Stable Audio 3: зачем открытые веса в генерации аудио
Stability AI выпустила Stable Audio 3 с открытыми весами для Small и Medium. Разбираем модели, лицензии, локальный запуск и риски.

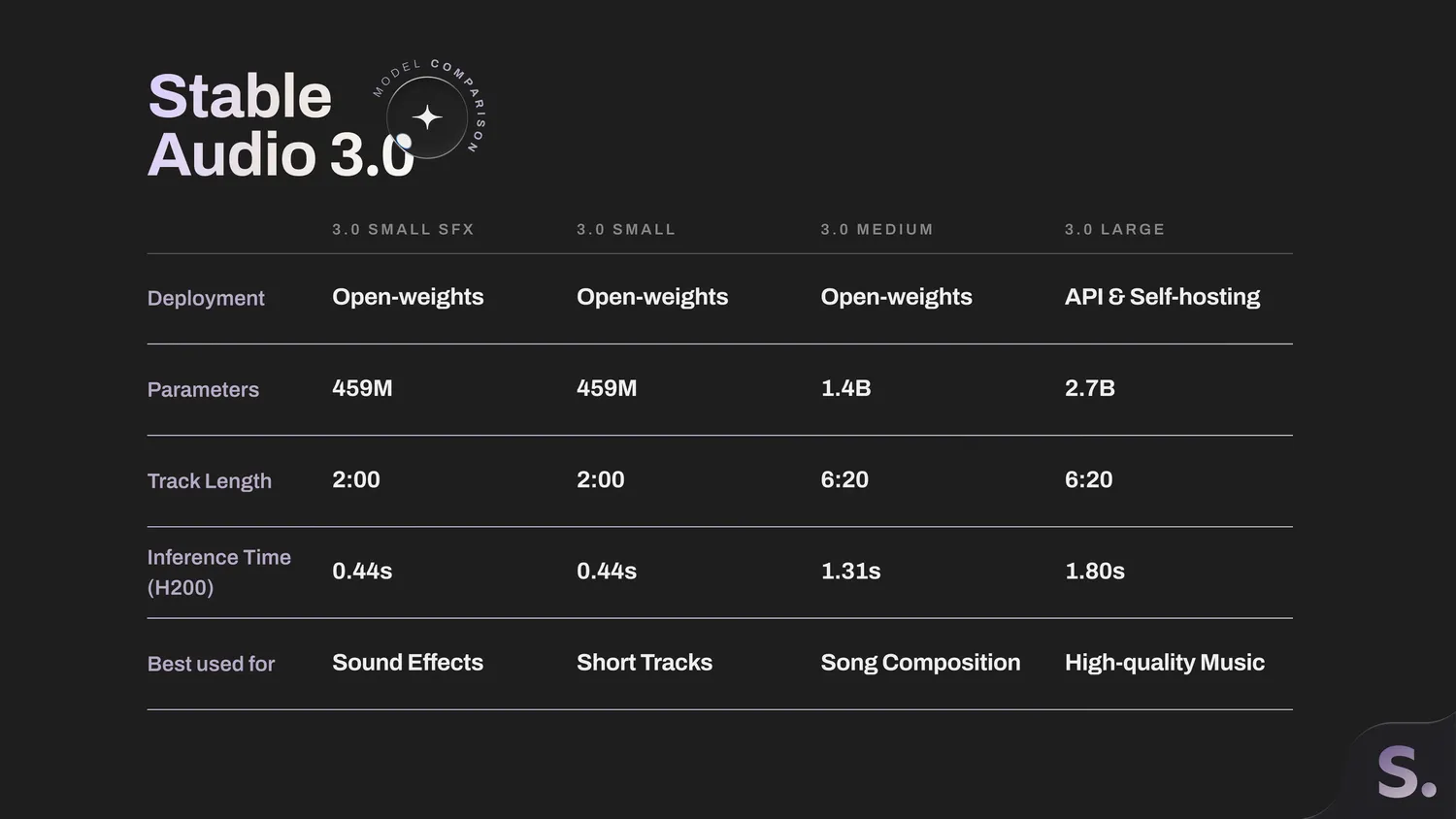
По состоянию на 27 мая 2026 года Stable Audio 3 выглядит как главный аудиорелиз Stability AI за последние месяцы. Компания выпустила семейство моделей для генерации и редактирования музыки и звуков: Small SFX, Small и Medium доступны с открытыми весами, а Large остаётся вариантом для API и корпоративного self-hosting.
