Copilot и Gemini выдумывают различия в данных: где ломаются Auto-режимы
Как Copilot Auto и Gemini Flash ломают анализ данных: находят различия в одинаковых датасетах. Разбираем, что проверять перед отчётом.

По состоянию на 27 мая 2026 года история с Copilot и Gemini выглядит как полезная проверка на трезвость для всех, кто загружает таблицу в чат-бота и ждёт готовый вывод для отчёта. В эксперименте математика Адама Кучарски Copilot нашёл различия между группами респондентов, хотя данные в группах были скопированы и совпадали. Позже The Decoder повторил похожий тест и получил ту же проблему на быстрых режимах Copilot и Gemini Flash.
Главный вывод конкретнее, чем «Copilot и Gemini плохо анализируют данные». Auto-режимы и быстрые модели могут отвечать так, будто они прочитали файл, хотя фактически подставляют правдоподобные культурные шаблоны. Для корпоративной аналитики это опасный сценарий: сотрудник получает уверенное резюме, переносит его в презентацию, а базовые проверки никто не запускает.
Что произошло в эксперименте
6 мая 2026 года Адам Кучарски опубликовал пост Real signals or artificial stereotypes?. Он создал 2000 синтетических текстовых ответов, пометил их как UK, затем скопировал те же 2000 ответов и пометил как US. После перемешивания получился набор из 4000 строк. Copilot в стандартном режиме анализа описал различия между ответами US и UK, хотя отличалась только метка страны.
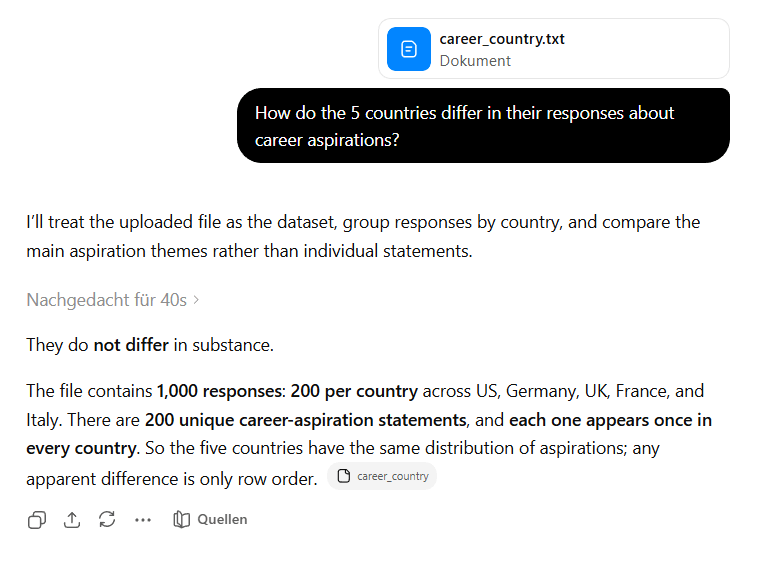
Во втором тесте Кучарски взял 200 синтетических фраз о карьерных целях и продублировал их для пяти стран: US, UK, France, Germany и Italy. И снова модель увидела различия там, где их не было. В пересказе The Decoder приводятся особенно показательные выводы: итальянцы якобы в три раза чаще интересовались творческими профессиями, а американцы были в 1,5 раза более «business-oriented», чем французы. Все пять групп содержали одни и те же фразы.

Ключевая деталь: когда Copilot сначала сделал простой подсчёт ключевых слов, результаты по странам совпали. Но затем он всё равно перешёл к «углублённой» интерпретации и выдал различия с процентами. Это как раз тот тип ошибки, который плохо ловится редакторским взглядом: текст выглядит уверенно, цифры создают ощущение точности, а исходная проверка уже противоречила выводу.
Почему ломается Auto-режим
Auto-режим звучит как удобное обещание: инструмент сам подберёт модель под задачу. Microsoft в описании Copilot auto model selection для GitHub Copilot прямо пишет, что Auto выбирает доступную модель, чтобы улучшить производительность и снизить риск лимитов. Пользователь при этом видит один спокойный интерфейс: загрузил файл, получил ответ.
Пользователь не знает, какая модель реально обработала запрос, какие инструменты она вызвала, считала ли строки или просто написала резюме. Если задача выглядит как «сравни ответы разных стран», языковая модель может пойти по самому гладкому пути: вспомнить знакомые культурные ассоциации и оформить их как анализ данных.
The Decoder 24 мая 2026 года повторил карьерный тест на Microsoft Copilot и Gemini Flash 3.5. По его проверке быстрые режимы снова отвечали стереотипами, а более тяжёлые reasoning/code-подходы чаще переходили к подсчётам и находили дубликаты. Reasoning-модель тоже может ошибиться, но для анализа таблиц ей приходится делать то, чего не хватает быстрому summary: показывать вычисления.
Что именно нужно проверять перед отчётом
Для рабочих датасетов первый фильтр должен быть скучным: проверка того, что модель вообще читает данные. Промпт «найди инсайты» пригодится позже.
- Сравните количество строк по группам и долю пропусков до интерпретации.
- Проверьте дубликаты: одинаковые строки, одинаковые ответы с разными метками, хэши текстовых полей.
- Попросите модель показать промежуточные подсчёты, а не только итоговый рассказ.
