EMO: MoE-модель, которая сохраняет качество на части экспертов
Ai2 обучила MoE так, чтобы эксперты группировались по смысловым доменам. В тестах 25% экспертов дают минус 1 пункт, 12,5% — около 3 пунктов.

Факт-чек: данные в статье проверены 16 мая 2026 года по официальному блогу Ai2, arXiv, GitHub и странице NVLabs SANA-WM.
EMO MoE-модель от Allen Institute for AI и UC Berkeley попала в редкий для research-новостей нерв: она не просто добавляет ещё одну вариацию Mixture-of-Experts. Она показывает, что MoE можно обучать так, чтобы группы экспертов были полезны сами по себе, а не распадались на случайные токеновые паттерны.
Главная цифра звучит почти неправдоподобно, но она подтверждена и в блоге Ai2, и в работе на arXiv: при использовании 25% экспертов EMO теряет около 1 процентного пункта качества, при 12,5% экспертов - около 3 пунктов. Для стандартной MoE той же архитектуры такой режим ломается заметно сильнее.
Для читателя, который запускает LLM не в лаборатории с бесконечным бюджетом, смысл простой: часть исследований уходит от идеи «всегда грузить всю большую модель» к вопросу «можно ли выбрать нужный модуль под задачу». Это близко к теме экономии памяти и вычислений при запуске LLM, но решает другую задачу: не ужать веса после обучения, а научить архитектуру раскладываться на осмысленные части уже во время pretraining.
Что именно сделала EMO
Обычная MoE-модель активирует несколько экспертов на каждый токен. На бумаге это выглядит экономно: полный пул большой, но на конкретном токене работает только часть параметров. На практике для длинного запроса разные токены могут обращаться к разным экспертам, и задача всё равно затрагивает почти весь набор.
EMO меняет правило обучения. Вместо независимого выбора экспертов для каждого токена модель ограничивает токены одного документа общим пулом экспертов. Документ здесь работает как слабый сигнал домена: если текст про код, медицину или политику, его токены чаще должны держаться рядом, а не разъезжаться по экспертам, отвечающим за предлоги, пунктуацию или артикли.
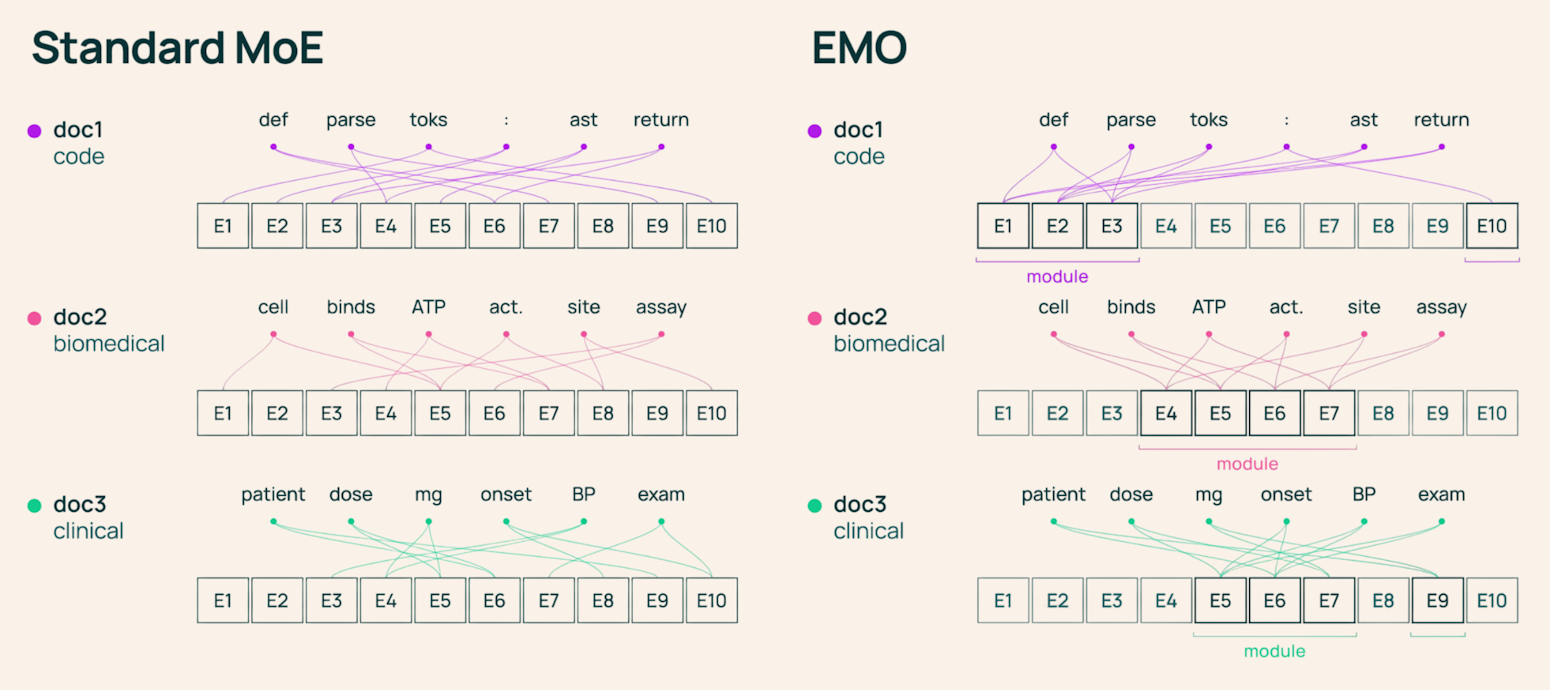
В итоговой версии Ai2 обучила EMO как 1B-active / 14B-total MoE: 8 активных экспертов из 128 на токен, 1 трлн токенов обучения. Команда также выложила код, чекпоинты EMO и базовой модели, а также сопоставимую стандартную MoE для сравнения.
Проверенные цифры EMO
| Параметр | Что заявлено | Источник |
|---|---|---|
| Архитектура | 1B активных и 14B общих параметров | Ai2, arXiv |
| Эксперты | 8 активных из 128 всего | Ai2 |