Главная ставка релиза — перенос в аудио той же механики, которая когда-то помогла Stable Diffusion стать площадкой для экспериментов, локальных сборок и дообучений. Рынок «нейросетей для музыки» уже занят Suno, Udio, Lyria и десятками сервисов, а у Toolarium есть отдельный обзор нейросетей для музыки. Stable Audio 3 интересен как попытка дать разработчикам не только веб-интерфейс, но и скачиваемые модели.
Сразу важная оговорка: открытые веса не равны полноценному open source. Код inference-пакета выложен на GitHub под MIT, но модели распространяются по Stability AI Community License, с отдельными условиями для компаний с выручкой выше $1 млн в год. Поэтому корректная формулировка здесь — open-weight генерация аудио, а не «полностью открытая нейросеть для музыки».
Что выпустила Stability AI
Официальный анонс Stable Audio 3.0 вышел 20 мая 2026 года. В семействе четыре модели: две малые версии для коротких задач и локального запуска, Medium для более длинных композиций и Large для платформ, которым нужен управляемый API или корпоративное развёртывание.
| Модель | Доступ | Максимальная длина | Основной сценарий |
|---|---|---|---|
| Stable Audio 3.0 Small SFX | открытые веса | до 2:00 | звуковые эффекты, короткие аудиофрагменты, запуск на потребительских устройствах |
| Stable Audio 3.0 Small | открытые веса | до 2:00 | короткие музыкальные треки и эксперименты без обязательного облачного API |
| Stable Audio 3.0 Medium | открытые веса | до 6:20 | длинные треки, более сложная музыкальная структура, CUDA-инференс |
| Stable Audio 3.0 Large | API и self-hosting для enterprise | до 6:20 | платформы и творческие продукты с большим объёмом генераций |
Данные в таблице сверены с официальным анонсом Stability AI и README репозитория stable-audio-3; проверка проведена 27 мая 2026 года.
В отличие от закрытых музыкальных API, здесь часть моделей можно скачать и запускать в собственной среде. Stable Audio 3 не станет универсальной заменой Suno или Udio: у закрытых сервисов сильнее готовый потребительский опыт, социальные функции, библиотека пресетов и быстрый путь от идеи до готового трека. Зато открытые веса дают то, чего обычно не хватает продуктовым и исследовательским командам: контроль над inference-цепочкой, возможность тестировать дообучение и шанс встроить генерацию аудио в собственный инструмент без полной зависимости от внешнего сервиса.
Почему открытые веса важны именно в аудио
Для текста и изображений открытые веса уже стали нормальной частью рынка. В аудио всё сложнее. Музыкальные данные чувствительны юридически, качество длинной композиции труднее оценивать, а пользователь ждёт не просто «похожий звук», а структуру, развитие, ритм и пригодность для монтажа.
На этом фоне Stable Audio 3 занимает промежуточную позицию между закрытым API и исследовательским прототипом. Если Google Lyria 3 Pro интересна как управляемый API для генерации музыки, то Stable Audio 3 делает ставку на скачиваемые веса и локальные сценарии. Для разработчика это другой тип свободы: можно измерять задержку на своём железе, собирать собственный интерфейс, комбинировать модель с пайплайном монтажа и не ждать, пока вендор добавит нужную кнопку.
Такой подход особенно важен для игровых студий, инструментов для видеомонтажа, аудиоредакторов и команд, которые делают генеративные интерфейсы. Им часто нужен не готовый трек «как в музыкальном сервисе», а управляемый кусок аудио: эффект для сцены, продолжение фрагмента, новая партия барабанов, короткая заставка, вариант под другой темп.
