Source map Claude Code: что видно в архитектуре CLI
Habr разобрал source map Claude Code v2.1.88. Мы отделяем мифы от инженерных выводов: agent loop, context compression, tool use, permissions и субагенты.

По состоянию на 5 июня 2026 года ценность истории с source map Claude Code не в пафосе «слива исходников», а в возможности посмотреть на архитектуру агентного CLI без рекламной обёртки. На Habr вышел разбор npm-пакета Claude Code v2.1.88: автор пишет, что в релиз попал source map, через который восстановилась читаемая структура клиента.
Source map - это отладочный артефакт, который связывает собранный JavaScript-бандл с исходными файлами. Он не равен официальной архитектурной документации Anthropic и не делает частный разбор спецификацией продукта. Зато по нему можно увидеть, какие инженерные решения лежат за привычным интерфейсом: как агент крутит цикл, что происходит при сжатии контекста, когда запускаются инструменты и почему permissions в таких системах сложнее простой цепочки «разрешить или спросить».
Ниже - не пересказ всех находок Habr. Мы берём главное для разработчиков AI-агентов и команд, которые строят CLI-инструменты с доступом к файлам, терминалу, MCP и субагентам. Внутренние детали из source map атрибутируем исходному разбору; публичные механизмы Claude Code сверяем с официальными docs Anthropic.
| Миф | Что видно в разборе source map | Практический вывод |
|---|---|---|
| Агент рекурсивно вызывает сам себя | Автор Habr указывает на итеративный queryLoop с изменяемым состоянием. |
Бюджеты, таймауты и лимиты ходов стоит считать как проходы длинного цикла, а не как глубину рекурсии. |
| Контекст просто обрезается | В разборе описана цепочка механизмов сжатия от лёгких чисток до полного autocompact. | Потеря деталей после сжатия - нормальный риск, который нужно учитывать в агентных workflow. |
| Инструменты запускаются после финального ответа | В Habr-разборе tool_use стартует во время стрима, до полного завершения текста модели. |
Отмена, параллельность и журнал действий должны проектироваться как часть стриминга, а не как постобработка. |
| Permissions - это только порядок user/project/local | Публичные docs Anthropic описывают deny/ask/allow-правила и режимы permissions; Habr делает акцент на строгих блокировках. | Запреты и защищённые зоны должны побеждать удобные режимы, иначе агент сможет ослабить собственные ограничения. |
| Субагент - просто второй чат рядом | Официальная документация описывает отдельный контекст, ограничения инструментов и permission modes для субагентов. | Делегирование экономит основной контекст, но задачи с подтверждениями и правами доступа нужно выдавать осторожно. |
Что именно произошло с source map Claude Code
В исходном материале речь идёт о версии Claude Code v2.1.88. Автор Habr утверждает, что в npm-релиз попал source map, а через него восстановилось около 1884 файлов в src/. Эта оговорка важна: статья разбирает клиентскую структуру и имена механизмов, но не заменяет документацию Anthropic и не даёт права публиковать внутренние промпты или фрагменты кода.
Для Toolarium здесь интересен не сам факт «нашли исходники». Гораздо полезнее разобрать, какие компромиссы видны в устройстве агентного CLI. Claude Code должен вести долгую сессию, читать и менять файлы, запускать инструменты, держать контекст, передавать работу субагентам, подключаться к MCP и при этом не давать проекту молча переписать собственные правила безопасности.
Официальные docs Anthropic подтверждают публичную сторону этой картины: Claude Code настраивается через settings-файлы, поддерживает permission rules, hooks, MCP-серверы, skills, plugins и custom subagents. Но часть чисел из Habr - например конкретные константы сжатия или детали порядка выполнения - остаётся наблюдением по версии 2.1.88. В июне 2026 документация уже упоминает более поздние версии и изменения поведения, поэтому переносить каждую находку на текущий Claude Code без проверки нельзя.
queryLoop вместо рекурсивного агента
Первый полезный вывод из Habr-разбора: агентный цикл в Claude Code описан как итеративный queryLoop. Популярная схема «модель ответила - инструмент выполнился - агент снова вызвал сам себя» слишком упрощает происходящее. Для пользователя разница почти незаметна. Для разработчика агентной системы она принципиальна.
