Voxtral TTS: Mistral выпустила модель синтеза речи с клонированием голоса
Mistral AI выпустила Voxtral TTS — первую модель синтеза речи с клонированием голоса из 3-секундной записи. 4 миллиарда параметров, 9 языков, открытые веса.
Французский стартап Mistral AI 22 марта 2026 года выпустил Voxtral TTS, свою первую модель синтеза речи. Модель весит 4 миллиарда параметров, клонирует голос по трёхсекундной записи и поддерживает девять языков. Веса выложены на Hugging Face, а через API генерация речи стоит $0,016 на тысячу символов.
Что умеет Voxtral TTS
Voxtral TTS генерирует эмоционально окрашенную речь на девяти языках: английском, французском, немецком, испанском, нидерландском, португальском, итальянском, хинди и арабском. Модель разбирает контекст и подбирает интонацию, будь то нейтральная подача, радость или ирония.
Для подстройки под конкретный голос хватает записи от 3 секунд (рекомендуемая длина 5–25 секунд). Модель копирует тембр, манеру речи, паузы, ритм, эмоциональные нюансы и даже характерные запинки.
Отдельно стоит упомянуть кросс-лингвальный режим без дообучения. Если подать французский голосовой образец и английский текст, на выходе будет английская речь с естественным французским акцентом. Полезно для каскадных систем голосового перевода: распознать речь, перевести текст, озвучить результат голосом исходного спикера.
Для полного голосового стека этот релиз удобнее читать вместе с обзором Whisper, TTS и голосового ИИ и практическим гайдом по тому, как работает Whisper OpenAI в реальных сценариях.
Бенчмарки: Voxtral против ElevenLabs
Автоматические метрики плохо оценивают естественность синтезированной речи, поэтому Mistral провела слепое сравнение с носителями языка. По два узнаваемых голоса для каждого из девяти языков, три аннотатора на каждую пару. Оценка шла по трём критериям: естественность, соответствие акценту и сходство с оригинальным голосом.
По данным на март 2026 года: Voxtral TTS обходит ElevenLabs Flash v2.5 по естественности при сопоставимой задержке до первого аудиофрагмента (Time-to-First-Audio). В режиме zero-shot с пользовательскими голосами разрыв заметнее, модель Mistral выигрывает по всем трём параметрам.
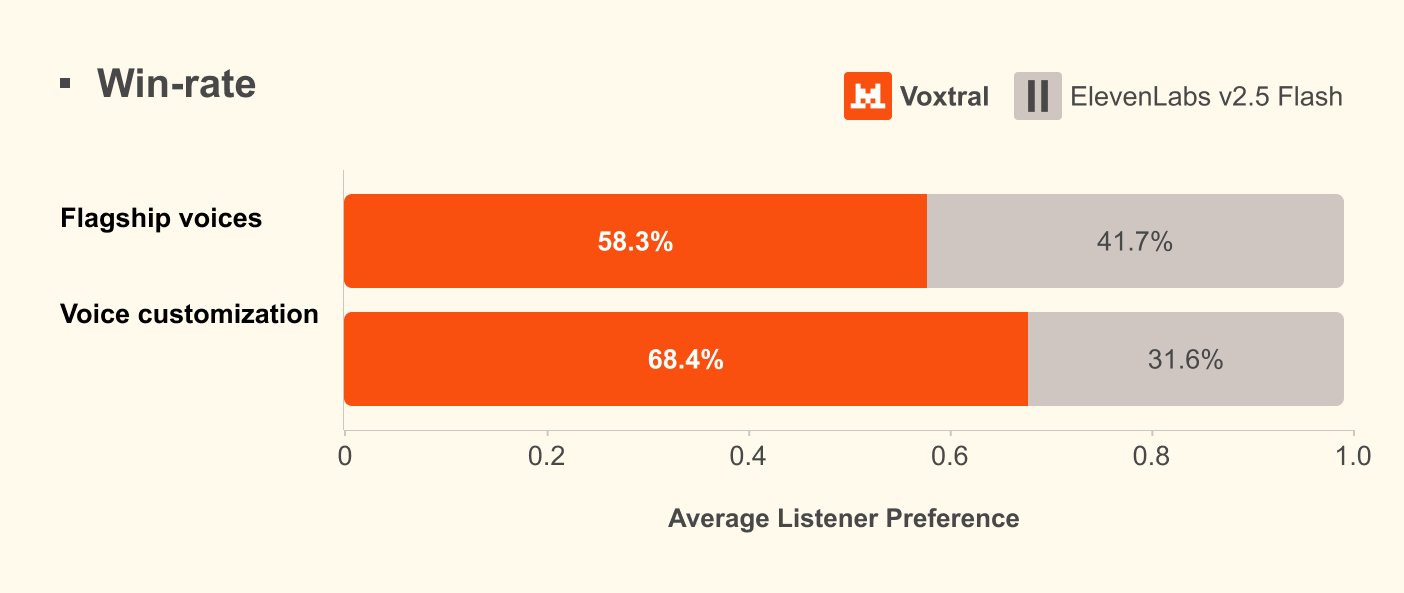
С ElevenLabs v3 (более новая модель) Voxtral показывает примерный паритет по качеству и при этом поддерживает эмоциональную стилизацию (emotion-steering).