| Обучение | 1 трлн токенов | Ai2, GitHub |
| Selective expert use | 25% экспертов: минус около 1 п.п.; 12,5% экспертов: минус около 3 п.п. | arXiv, Ai2 |
| Публикация артефактов | Модель EMO, baseline, код и evaluation scripts | GitHub, Hugging Face |
Важная деталь: результат про 12,5% экспертов не означает, что любую MoE можно просто обрезать в восемь раз и получить ту же модель дешевле. Экспертов выбирают под задачу или домен, ранжируя их по использованию на небольшом проверочном наборе. Ai2 пишет, что иногда хватает даже одного примера с few-shot-подсказками, но это всё ещё процедура выбора, а не магический флаг в настройках инференса.
Почему это интересно для открытых моделей
Сейчас открытые LLM часто обсуждают через размер, лицензию, бенчмарки и удобство запуска в своём контуре. EMO добавляет ещё одну ось: можно ли из одной sparse-модели собрать рабочий поднабор под конкретный домен. Если такой подход масштабируется, то MoE станет ближе к библиотеке модулей, чем к монолитному файлу весов.
Для open-source-сообщества это важно по двум причинам. Во-первых, исследователи получают воспроизводимые артефакты, а не только графики в статье. Во-вторых, появляется практичный язык для обсуждения развёртывания: не «у нас 14B total», а «какой набор экспертов нужен под код, математику, биомедицину или корпоративный поиск».
Это не заменяет выбор открытой модели под продуктовый сценарий и не отменяет квантизацию. Скорее, EMO показывает, как сама архитектура может дать более удобный баланс памяти и качества. У квантизации вопрос: как хранить и считать уже обученную модель дешевле. У EMO вопрос другой: как обучить модель так, чтобы часть экспертов сохраняла смысловую целостность.
Где границы результата
EMO пока не готовый производственный рецепт для всех больших MoE. Масштаб релиза: 14B total, а не система на сотни миллиардов или триллионы параметров. Результат нужно проверять на других датасетах, языках, задачах и схемах маршрутизации. Отдельный риск для русскоязычной аудитории: доменные кластеры, показанные Ai2, описаны на англоязычных данных и бенчмарках; перенос на русский и смешанные корпоративные корпуса нельзя считать доказанным.
Авторы сами называют открытые вопросы: как лучше выбирать и комбинировать подмножества экспертов, как обновлять отдельные модули без повреждения полной модели, как использовать такую структуру для интерпретируемости и контроля. Это правильный тон для research-релиза: сильный сигнал, но не обещание дешёвого инференса для любой LLM уже завтра.