Если ядро - длинный цикл с состоянием, то «ход» агента становится единицей управления. На нём висят лимиты, таймауты, отмена, учёт tool use и решение, продолжать ли сессию. Ошибка в одном месте не обязательно взрывает стек, но может испортить состояние следующего прохода. Поэтому отладка агентного CLI больше похожа на отладку event loop, чем на анализ красивой рекурсивной схемы из презентации.
Отсюда практическое правило для своих агентов: храните состояние явно, логируйте переходы между ходами и не прячьте бюджет внутрь «магического» вызова модели. Если агент умеет работать часами, нужно видеть, что изменилось между шагами: какие файлы прочитаны, какие инструменты запускались, какой контекст был отброшен и что модель считает следующей целью.
Сжатие контекста не равно аккуратной памяти
Самый болезненный блок - контекст. Habr-разбор описывает несколько механизмов, которые включаются не одновременно: лёгкое удаление старых результатов инструментов, частичные режимы, collapse и полный autocompact. По словам автора, autocompact оставляет буфер в 13 000 токенов и после трёх неудачных попыток может отключиться до конца сессии.
Эти цифры нужно читать как данные конкретного разбора v2.1.88, а не как вечную спецификацию. Но сам вывод устойчивый: сжатие контекста - это не «память всё помнит, только короче». При полном сжатии модель может работать уже не с последними сообщениями в исходном виде, а с пересказом, который был создан другим модельным вызовом.
Мы уже разбирали эту проблему отдельно в материале почему context compression ломает AI coding agents. Для разработчика вывод простой: если важная деталь должна пережить сжатие, её нельзя оставлять только в чате. Её нужно закрепить в файле, задаче, журнале, тесте или другом внешнем артефакте.
tool_use стартует раньше, чем кажется
Habr-разбор подчёркивает неприятную для UX деталь: инструмент может уйти в работу во время потокового ответа, когда модель ещё продолжает генерировать текст. Если пользователь видит фразу на экране и думает, что действие начнётся только после «готово», он может ошибиться. В агентном CLI вызов инструмента - это событие стрима, а не финальная кнопка после сообщения.
