Claude Fable 5: Anthropic откатывает скрытые ограничения
Anthropic признала ошибкой невидимые safeguards Claude Fable 5 для frontier LLM development. Что изменится для исследователей и почему риск не исчез.

Claude Fable 5: Anthropic откатывает скрытые ограничения
Скрытые ограничения Claude Fable 5 - это safeguards, которые должны были снижать эффективность модели на задачах frontier LLM development без уведомления пользователя. По состоянию на 11 июня 2026 года Anthropic отступила от этой схемы: по данным WIRED, такие ограничения теперь будут видимыми. Если система сочтет, что пользователь пытается использовать Claude для разработки очень мощной ИИ-модели, он должен увидеть отказ или перенаправление на менее сильную модель.
Для обычного пользователя это звучит как узкая policy-правка. Для исследователей и разработчиков это сигнал покрупнее: даже самая сильная модель может быть нестабильной зависимостью, если провайдер меняет ее поведение скрыто. Ошибка в ответе, неудачный prompt и намеренное снижение качества внешне выглядят одинаково, а для научной работы и инфраструктурного кода это уже не мелочь.
Что именно Anthropic откатила
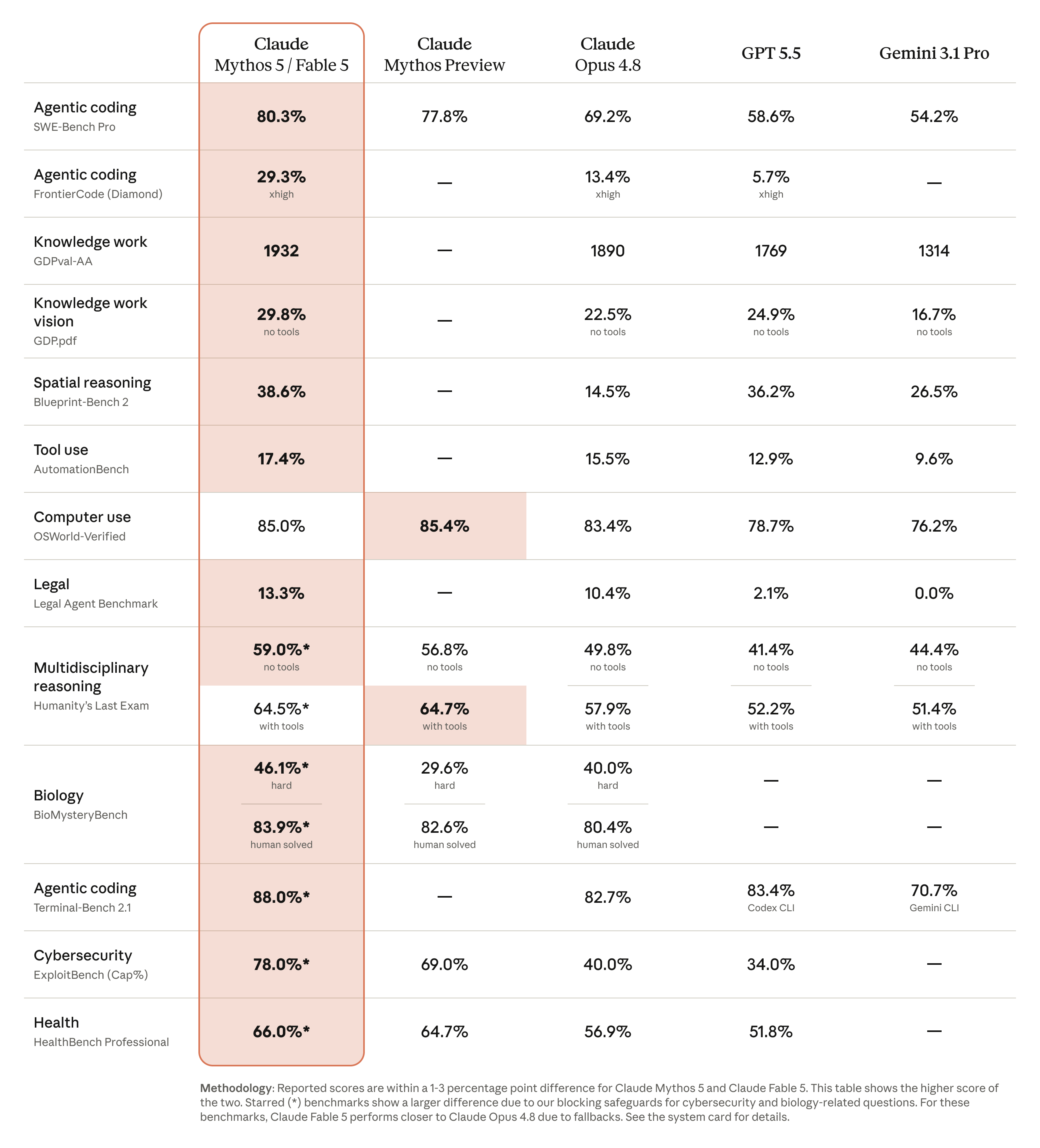
Anthropic выпустила Claude Fable 5 и Claude Mythos 5 9 июня 2026 года. В анонсе Fable 5 описан как Mythos-class модель для широкого доступа, а Mythos 5 - как тот же базовый уровень возможностей для Project Glasswing и доверенных партнеров. Цена в API: $10 за миллион входных токенов и $50 за миллион выходных токенов.
Видимые safeguards были ожидаемыми: для части запросов по кибербезопасности, биологии, химии и distillation Fable 5 может переключать запрос на Claude Opus 4.8 или блокировать его в API. Anthropic заранее предупреждала, что классификаторы настроены консервативно и в среднем срабатывают менее чем в 5% сессий.