В этом смысле Stable Audio 3 ближе к инженерному строительному блоку, чем к массовому музыкальному приложению. Решение «скачать веса или идти в API» всё равно зависит от команды, бюджета и юридических требований. Подробно такую развилку мы разбирали в материале про открытые модели и закрытые API.
Как устроена Stable Audio 3
Техническая часть релиза строится вокруг latent diffusion, но не в лоб по исходной аудиоволне. В README репозитория Stability AI описывает Semantic-Acoustic Music Encoder: он сжимает stereo-аудио 44,1 кГц в компактное латентное представление, а затем декодер восстанавливает звук обратно. На схеме указано 4096-кратное downsampling/upsampling и 256-мерные латенты.

Такой слой нужен не только для экономии вычислений. Он позволяет работать с переменной длиной: модель не обязана каждый раз считать полный длинный трек, если пользователю нужен пятисекундный эффект. В официальном анонсе Stability AI отдельно выделяет генерацию с точностью до секунды, продолжение аудио и inpainting, то есть замену выбранного фрагмента внутри уже существующей дорожки.
Практически это важнее, чем красивые промпты. Для продукта нужны операции редактирования: заменить неудачный участок, продлить трек после исходной концовки, сделать несколько несмежных правок за один проход, сохранить часть исходного материала. В GitHub README для stable-audio-3 эти режимы перечислены как text-to-audio, audio-to-audio editing и inpainting/continuation.
У Stable Audio 3 есть чёткая граница: это не TTS и не модель для синтеза речи. Фокус релиза — музыка, звуковые эффекты и редактирование аудио. Если в задаче нужен голосовой ассистент, озвучка текста или speech-to-speech, этот стек придётся выбирать отдельно.
Что можно запускать локально
Small SFX и Small Music в README отмечены как варианты без обязательного GPU: Stability AI указывает CPU как целевое железо и сценарии вроде коротких эффектов или двухминутных треков. Medium уже требует GPU с CUDA и Flash Attention 2, зато даёт длину до 380 секунд и ориентирован на более качественную генерацию.
Производительность лучше читать как заявление вендора, а не как независимый тест Toolarium. В README указано, что для Small 120-секундная генерация занимает 0,45 секунды на H200 и 5,92 секунды на Mac CPU; для Medium 380 секунд — 1,31 секунды на H200, а пиковое выделение VRAM в таблице доходит до 6,52 ГБ. С TensorRT цифры ниже: для Medium на 380 секунд указаны 0,43 секунды.
Эти числа полезны не как обещание «у всех будет так же», а как сигнал о направлении. Stability AI явно пытается сделать аудиогенерацию не только облачной функцией, но и локальным компонентом для приложений. Если модель можно крутить на ноутбуке, рабочей станции или edge-устройстве, появляются сценарии офлайн-редакторов, игровых инструментов и приватных корпоративных пайплайнов.
Лицензия и данные: где нужно быть осторожным
Stability AI делает сильный акцент на данных. В анонсе сказано, что модели обучены на полностью лицензированных данных. В карточках Hugging Face детализация такая: датасет включает 1 278 902 аудиозаписи, из них 806 284 лицензированы у AudioSparx, ещё 472 618 взяты из Freesound. Для Freesound указаны лицензии CC-0, CC-BY и CC-Sampling+, а музыкальные фрагменты дополнительно фильтровались, чтобы убрать защищённый контент.
Риски для музыкальных платформ остаются, но разговор становится предметнее. В индустрии генеративной музыки главный спор давно идёт не только о качестве, а о происхождении данных, правах на выходы и коммерческом покрытии. У Stability AI здесь понятная ставка: показать, что open-weight аудиомодель может быть не только скачиваемой, но и юридически более предсказуемой.
