Claude Code guardrails: почему ложные блокировки бьют по рабочему опыту
Claude Code guardrails после Opus 4.7 дали волну ложных блокировок даже в легитимных задачах и ударили по рабочему опыту.

Claude Code guardrails за несколько дней превратились из технической детали релиза в отдельную продуктовую проблему. После выхода Claude Opus 4.7 16 апреля 2026 года Anthropic включила новые real-time cyber safeguards, а пользователи Claude Code начали публично жаловаться на ложные блокировки даже в легитимных сценариях. Для разработчика это выглядит не как тонкая настройка защитной политики, а как сбой рабочего инструмента.
По состоянию на 26 апреля 2026 года важно держать две линии отдельно. Первая подтверждена официально: Anthropic выпустила Opus 4.7, назвала её первой моделью, на которой тестирует новые cyber safeguards, и пригласила специалистов по безопасности в Cyber Verification Program. Вторая видна по публичным GitHub issue в репозитории Claude Code: уже 17-19 апреля появились жалобы, где блокировки задевают не только offensive security, но и научные задачи, и даже обычную учебную рутину.
Именно поэтому история стала больше, чем спор о границе допустимого. Claude Code продаётся не как чат «на всякий случай», а как платный помощник для длинных инженерных сессий, где важны предсказуемость, согласованность между поверхностями и понятные причины отказа. Когда продукт то помогает, то внезапно упирается в policy message, пользователь перестаёт понимать, где реальный риск, а где просто ложное срабатывание.
Что Anthropic официально изменила 16 апреля
В анонсе Claude Opus 4.7 Anthropic описывает модель как заметный шаг вперёд для сложной software engineering работы: длинные задачи, более аккуратная проверка результата и больший запас автономности. Но рядом с этим компания прямо пишет и вторую часть истории. После запуска Project Glasswing она решила не выводить Mythos-подобные кибервозможности в широкий релиз и сначала тестировать новые cyber safeguards на менее мощных моделях. Opus 4.7 стала первой такой моделью.
Там же Anthropic формулирует механику без особых эвфемизмов: guardrails должны автоматически замечать и блокировать запросы, которые похожи на запрещённое или high-risk использование в кибербезопасности. Для легитимных defensive-сценариев компания предлагает Cyber Verification Program. На уровне compliance это выглядит логично. На уровне ежедневной работы разработчика это означает другое: спорные запросы теперь по умолчанию проходят через более жёсткий фильтр.
Параллельно Anthropic усилила и сам продуктовый слой Claude Code. В день релиза Opus 4.7 компания подняла default effort level до xhigh для всех планов и расширила auto mode на пользователей Max. То есть ассистент для кода стал одновременно более автономным и более чувствительным к потенциально рискованным сценариям. Именно эта комбинация и создаёт напряжение: чем дольше инструмент работает без постоянных подтверждений, тем дороже становится каждый неожиданный стоп-сигнал.