SANA-WM: соседний пример той же гонки за эффективностью
Второй свежий research-повод из того же потока новостей - SANA-WM от NVIDIA/NVLabs. Это не конкурент EMO и не тема того же поискового интента. EMO про модульность MoE в языковых моделях, SANA-WM про world model для видео. Но обе работы хорошо показывают общий сдвиг: качество уже недостаточно, исследователи всё чаще продают эффективность как главный результат.
По статье SANA-WM на arXiv и официальной странице проекта, модель имеет 2,6B параметров, генерирует 720p-видео длиной до 60 секунд с 6-DoF camera control, обучалась на примерно 213 тыс. публичных видеоклипов с позами камеры и была обучена за 15 дней на 64 H100. В работе также заявлен инференс на одной GPU для 60-секундного клипа; дистиллированный вариант с NVFP4 может денойзить 60 секунд 720p на RTX 5090 за 34 секунды.
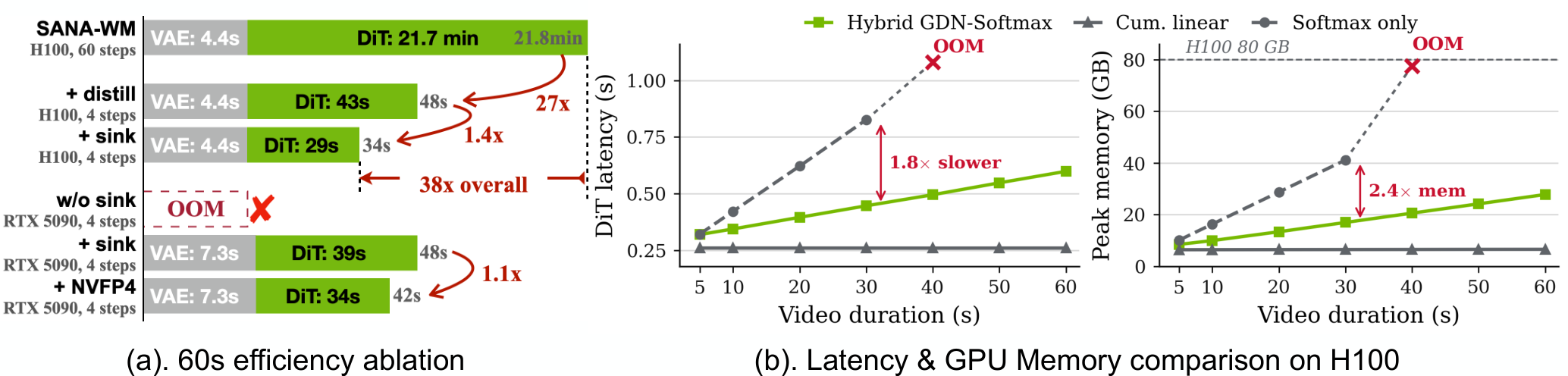
С SANA-WM важно не перепродать результат. Это не «универсальный симулятор мира» и не обещание real-time-видео на любой видеокарте. В тексте лучше держать его как короткий второй блок: у генерации видео нейросетями свой кластер, а у EMO свой. Если SANA-WM делать центральной темой, нужен отдельный SEO-brief и отдельный slug.
Что забрать из этого релиза
EMO интересна не тем, что «экономит 87,5% модели». Такая формулировка была бы слишком грубой. Сильная часть работы в другом: если обучать MoE с ограничением на общий документный пул, эксперты начинают группироваться по смысловым доменам, и эти группы можно использовать отдельно с умеренной потерей качества.
Для разработчиков это пока не новая кнопка в vLLM. Но направление важное: будущие открытые MoE могут оцениваться не только по среднему score в таблице, а по тому, насколько хорошо они позволяют выбрать, перенести, обновить и проверить отдельные экспертные подмодули. Это уже ближе к инженерной эксплуатации LLM, чем к гонке за большим числом параметров.
Читайте также
- Квантизация LLM: как выбрать GGUF, GPTQ и AWQ в 2026 году
- Open-source модели в 2026: как выбирать между Llama, Mistral и Qwen
- Нейросети для генерации видео: Sora, Runway, Kling и другие