Из этого вытекают два требования. Первое - отмена должна быть быстрой и понятной. Если tool use уже стартовал, интерфейс обязан честно показывать, что именно выполняется и что успело измениться. Второе - параллельные инструменты нельзя считать независимыми только потому, что команды выглядят независимыми. Habr описывает сценарий, где падение одного вызова отменяет соседние, но весь ход при этом не обрывается.
Отдельный урок касается stop_reason. В исходном разборе цикл не полагается на финальное значение stop_reason, чтобы понять, был ли вызов инструмента; он смотрит на сам факт блока tool_use. Для разработчиков обёрток над LLM API это хороший антипример: если событие приходит в стриме, нельзя проектировать логику так, будто все истины появятся только в последнем объекте ответа.
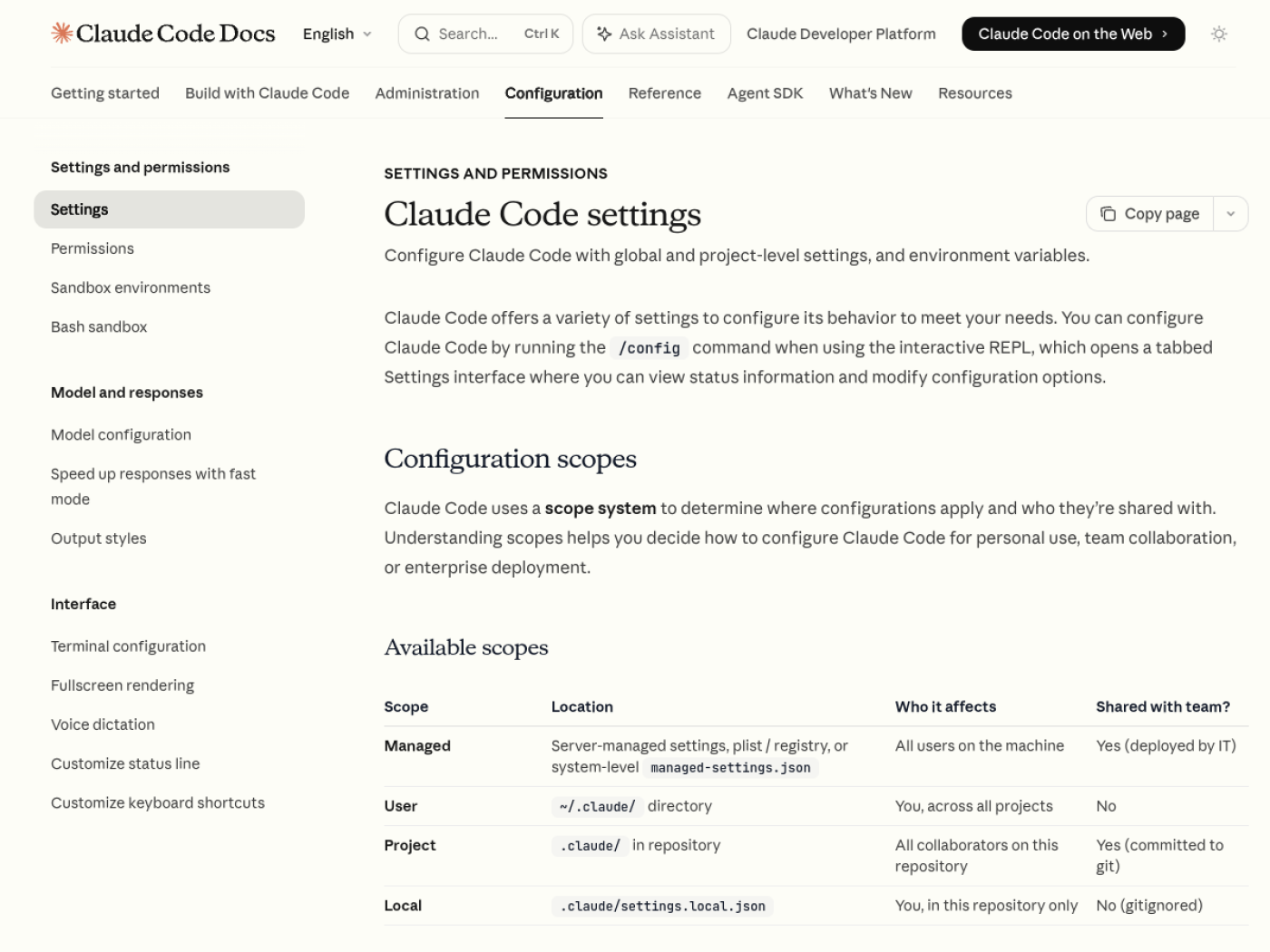
Permissions сильнее удобного режима
Публичная документация Claude Code описывает permission rule syntax как порядок deny, ask, allow: сначала проверяются запреты, затем запросы подтверждения, затем разрешения. В settings также есть режимы вроде acceptEdits, auto, dontAsk и bypassPermissions. По состоянию на текущие docs, auto игнорируется в проектных и local settings начиная с Claude Code v2.1.142, чтобы репозиторий не мог сам включить себе более свободный режим.
На фоне Habr-разбора v2.1.88 это важное обновление. Даже если внутренние детали меняются от версии к версии, направление видно: проектные настройки нельзя воспринимать как полностью доверенный источник. Агент, который читает .claude/settings.json из текущей папки, должен понимать, что эта папка ещё может быть недоверенной.
Habr отдельно указывает на риск чтения .claude/settings.json до trust-вопроса. Мы не можем независимо подтвердить порядок выполнения без исходного кода, но как класс риска он реален для любого агентного CLI: конфигурация из репозитория может повлиять на поведение агента раньше, чем пользователь осознал, что доверяет этому репозиторию. Поэтому чувствительные режимы должны дополнительно проверять trust-флаг, а deny-правила и защищённые директории должны побеждать shortcuts.
Для команд это не теория. В материале про MCP как стандарт интеграции ИИ с инструментами мы уже писали, что подключение внешних инструментов превращает ответ модели в действие. Permissions - это слой, который отделяет «модель предложила» от «агент сделал».