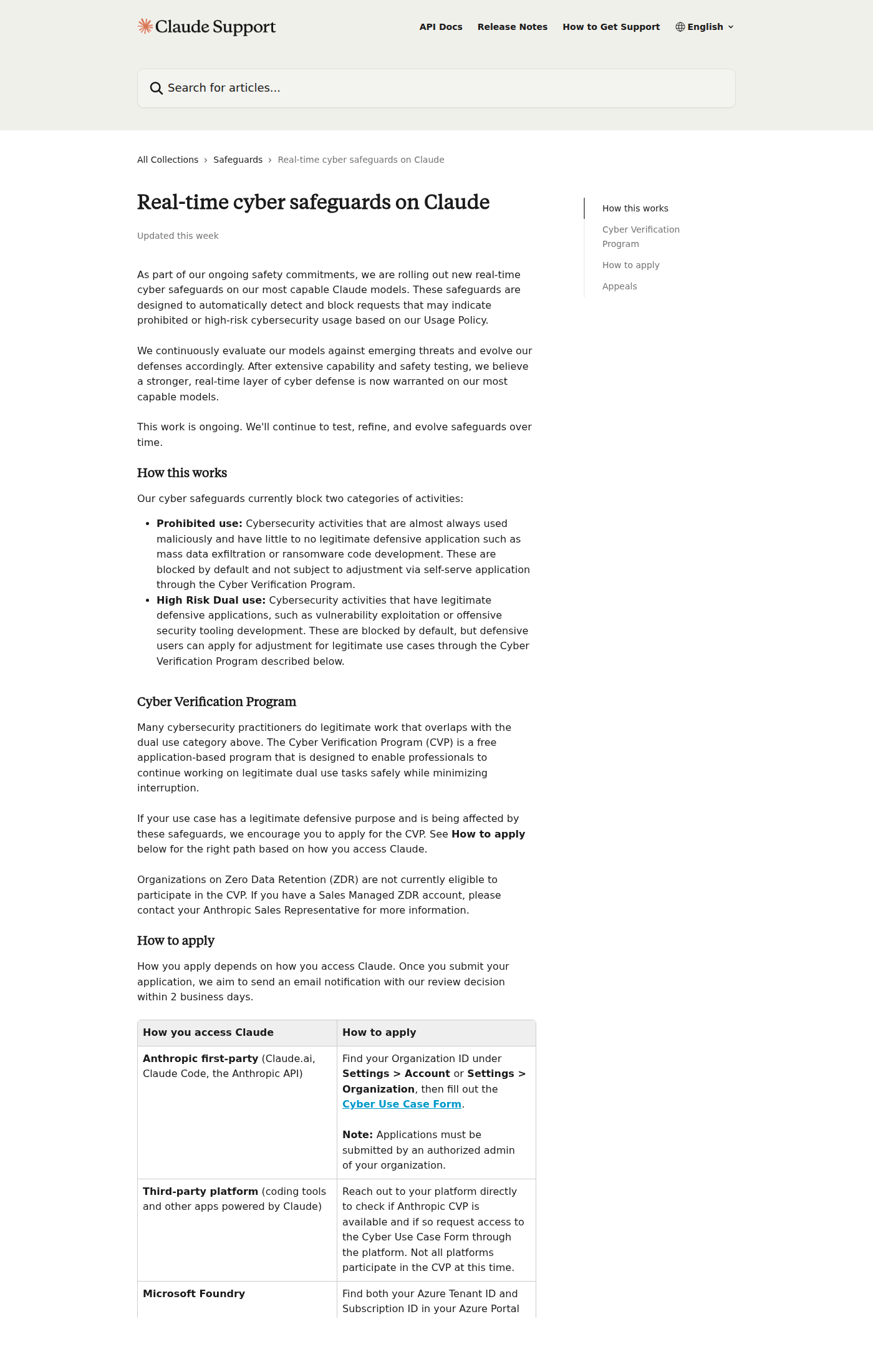
Help Center делает этот контур ещё конкретнее. Anthropic делит блокировки на две категории: outright prohibited use и high-risk dual use. Вторая категория допускает adjustment для защитных кейсов через CVP. Но компания одновременно предупреждает, что даже одобренные пользователи могут продолжать сталкиваться с блокировками на легитимной работе, а approval привязан к конкретному organization ID. Для внутренней безопасности это нормально. Для пользователя, который прыгает между claude.ai, Claude Code и API, это ещё один источник непредсказуемости.
Публичные issue уже показывают, где guardrails ломают сценарий работы
Самый полезный материал здесь даёт не общий новостной шум, а публичный issue tracker Claude Code. Он быстро показывает, что жалобы выходят за пределы простой формулы «ну это мешает только offensive security».
| Issue | Открыта | Сценарий | Что показывает |
|---|---|---|---|
| #49679 | 17 апреля 2026 | Одобренный cyber use case работает в Claude Chat и desktop-клиенте, но Claude Code через API всё равно ловит блокировку. | Проблема не только в policy, но и в переносе approval между поверхностями. |
| #49751 | 17 апреля 2026 | Задача по computational structural biology на публичной PDB-структуре стабильно получает Usage Policy violation в Claude Code и web chat. |
Ложные отказы задевают уже не только security research, но и соседние научные домены. |
| #50916 | 19 апреля 2026 | Даже просьба просто вычитать учебную лабораторную работу по криптографии упирается в policy refusal. | Под удар попадает уже безопасная рутина, которую пользователь ожидает от взрослого рабочего инструмента. |
Важен не только список кейсов, а их рисунок. В issue #49679 автор прямо пишет, что exemption уже работает в claude.ai и desktop-клиенте, но не доезжает до Claude Code через API. В issue #49751 речь идёт о структурной биологии: пользователь описывает работу с опубликованной PDB-структурой, а не offensive tooling. В issue #50916 претензия ещё жёстче: если за $200+ в месяц система отказывается даже от вычитки учебного криптографического материала, проблема уже воспринимается как деградация рабочего продукта, а не как аккуратная защита от злоупотреблений.
Именно здесь ломается доверие. Пользователю мало знать, что у Anthropic есть форма appeal. Ему нужен понятный ответ на три вопроса: что именно было сочтено рискованным, переносится ли approval между поверхностями и можно ли быстро вернуться к нормальной работе без шаманства с моделью, организацией и формулировками промпта.
