатами. Базовая рекомендация при этом не технологическая: перед подачей нужно лично прочитать и проверить каждое дело, на которое ссылается документ.
Кто отвечает за фиктивные ссылки
Суд не обязан разбираться, какая именно модель ошиблась, кто ввёл prompt и была ли у пользователя платная подписка. В процессе отвечает человек и организация, подписавшие документ. Именно поэтому в Landberg суд обратился к counsel for the appellant и фирме, а не к поставщику ИИ-инструмента.
Для юристов это неприятный, но полезный урок. Генеративный ИИ может ускорить черновик, найти направление поиска или сформулировать аргумент. Он не может заменить финальную проверку authority. Ссылка должна проходить по крайней мере три шага: существует ли дело, точна ли цитата, поддерживает ли дело именно тот тезис, ради которого его вставили.
Ответственность второй стороны тоже не исчезает. В истории 404 Media судьи отдельно спросили представителя города, почему она не сообщила суду о возможных фабрикациях и искажениях. Для состязательного процесса это важная деталь: если оппонент видит сомнительные ссылки и молчит, ущерб получает не только автор ошибки, но и суд.
Как это связано с AI-агентами
На первый взгляд Landberg - история о юридическом брифе, а не о корпоративных агентах. Но механизм сбоя один и тот же: система генерирует убедительный артефакт, человек доверяет форме, процесс не требует доказательства происхождения.
Это особенно заметно на фоне Microsoft Scout. В официальном анонсе от 2 июня Microsoft называет Scout первым Autopilot-агентом: он работает в Microsoft 365, получает собственную Entra identity, подключается к Teams, Outlook, OneDrive и SharePoint, а чувствительные действия могут требовать human sign-off. 404 Media в тот же день написала, что во внутренних материалах Microsoft для Scout фигурировала цель сделать пользователей «addicted» к инструменту до расширения функций.
Scout не связан с делом Landberg, и смешивать эти истории нельзя. Но они показывают одну редакционную точку: чем ближе AI-инструмент к реальным документам, календарям, письмам, судебным брифам и внешним действиям, тем меньше права на «потом проверим». Агенту нужны ограничения до масштабирования, а не после первого публичного провала.
Рядом лежит и тема prompt injection в Microsoft Copilot Cowork. Если агент читает недоверенный текст и одновременно имеет доступ к привилегированным действиям, проблема уже не только в галлюцинациях. Недоверенный контент может повлиять на решение агента, а правдоподобный, но ложный вывод может уйти в документ как будто он проверен.
Какие проверки нужны перед подачей документа
Для юридической команды минимальный контур выглядит скучно, зато работает.
- Каждая судебная ссылка открывается в первичной базе или официальном источнике, а не проверяется тем же чатботом, который её предложил.
- Цитата сверяется с полным текстом решения, включая контекст до и после нужного абзаца.
- В документе остаётся след проверки: кто подтвердил ссылку, где она найдена, когда проверена.
- Любой AI-generated draft перед подачей проходит human sign-off, а не просто «прочитал по диагонали».
- Внутренний workflow запрещает модели самой закрывать вопрос об истинности собственных ссылок.
Для AI-агентов этот список расширяется. Нужны tool permissions с минимальными правами, audit log всех действий, policy gates перед внешней отправкой и отдельный режим для высокорисковых задач: право, финансы, медицина, безопасность, кадровые решения. Такие проверки не снимают ответственность с юриста или менеджера, зато убирают главный источник аварии - невидимую цепочку от генерации до действия.
| Риск | Что ломается | Какой контроль нужен |
|---|---|---|
| Фиктивная ссылка | Суд не может проверить authority, доверие к брифу падает | Проверка по первичной базе и запрет на self-verification моделью |
| Верная ссылка, неверный тезис | Документ искажает право даже без полностью выдуманного дела | Чтение полного решения и ручная сверка цитаты с аргументом |
| Агент действует с широкими правами | Ошибка превращается в отправленное письмо, файл или заявку | Минимальные права, approval gate и журнал действий |
| Недоверенный входной текст | Prompt injection или мусорный источник влияет на вывод агента | Разделение данных и инструкций, проверка источников, sandbox для инструментов |
Эта логика пересекается с более широким кластером безопасности агентских систем: меньше автономности по умолчанию, больше проверяемых действий и ясная граница, где машина предлагает, а человек берёт ответственность.