Коммерческая часть тоже требует аккуратности. Страница лицензий Stability AI относит Stable Audio 3.0 к Community License для исследователей, разработчиков, малого бизнеса и авторов с выручкой ниже $1 млн в год. Для enterprise, API-провайдеров и компаний выше этого порога указана Enterprise License с коммерческим использованием, поддержкой внедрения и кастомным ценообразованием.
Ещё одна деталь для разработчиков: карточки Hugging Face предупреждают, что модель включает компоненты, распространяемые по условиям Gemma. Значит, проверять нужно не только лицензию Stability AI, но и условия зависимостей, особенно если модель попадает в коммерческий продукт.
Что это меняет для продуктов
Stable Audio 3 важна даже без прямой победы над музыкальными сервисами. Для open-weight аудио достаточно, чтобы вокруг модели начали появляться рабочие плагины, локальные интерфейсы, LoRA-настройки и специализированные пайплайны. В анонсе Stability AI уже называет ComfyUI среди партнёрских платформ, а GitHub-репозиторий даёт отдельный inference и fine-tuning пакет.
Для продуктовой команды здесь три практических сценария. Первый — быстрые звуковые эффекты для игр, видео и интерфейсов, где не нужен целый музыкальный сервис. Второй — редактирование существующего материала: заменить фрагмент, продолжить дорожку, сгенерировать вариацию под сцену. Третий — брендовая или студийная настройка через LoRA, если юридическая и техническая часть проекта это допускает.
Самый здоровый способ оценивать релиз — не ждать от него магии, а проверить конкретный пайплайн. Сможет ли Small SFX закрыть пакет коротких эффектов без GPU? Потянет ли Medium нужную длину и качество на вашей видеокарте? Достаточно ли Community License для вашего типа использования? Есть ли в команде человек, который сможет обслуживать модель, а не только один раз запустить демо?
Что смотреть дальше
У Stable Audio 3 есть шанс стать для аудио тем, чем открытые веса давно стали для изображений: не единственным лучшим сервисом, а базой для чужих инструментов. Но это случится только при трёх условиях.
Во-первых, сообщество должно получить удобные рабочие сборки: ComfyUI-ноды, плагины для редакторов, понятные LoRA-процессы и примеры на обычном железе. Во-вторых, нужна независимая проверка качества на реальных задачах, а не только демо-треки и vendor-бенчмарки. В-третьих, лицензия должна оставаться понятной для команд, которые хотят не экспериментировать по вечерам, а встраивать модель в продукт.
Пока вывод такой: Stable Audio 3 не превращает генерацию музыки в полностью открытую и беспроблемную область. Зато релиз делает аудио заметно ближе к разработчикам. Веса можно скачать, архитектуру можно изучить, пайплайн можно запускать и дообучать. Для рынка, где многие сильные модели живут только за API, это уже существенный сдвиг.
Читайте также
- Нейросеть для музыки: обзор Suno, Udio, Stable Audio и других сервисов в 2026 году
- Google Lyria 3 Pro: генерация музыки до 3 минут за $0,08 через API
- Открытые модели vs закрытые API: как выбирать в 2026 году
Источники и проверка фактов
- Stability AI: официальный анонс Stable Audio 3.0, опубликован 20 мая 2026 года, проверено 27 мая 2026 года.
- Stability AI: продуктовая страница Stable Audio 3.0, использована для проверки позиционирования моделей, сценариев и вариантов развёртывания, проверено 27 мая 2026 года.
- GitHub: Stability-AI/stable-audio-3, использован для проверки архитектуры, таблицы моделей, inference-режимов и производительности, проверено 27 мая 2026 года.
- Hugging Face Papers: Stable Audio 3, arXiv:2605.17991, использован для проверки описания technical report и списка связанных моделей, проверено 27 мая 2026 года.
- Hugging Face: stable-audio-3-medium и карточки Small/Small SFX, использованы для проверки лицензии, датасета и условий доступа, проверено 27 мая 2026 года.
- Stability AI License, использована для проверки условий Community License и Enterprise License, проверено 27 мая 2026 года.
- MarkTechPost: RSS-источник handoff, использован как исходный новостной сигнал, проверено 27 мая 2026 года.