Почему это уже проблема рабочего опыта, а не только policy
У хорошего coding assistant логика простая: нормальная задача должна проходить предсказуемо, а граница риска должна объясняться конкретно. В текущем контуре Claude Code пользователи видят обратное. Anthropic усиливает агентность, расширяет автономные режимы и делает ставку на длинные сессии, но рядом с этим сам защитный слой остаётся слишком грубым для повседневной инженерной работы.
Наиболее болезненный эффект тут даже не в самом отказе, а в том, как он ломает поток работы. В материале про workflow Бориса Черни Claude Code выглядит как инструмент для параллельных сессий, длинных цепочек правок и постоянной проверки результата. В таком режиме случайный refusal раздражает не как единичная ошибка ответа, а как обрыв рабочего состояния. Модель уже успела принять часть решений, прочитать контекст, возможно, использовать инструменты, а затем внезапно перестаёт быть доступной для продолжения той же задачи.
Отсюда и главный продуктовый конфликт. Guardrails в духе «лучше заблокировать лишнее, чем пропустить опасное» легко защищать на уровне policy. Но DX сильного ассистента для кода строится на другой интуиции: система должна помогать в нормальной задаче и точно объяснять границу только там, где риск действительно высок. Чем ближе продукт к автономной работе, тем дороже каждый ложный стоп-сигнал.
Postmortem по качеству не объясняет guardrails, но усиливает недоверие
23 апреля Anthropic выпустила отдельный postmortem по жалобам на качество Claude Code. Его нельзя использовать как доказательство бага именно в cyber safeguards, и сама компания такого не говорит. Наоборот, в постмортеме она прямо пишет, что API не был затронут, а расследование касалось Claude Code, Claude Agent SDK и Claude Cowork как продуктового слоя. Но для пользователя это всё равно часть одной неприятной истории.
Anthropic перечисляет три отдельные причины деградации качества:
- 4 марта default reasoning effort в Claude Code переключили с
highнаmedium, а 7 апреля откатили решение. - 26 марта в оптимизации очистки старого thinking history появился баг, из-за которого модель становилась забывчивой и повторяющейся; фикс вышел 10 апреля.
- 16 апреля в системный промпт добавили инструкцию на снижение многословности, которая ухудшила coding quality; её откатили 20 апреля.

Формально это другой класс проблем, чем false positives в safeguards. Практически пользователь видит одну и ту же картину: в те же недели, когда Anthropic усиливала защитный слой вокруг Opus 4.7, сам Claude Code уже успел стать менее надёжным по продуктовым причинам. Компания пишет, что все три issues были resolved к 20 апреля и что 23 апреля она сбрасывает usage limits всем подписчикам. Это хороший жест. Но он не отменяет ключевого вопроса: может ли инструмент одновременно становиться более автономным, более жёстким по policy и при этом не терять доверие разработчиков.
Что Anthropic придётся чинить дальше
У этой истории нет простого решения в духе «просто уберите guardrails». После Glasswing и общего ужесточения вокруг кибермоделей Anthropic вряд ли пойдёт в сторону более слабого защитного контура. Значит, исправлять придётся не сам факт ограничений, а качество их работы и способ коммуникации с пользователем.
- Легитимные security- и research-сценарии не должны цепляться за те же эвристики, что и явно вредоносные запросы.
- Если отказ всё же случился, система должна объяснять класс проблемы достаточно конкретно, чтобы пользователь мог понять, это policy boundary или поломка согласованности между поверхностями.
- Approval по Cyber Verification Program должен вести себя одинаково в Claude Chat, Claude Code и API-сценариях Anthropic first-party.
- Product regressions и safety refusals нужно разводить в коммуникации так, чтобы разработчику не приходилось самому быть детективом.
Пока этого нет, новость про Claude Code guardrails читается не как доказательство зрелой safety-политики, а как предупреждение для всего рынка AI coding tools. Frontier-модель можно сделать сильнее на бумаге и одновременно слабее в реальной работе. Для Anthropic это уже не спор «безопасность против свободы». Это проверка на то, сможет ли компания удержать доверие разработчиков, когда защитный слой начинает ломать саму механику повседневного использования.
Источники
- Anthropic: Introducing Claude Opus 4.7, опубликовано 16 апреля 2026 года, проверено 26 апреля 2026 года.
- Claude Help Center: Real-time cyber safeguards on Claude, проверено 26 апреля 2026 года.
- Anthropic Engineering: An update on recent Claude Code quality reports, опубликовано 23 апреля 2026 года, проверено 26 апреля 2026 года.
- GitHub issue #49679, открыта 17 апреля 2026 года, проверено 26 апреля 2026 года.
- GitHub issue #49751, открыта 17 апреля 2026 года, проверено 26 апреля 2026 года.
- GitHub issue #50916, открыта 19 апреля 2026 года, проверено 26 апреля 2026 года.