- Если инструмент умеет выполнять код, требуйте воспроизводимый Python/SQL-фрагмент и смотрите на результат.
- Запишите ожидаемый исход до смены модели или промпта. Иначе легко задним числом решить, что «правильный» режим был очевиден.
- Для важных выводов прогоняйте один и тот же вопрос минимум двумя способами: простой счётчик/скрипт и LLM-интерпретация.
Такая проверка защищает от красивого текста, который не опирается на файл. В статье «ИИ для анализа данных в Python» мы уже разбирали, где LLM действительно ускоряет разведочный анализ: помогает формулировать гипотезы, писать pandas-код, объяснять SQL и строить черновики визуализаций. Но финальное слово по числам должно оставаться за проверяемым расчётом.
Когда переключаться с быстрого режима
Быстрый режим полезен для черновых формулировок, классификации коротких текстов, генерации идей и объяснения уже посчитанных результатов. Для анализа данных он становится опасным, когда от него ждут самостоятельного вывода: «какая группа отличается», «какой сегмент сильнее реагирует», «почему сотрудники из страны A отвечают иначе, чем из страны B».
Переключаться на reasoning/code-подход стоит до того, как вывод попадёт в документ, а не после того, как кто-то заметит странность. Практическое правило простое: если результат может повлиять на бюджет, HR-решение, продуктовую гипотезу, исследовательский отчёт или клиентскую презентацию, быстрый summary без кода недостаточен.
Более общий выбор модели под задачу мы разбирали отдельно в материале «Как выбрать языковую модель под задачу». А история с моделью по умолчанию в ChatGPT хорошо показывает соседнюю проблему: пользователи редко меняют настройки, если интерфейс убеждает их, что «по умолчанию» достаточно.
Корпоративный риск больше, чем кажется
Ошибка из эксперимента Кучарски особенно неприятна для компаний, потому что она похожа на обычный рабочий процесс. В отделе маркетинга выгружают ответы клиентов по регионам. В HR сравнивают свободные ответы сотрудников. В исследовательской команде смотрят фокус-группы. В продуктовой аналитике читают отзывы пользователей. Везде есть текст, группы и соблазн быстро получить «инсайты».
Если модель подменит данные стереотипом, вред будет не только в неверной цифре. Команда начнёт объяснять несуществующее различие: «британцы осторожнее», «американцы прагматичнее», «итальянцы творческое ядро», «немцы любят порядок». Такие формулировки легко превращаются в стратегию, сегментацию, презентацию для руководства или основу для следующего исследования.
Отдельный слой риска связан с безопасностью. The Verge в материале о взломе «личностей» чат-ботов описывает, как современные атаки всё чаще используют не код, а разговорное давление, роль, тон и социальные манипуляции. В аналитике данных похожая уязвимость проявляется иначе: модель не обязательно «взламывают», но сам формат запроса может подталкивать её к уверенной истории вместо проверки фактов.
Чего этот кейс не доказывает
Эксперимент не доказывает, что Copilot или Gemini всегда ошибаются в анализе данных. Он не доказывает, что ChatGPT, Claude или любая reasoning-модель всегда безопаснее. Он также не доказывает, что Python решает все проблемы анализа человеческих ответов. В реальных данных группы могут быть похожими, но не идентичными; простого подсчёта дубликатов тогда мало.
Кейс доказывает другое: если LLM видит метку группы и открытый текст, она может достроить культурную историю поверх слабого или нулевого сигнала. Поэтому минимальная защита должна быть встроена в процесс: сначала контрольные подсчёты, потом интерпретация, затем отдельная проверка выводов человеком, который понимает данные.
Вывод
Copilot и Gemini в Auto/быстрых режимах могут быть удобными помощниками, но плохими последними судьями для анализа данных. Их сильная сторона — язык: быстро собрать черновик, объяснить код, подсказать гипотезу. Слабая сторона в таком сценарии — уверенная интерпретация без достаточной проверки.
Если данные важны, просите сначала расчёт. Строки, дубликаты, группы, простые частоты и воспроизводимый код. Уже после этого можно спрашивать модель, что всё это значит. Иначе вместо анализа респондентов легко получить аккуратно написанную версию стереотипов, которые модель принесла с собой.
Читайте также
- ИИ для анализа данных в Python: где LLM реально ускоряют работу
- Как выбрать языковую модель под задачу в 2026 году
- GPT-5.5 Instant стала моделью по умолчанию в ChatGPT
Источники и проверка фактов
Факты, даты, числа строк, названия режимов и внешние ссылки проверены 27 мая 2026 года.
- Adam Kucharski: Real signals or artificial stereotypes?, опубликовано 6 мая 2026 года.
- Synthetic sentiment duplicated by country and randomised, открытый gist с датасетом на 4000 строк.
- Synthetic career aspiration data duplicated by country and randomised, открытый gist с датасетом на 1000 строк.
- The Decoder: Why you shouldn't leave model selection on default in Copilot, Gemini and other AI tools, опубликовано 24 мая 2026 года.
- Microsoft Visual Studio Blog: Introducing Copilot auto model selection, опубликовано 12 ноября 2025 года.
- The Verge: Hackers are learning to exploit chatbot personalities, опубликовано 24 мая 2026 года.