Архитектура: 4 миллиарда параметров в трёх блоках
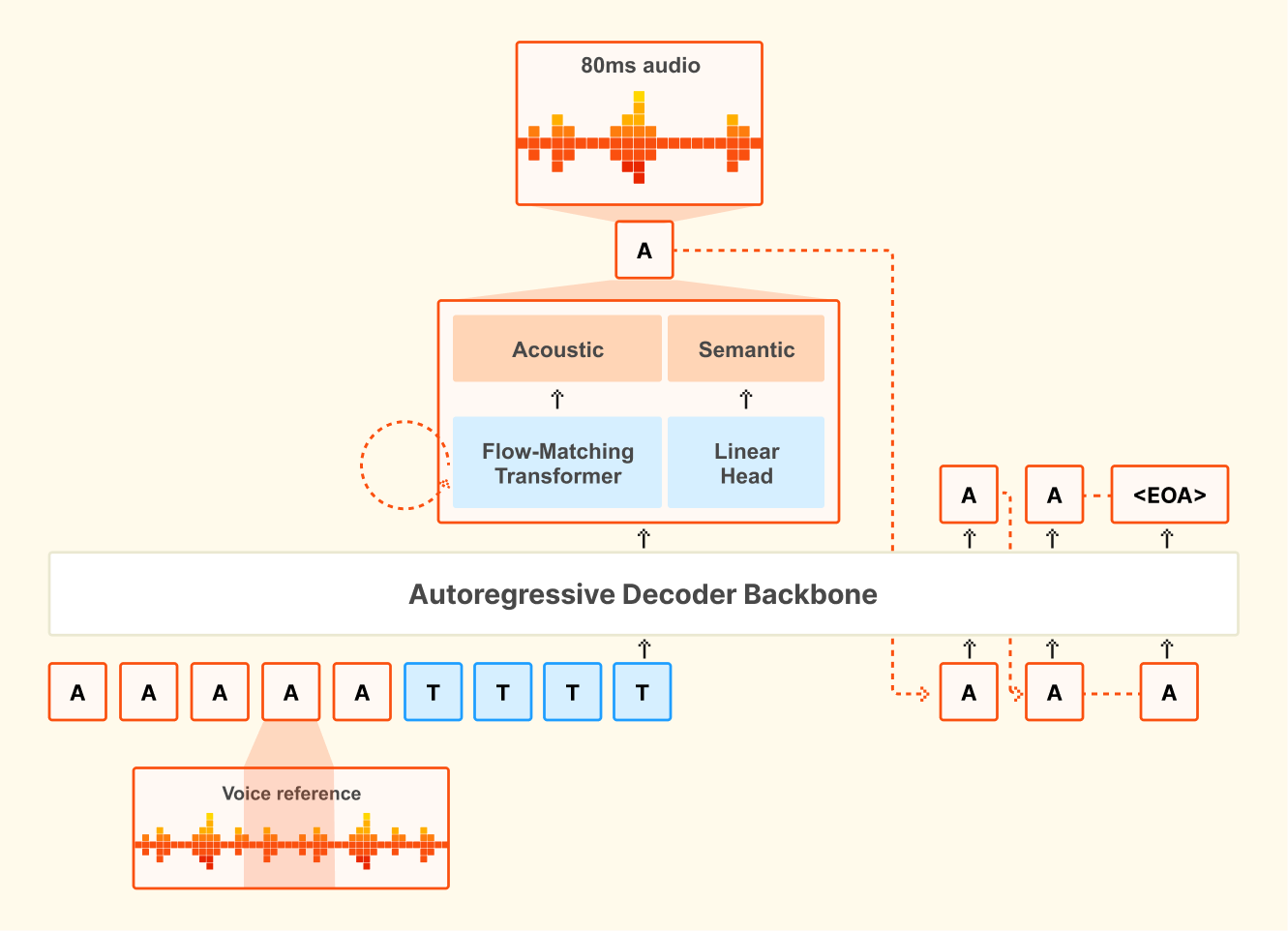
Voxtral TTS построена поверх языковой модели Ministral 3B. Это авторегрессионная трансформерная архитектура с flow-matching. Четыре миллиарда параметров распределены между тремя компонентами:
- 3,4 млрд: трансформер-декодер, основной backbone модели
- 390 млн: акустический трансформер с flow-matching
- 300 млн: нейронный аудиокодек (симметричный энкодер-декодер)
Для каждого аудиокадра декодер предсказывает семантический токен, а flow-matching трансформер за 16 шагов (NFE) превращает его в акустический латент. Собственный кодек Mistral работает на частоте 12,5 Гц и использует семантический VQ-словарь на 8192 токена плюс акустический FSQ (36 измерений, 21 уровень).
Задержка модели составляет 70 мс при типичном вводе (10-секундный голосовой образец, 500 символов текста). Коэффициент реального времени (RTF) около 9,7×, то есть секунда вычислений даёт почти 10 секунд аудио. За один проход модель генерирует до двух минут звука, а API обрабатывает тексты любой длины через интеллектуальное чередование блоков.
Цены и способы доступа
На март 2026 года Voxtral TTS доступна тремя путями:
- Mistral API: $0,016 за 1000 символов, с потоковой генерацией
- Mistral Studio: тестирование с готовыми голосами или записью собственного
- Le Chat: голосовой режим в веб- и мобильном приложении Mistral
Открытые веса выложены на Hugging Face под лицензией CC BY-NC 4.0. Модель можно скачать и запустить локально для исследований и некоммерческих проектов. Коммерческое использование требует API-подписки или отдельного соглашения с Mistral.