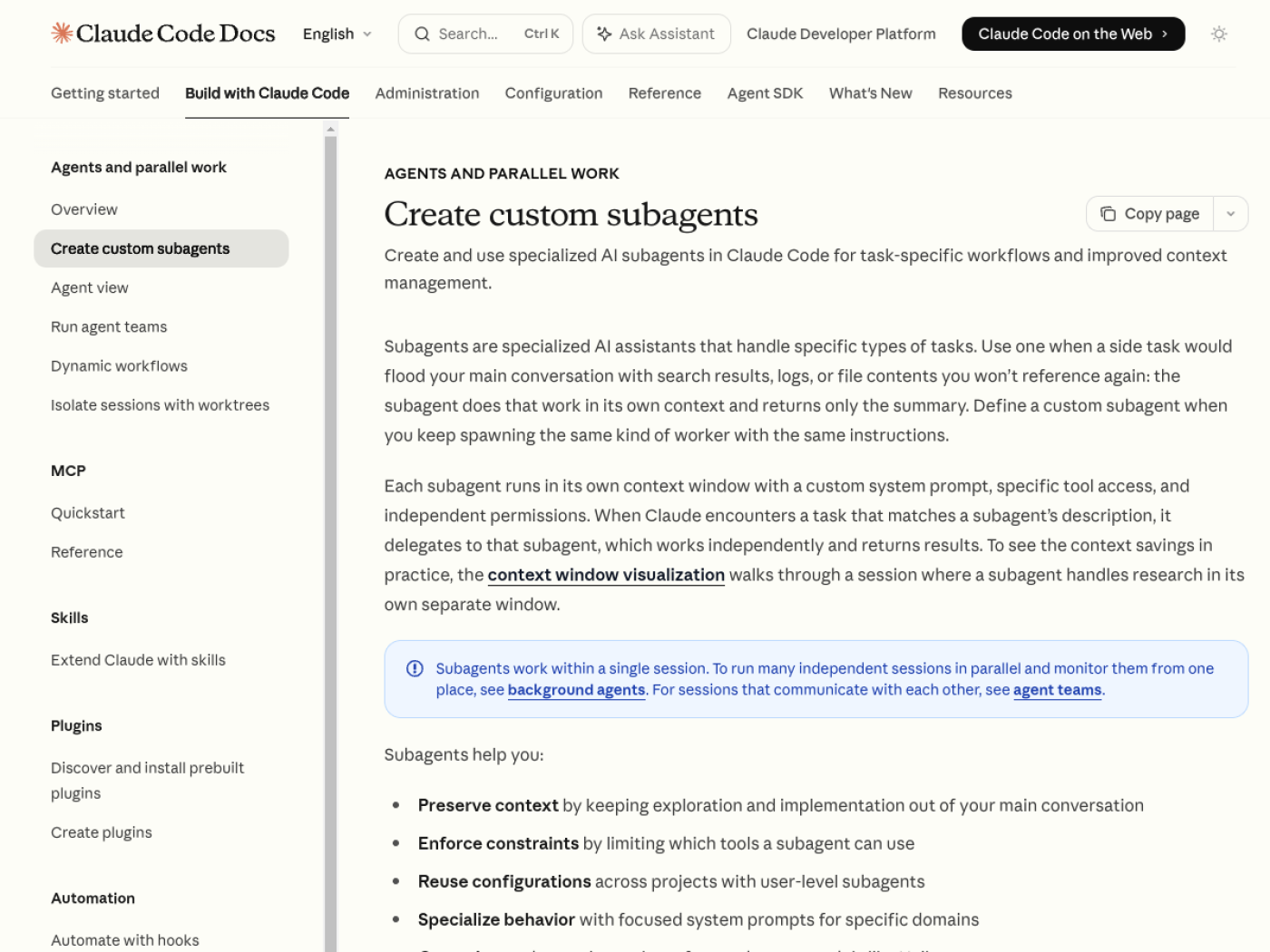
Субагенты и расширения: экономия контекста с ограничениями
Официальные docs Anthropic описывают custom subagents как отдельные AI-помощники с собственным контекстом, prompt, tool access и permission modes. Субагент может помочь, когда побочная задача засорила бы основной диалог результатами поиска, логами или длинными файлами. Делегирование всё равно требует узких прав, понятной области работы и нормального журнала действий.
В документации есть важная граница: subagents cannot spawn other subagents. Есть также подробности про набор инструментов, MCP-серверы и permission modes. Например, для субагента можно ограничить инструменты allowlist-ом или denylist-ом, а MCP-серверы можно подключать отдельно к конкретному агенту. Это похоже на нормальную инженерную модель: делегирование полезно, когда контур прав уже спроектирован.
Расширения Claude Code тоже устроены шире, чем «несколько хуков». Публичные docs подтверждают MCP, hooks, skills и plugins как отдельные механизмы. MCP подключает внешние инструменты и данные, hooks позволяют перехватывать события, skills добавляют специализированные инструкции, plugins упаковывают компоненты в общий дистрибутив.