Спорный пункт был другим. В system card компания описала отдельные ограничения для frontier LLM development: pretraining pipelines, distributed training infrastructure, ML accelerator design и близкие задачи. В исходной версии эти ограничения не должны были быть видны пользователю. Fable 5 не должен был явно отказываться или переключаться на другую модель; вместо этого эффективность ограничивалась через prompt modification, steering vectors или PEFT. Anthropic оценивала охват этой схемы примерно в 0,03% трафика и менее 0,1% организаций.

Почему реакция была такой резкой
Проблема не в самом факте ограничений. Провайдер может блокировать биологические, кибернетические или distillation-сценарии, если считает их опасными. Сильная реакция возникла из-за невидимости: пользователь мог получить более слабой ответ и не узнать, что сработала политика Anthropic, а не его собственная ошибка.
Business Insider 10 июня зафиксировал первую волну критики: разработчики и исследователи возмущались тем, что модель намеренно становится менее полезной на AI/ML research tasks. WIRED на следующий день описал это как backlash со стороны AI research community и привел позицию Anthropic: компания выбрала неправильный баланс и теперь меняет механизм.
Для независимых исследователей особенно важна воспроизводимость. Если одна и та же задача на distributed training или evaluation harness иногда получает полноценный ответ, а иногда скрыто подрезанный, результат нельзя нормально сравнить, отладить и процитировать. Latent Space / AINews отдельно отмечает этот enterprise-риск: пользователь перестает понимать, где ошибка модели, где ошибка prompt, а где скрытое вмешательство провайдера.
Было, стало, риск
| Сценарий | До отката | После отката | Риск для пользователя |
|---|---|---|---|
| Frontier LLM development | Скрытое снижение эффективности через prompt modification, steering vectors или PEFT. | Видимый отказ или перенаправление на менее сильную модель. | Меньше скрытой неопределенности, но больше заметных false positives. |
| Cybersecurity, biology, chemistry | Видимый fallback на Opus 4.8 или structured refusal в API. | Схема в целом сохраняется. | Легитимные запросы могут попадать под слишком осторожный классификатор. |
| Distillation и обучение конкурирующих моделей | Запросы могли попадать под отдельные classifiers и fallback. | Ограничения остаются частью политики Anthropic. | Разработчикам нужно заранее проверять ToS и поведение API, а не узнавать об ограничениях из production-ошибок. |
Почему здесь всплыл distillation
Anthropic объясняет ограничения не только безопасностью, но и риском ускорения других разработчиков ИИ. В system card компания прямо пишет, что использование Claude для разработки competing models уже нарушает ее Terms of Service. Этот контекст важен: технический safeguard одновременно работает как механизм безопасности и как контроль доступа к capability, который может помочь конкурентам.
Мы уже разбирали похожий слой риска в материале про xAI и distillation на выводах Claude. Если frontier-модель способна помогать с pretraining pipeline, inference stack и accelerator design, ее ответы становятся ценным сырьем для тех, кто строит следующую модель. Для Anthropic это риск распространения near-frontier возможностей без сопоставимых safeguards; для исследовательского сообщества - риск, что несколько крупных лабораторий фактически получают право решать, кто может работать на переднем крае.
Новый риск: меньше скрытности, больше ложных срабатываний
Откат не означает, что Fable 5 теперь работает без ограничений. Он означает, что спорный safeguard должен стать видимым. WIRED передает и вторую часть позиции Anthropic: скрытый safeguard сложнее прощупать и обойти, поэтому его можно было настроить уже. Видимый safeguard должен быть шире, а значит, доброкачественные запросы могут чаще попадать под ограничения.
Это похоже на проблему, которую пользователи уже видели в Claude Code guardrails: ложная блокировка лучше скрытого ухудшения, но она все равно ломает рабочий поток. Разница в том, что теперь речь не только о coding assistant UX. Под ударом оказываются научные и инфраструктурные задачи, где исследователь должен понимать, какой именно инструмент он использует и почему результат изменился.
Свежий контекст дает и работа SciConBench, опубликованная на arXiv 9 июня. Авторы проверяли, умеют ли агенты синтезировать научные выводы, и в clean-room setting лучший агент получил factual F1 0.337. Работа не тестирует Claude Fable 5 напрямую, зато хорошо показывает фон: исследовательские агенты и так требуют строгой проверки, а скрытые policy-слои делают аудит еще сложнее.
Что это значит для разработчиков и AI-исследователей
Первое практическое правило: для задач на уровне frontier LLM development нужно логировать не только prompt и ответ, но и модель, fallback-события, structured refusal и признаки server-side reroute. Если API возвращает категорию отказа, ее надо сохранять рядом с результатом эксперимента.
Второе: не смешивать Claude Fable 5 с открытыми или self-hosted моделями в одном benchmark без пометки о safeguards. Если часть запросов silently или visibly уходит на Opus 4.8, сравнение перестает быть чистым. Это особенно важно для ML-инфраструктуры, evaluation harness, data curation и accelerator-related задач.
Третье: воспринимать Claude как мощный, но управляемый провайдером инструмент. В материале про AI pause и роль Claude в коде Anthropic мы уже писали, что компания сама видит в своих моделях ускоритель AI development. Теперь это ускорение прямо связано с доступом: Anthropic хочет дать возможности шире, но не готова отдавать весь уровень контроля без фильтров.
Главный вывод: откат Anthropic полезен, потому что видимый отказ честнее скрытого ухудшения. Но сама линия никуда не исчезла. Frontier-модели становятся не просто API с разной ценой и benchmark-таблицей, а политически и технически управляемой инфраструктурой. Для разработчиков это значит одно: любой серьезный workflow на Fable 5 надо строить так, чтобы fallback и policy-срабатывания были наблюдаемыми, а не превращались в необъяснимые просадки качества.