Модели распознавания речи Voxtral Transcribe от той же компании стоят от $0,003 за минуту и идут под Apache 2.0, без ограничений на коммерцию. TTS-версия лицензирована строже, хотя веса и открыты.
Кому пригодится Voxtral TTS
С выходом Voxtral TTS у Mistral сложился полный голосовой конвейер: распознавание речи (Voxtral Transcribe), обработка текста (Mistral LLM), синтез речи (Voxtral TTS). Три звена от одного вендора, единый API.
Где это применимо:
- Голосовые агенты для клиентской поддержки с нужной интонацией и брендовым голосом
- Озвучка контента на нескольких языках без записи студийного аудио
- Каскадный голосовой перевод с сохранением акцента и манеры речи оригинала
- Прототипирование голосовых интерфейсов через Mistral Studio бесплатно
Для крупных клиентов Mistral готова развернуть модель на их инфраструктуре, подстроить через fine-tuning и добавить идентификацию спикеров, определение эмоций и диаризацию. Эти возможности пока на стадии дизайн-партнёрства.
Итого
Voxtral TTS конкурирует с ElevenLabs при вдвое меньшей цене и с открытыми весами. Ограничение: некоммерческая лицензия CC BY-NC 4.0 не позволяет скачать модель и встроить в продукт без договорённости. Для продакшена придётся платить за API или заключать отдельный контракт.
Если строите голосовые приложения и хотите разобраться в теме глубже, читайте наше сравнение голосовых ИИ-инструментов в 2026 году. А чтобы понять, как устроены языковые модели, на которых строится Voxtral, начните со статьи о больших языковых моделях.