Habr-разбор добавляет к этому низкоуровневые детали по hook exit codes и пространству имён MCP-инструментов. Официальные hooks docs подтверждают важный принцип: для большинства событий блокирующим считается exit code 2, а exit code 1 обычно не останавливает действие. Для policy hook это критично: привычная Unix-единица может дать мягкую ошибку вместо запрета.
Рядом находится тема AI-first QA на MCP, CLI и субагентах. Чем больше проверок уходит в CLI и agent workflow, тем важнее различать фонового помощника, hook-политику и инструмент с реальными правами на файловую систему.
Что это меняет для разработчиков агентных CLI
Source map Claude Code полезен не тем, что даёт готовый рецепт. Скорее наоборот: он показывает, сколько инженерной работы скрыто за интерфейсом «просто попроси агента». Долгий цикл, сжатие контекста, потоковый tool use, permissions, trust, субагенты, hooks и MCP - это отдельные подсистемы, и каждая может сломать пользовательское ожидание.
Если вы строите своего coding agent или внутренний CLI-ассистент, минимальный набор правил выглядит так:
- Логируйте проходы агентного цикла, а не только финальные ответы модели.
- Сохраняйте критичные решения вне контекста чата: в файлах, задачах, тестах или журналах.
- Показывайте tool use как событие в реальном времени, включая отмену и фактические изменения.
- Ставьте deny-правила и защищённые директории выше удобных режимов автоподтверждения.
- Не доверяйте проектной конфигурации до явного trust-сигнала.
- Выдавайте субагентам узкие инструменты и понятную область работы, особенно если они запускаются в фоне.
- Тестируйте hooks на реальные exit codes, а не на интуицию из Unix.
Главный вывод не в том, что Claude Code устроен «плохо» или «хорошо». Внутри видны нормальные следы продукта, который пытается совместить автономность, скорость и безопасность. Полезный урок для рынка в другом: агентный CLI нельзя проектировать как чат с несколькими tools. Это runtime для действий, и у него должны быть свои правила наблюдаемости, прав доступа и восстановления после ошибок.
FAQ
Что такое source map Claude Code?
В этом контексте source map Claude Code - отладочный артефакт npm-пакета Claude Code v2.1.88, по которому, согласно Habr-разбору, восстановили читаемую структуру части клиентского кода. Официальным архитектурным документом Anthropic он не становится.
Был ли это взлом Claude Code?
В доступных источниках нет признаков взлома. Habr описывает ситуацию как попадание source map в npm-релиз. Корректнее говорить о debug-артефакте в пакете, а не о компрометации систем Anthropic.
Можно ли считать найденные детали актуальными для всех версий Claude Code?
Нет. Разбор относится к v2.1.88, а официальная документация Anthropic уже описывает поведение более поздних версий. Такие находки полезны как инженерные наблюдения, но каждую деталь нужно перепроверять на текущей версии.
Что разработчикам AI-агентов стоит вынести из этой истории?
Агентный CLI нужно проектировать как систему действий: с явным циклом, логами, контролем контекста, правами доступа, проверкой trust и понятной моделью субагентов. Красивая оболочка чата не заменяет эти механизмы.
Читайте также
- Почему context compression ломает AI coding agents
- AI-first QA на MCP: почему тестирование уходит в CLI и субагенты
- MCP: как работает стандарт интеграции ИИ с инструментами
Источники и проверка фактов
- Habr: разбор source map Claude Code v2.1.88, опубликовано 5 июня 2026 года, использовано для деталей по v2.1.88,
queryLoop, сжатию контекста, tool use, hooks и trust-наблюдениям; проверено 5 июня 2026 года. - Anthropic Claude Code Docs: Configuration, использовано для текущих сведений о settings, permission rule syntax, режимах permissions, hooks settings, MCP/settings и системном prompt; проверено 5 июня 2026 года.
- Anthropic Claude Code Docs: Create custom subagents, использовано для публичных сведений о custom subagents, tool access, MCP servers, permission modes и ограничении на порождение субагентов; проверено 5 июня 2026 года.
- Anthropic Claude Code Docs: Hooks reference, использовано для проверки поведения exit code 2 и non-blocking ошибок hooks; проверено 5 июня 2026 года.
- Anthropic Claude Code Docs: MCP, использовано для описания MCP как подключения внешних инструментов и данных к Claude Code; проверено 5 июня 2026 года.
- Anthropic Claude Code Docs: Skills и Plugins, использовано для публичной проверки механик skills/plugins; проверено 5 июня 2026 года.