Почему safety-модель не решает весь кейс
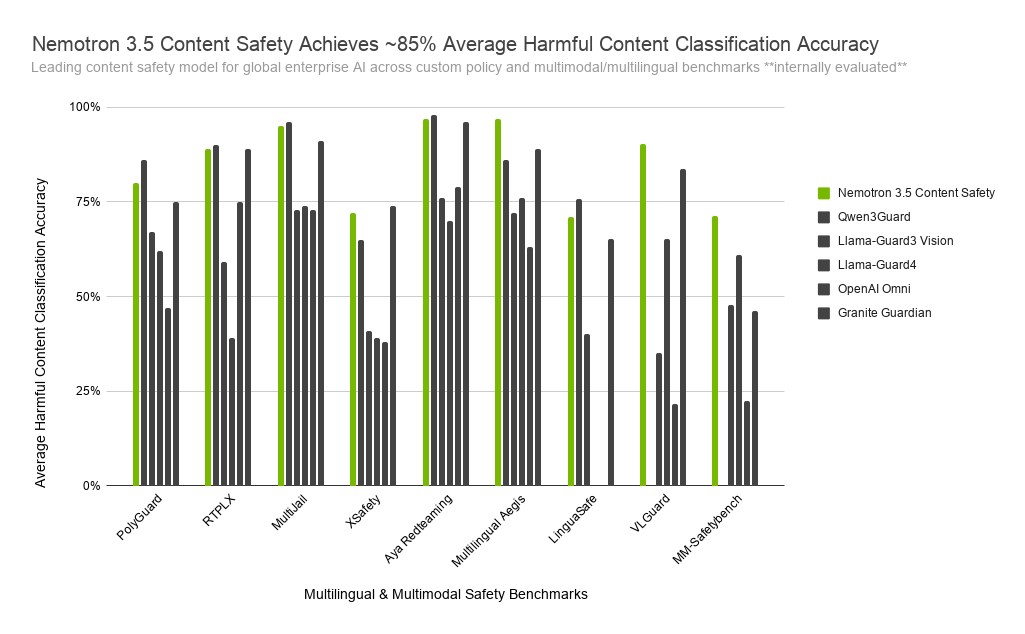
NVIDIA 4 июня выпустила Nemotron 3.5 Content Safety: 4B-модель на базе Gemma 3, которая объединяет мультимодальную проверку, поддержку кастомных политик и reasoning traces. В бенчмарках Hugging Face/NVIDIA указывает примерно 85% средней точности harmful-content classification по набору мультимодальных и мультиязычных тестов, 96,5% на Multilingual Aegis и 88,8% на RTP-LX.
Это полезный технический фон для корпоративных агентов. Модератор может проверить текст, изображение, ответ ассистента и доменную политику в одном вызове. Reasoning trace помогает аудитору понять, почему контент помечен как unsafe. Для enterprise-сценариев это уже ближе к настоящему guardrail, чем простой фильтр запрещённых слов.
Но Landberg не сводится к harmful content. Фиктивная судебная ссылка не обязательно выглядит вредной по safety-таксономии. Она может быть вежливой, юридически оформленной и полностью ложной. Поэтому safety-модель - только один слой. Для права нужен другой валидатор: поиск по авторитетной базе, сверка цитаты и человек, который понимает, что именно доказывает ссылка.
Что меняется для профессиональных команд
Урок Landberg шире юридической практики. Любая команда, где ИИ готовит документы для внешнего мира, должна отделять drafting от verification. Модель может помогать написать, но не должна сама назначать результат проверенным.
Для разработчиков это знакомая схема: код проходит тесты, сборку и review, даже если его написал агент. Для юристов аналогом становятся проверенные citations, docket history и read-before-file. Для менеджеров - источник чисел, ссылка на документ, владелец approve. Во всех случаях важен не запрет на ИИ, а доказуемая цепочка: откуда взялся факт, кто его проверил, какая система зафиксировала проверку.
Поэтому главный вывод для AI governance простой. Чем убедительнее ИИ пишет, тем строже должен быть процесс верификации. Судебная подача с выдуманными делами показывает, что «выглядит профессионально» уже нельзя считать сигналом качества. В профессиональном контуре качество начинается там, где у текста появляются источники, журнал действий и ответственный человек.
Читайте также
- Microsoft Scout: AI-коллега для офиса и ставка Build 2026
- Prompt injection в Microsoft Copilot Cowork: риск утечки файлов
- Безопасность агентских систем: атаки, GPU-часы и MEMO
Источники и проверка фактов
- 404 Media: Watch These Judges Rip Into Lawyers For Citing Cases That Don't Exist, опубликовано 4 июня 2026 года, проверено 5 июня 2026 года.
- NY Courts: видеозапись заседания по делу Landberg, фрагмент с обсуждением ссылок начинается примерно после 19-й минуты, проверено 5 июня 2026 года.
- DocumentCloud: Landberg v. City of New York, Order to Show Cause, ордер от 20 мая 2026 года, проверено 5 июня 2026 года.
- DocumentCloud: Landberg v. City of New York, Decision & Order D80718, решение от 3 июня 2026 года, проверено 5 июня 2026 года.
- Microsoft 365 Blog: Introducing Microsoft Scout, опубликовано 2 июня 2026 года, проверено 5 июня 2026 года.
- 404 Media: Microsoft Wants to Make People Addicted to Scout, опубликовано 2 июня 2026 года, проверено 5 июня 2026 года.
- Hugging Face / NVIDIA: Nemotron 3.5 Content Safety, опубликовано 4 июня 2026 года, проверено 5 июня 2026 года.
- American Bar Association: AI Hallucinations Are Real—and How to Avoid Them, опубликовано 30 октября 2025 года, проверено 5 июня 2026 года.