4-битное обучение LLM на NVFP4: что показала NVIDIA
Разбор NVFP4 pretraining от NVIDIA: 12B модель, 10T токенов, FP8-базовая линия, ограничения mixed precision и реальная экономика Blackwell.

Проверено 26 мая 2026 года. NVFP4 pretraining легко принять за ещё одну историю про 4-битную квантизацию моделей. Но здесь речь не о том, как ужать готовые веса для инференса. NVIDIA описывает более рискованный участок: обучение LLM с нуля, где часть матричных операций в линейных слоях уходит в 4-битный формат NVFP4 на Blackwell Tensor Cores.
Главный результат звучит сильно: в препринте arXiv:2509.25149 NVIDIA сообщает о 12-миллиардной hybrid Mamba-Transformer модели, обученной на 10 трлн токенов, с потерями и downstream-точностью, близкими к FP8-базовой линии. Но это не значит, что все передовые модели теперь можно обучать в 4 битах и автоматически платить за pretraining в 2-3 раза меньше. Методология держится на смешанной точности, специальных приёмах для устойчивости и проверена пока на ограниченном масштабе.
Новостной повод пришёл через MarkTechPost от 18 мая 2026 года, но сама работа NVIDIA была подана на arXiv 29 сентября 2025 года и обновлена 4 марта 2026 года. Поэтому это не срочная новинка, а разбор методологии, которая стала важнее на фоне Blackwell и борьбы за стоимость обучения.
| Факт | Что подтверждено | Где граница |
|---|---|---|
| Масштаб эксперимента | 12B hybrid Mamba-Transformer, 10T токенов, сравнение с FP8. | Такой масштаб ещё не проверяет frontier-модели на сотни миллиардов параметров. |
| Качество | В статье указано MMLU-Pro 62,58% для NVFP4 против 62,62% для FP8; итоговые оценки в основном близки. | В кодовых задачах NVFP4 в таблице NVIDIA слегка отстаёт от FP8. |
| Где применяется NVFP4 | Основной перенос в FP4 касается GEMM-операций внутри линейных слоёв. | Embeddings, output head, normalization, нелинейности, attention-компоненты, optimizer states и master weights остаются в более высокой точности. |
| Аппаратный смысл | В препринте NVIDIA указывает для Blackwell Tensor Cores 2x FP4-throughput против FP8 на GB200 и 3x на GB300; FP4 operands занимают примерно вдвое меньше памяти, чем FP8. | Полная стоимость обучения не падает автоматически в 2-3 раза: не весь training graph работает в FP4. |
Почему это не обычная 4-битная квантизация
Большая часть разговоров про 4 бита в LLM крутится вокруг инференса: GGUF для локального запуска, GPTQ и AWQ для серверных GPU, QLoRA для дообучения. Такой стек берёт уже обученную модель и пытается дешевле её хранить или запускать. Внутри Toolarium это отдельный кластер: квантизация LLM через GGUF, GPTQ и AWQ.
NVFP4 pretraining про другое. Здесь модель ещё учится, веса и градиенты постоянно меняются, а ошибка округления может накапливаться миллионы шагов. Если в инференсе квантизация чаще ломает качество ответа, то в pretraining она может сорвать сходимость. Поэтому в статье NVIDIA вокруг NVFP4 построен целый рецепт: micro-block scaling, 2D scaling для весов, Random Hadamard Transform и stochastic rounding для градиентов.
Полезная формулировка для практиков такая: NVFP4 в этой работе - не «упаковка модели в 4 бита», а попытка перевести самую дорогую часть обучения, матричные умножения в линейных слоях, в более узкую точность без развала loss curve.
Как устроен NVFP4
В документации NVIDIA Transformer Engine 2.15.0 NVFP4 описан как 4-битное значение E2M1 с двумя уровнями масштабирования: локальный FP8 E4M3 scale factor на блок из 16 элементов и глобальный FP32 scale factor на тензор. Идея простая: сам элемент хранится грубо, но масштабирование помогает не потерять динамический диапазон.
Отсюда берётся отличие от более грубых FP4-вариантов. NVFP4 уменьшает размер micro-block до 16 элементов и использует более точный E4M3 scale factor. В препринте NVIDIA это связывает с меньшей ошибкой на выбросах: большие значения внутри блока не так сильно портят представление остальных элементов.

Сам по себе формат не спасает обучение. NVIDIA отдельно подчёркивает, что для 12B / 10T понадобились четыре инженерных решения: оставить чувствительные линейные слои в BF16 или MXFP8, применять Hadamard transforms к входам Wgrad GEMM, использовать 2D scaling 16x16 для весов и включить stochastic rounding для градиентов. Убери любой из этих элементов - и в ablation-экспериментах сходимость ухудшается.
Где появляется экономия
Экономика здесь завязана на GEMM. Современное обучение LLM большую часть времени тратит на матричные умножения, особенно в fully-connected слоях. Если эти операции можно выполнять в FP4 быстрее, появляется шанс повысить token throughput на том же кластере Blackwell.
В описании Tensor Cores NVIDIA пишет, что Blackwell Tensor Cores поддерживают новые форматы точности, включая NVFP4, а Transformer Engine использует FP4 для ускорения LLM и MoE workloads. В препринте цифры даны аккуратнее: FP4 GEMM на GB200 имеет примерно 2x math throughput к FP8, на GB300 - 3x, а память под FP4 operands примерно вдвое ниже, чем под FP8 operands.
Здесь важно не перепутать локальную и полную экономику. Ускорение GEMM не превращается автоматически в такое же снижение счёта за обучение. В реальном pretraining остаются коммуникации, optimizer states, attention, data pipeline, сохранение чекпоинтов, отказоустойчивость и простой железа. Поэтому корректный вывод не «стоимость упала в 3 раза», а «самая дорогая вычислительная часть получила новый путь к снижению памяти и росту throughput». Это хорошо ложится в более широкий сюжет про enterprise AI инфраструктуру и гонку за compute.
Что показал эксперимент 12B / 10T
Валидация NVIDIA выглядит убедительно именно потому, что это не короткая игрушечная проверка. Модель на 12 млрд параметров обучали на 10 трлн токенов и сравнивали с FP8 reference model. По графику из статьи NVFP4 closely tracks FP8: в стабильной фазе relative loss error остаётся ниже 1%, а ближе к decay phase расширяется чуть выше 1,5%.
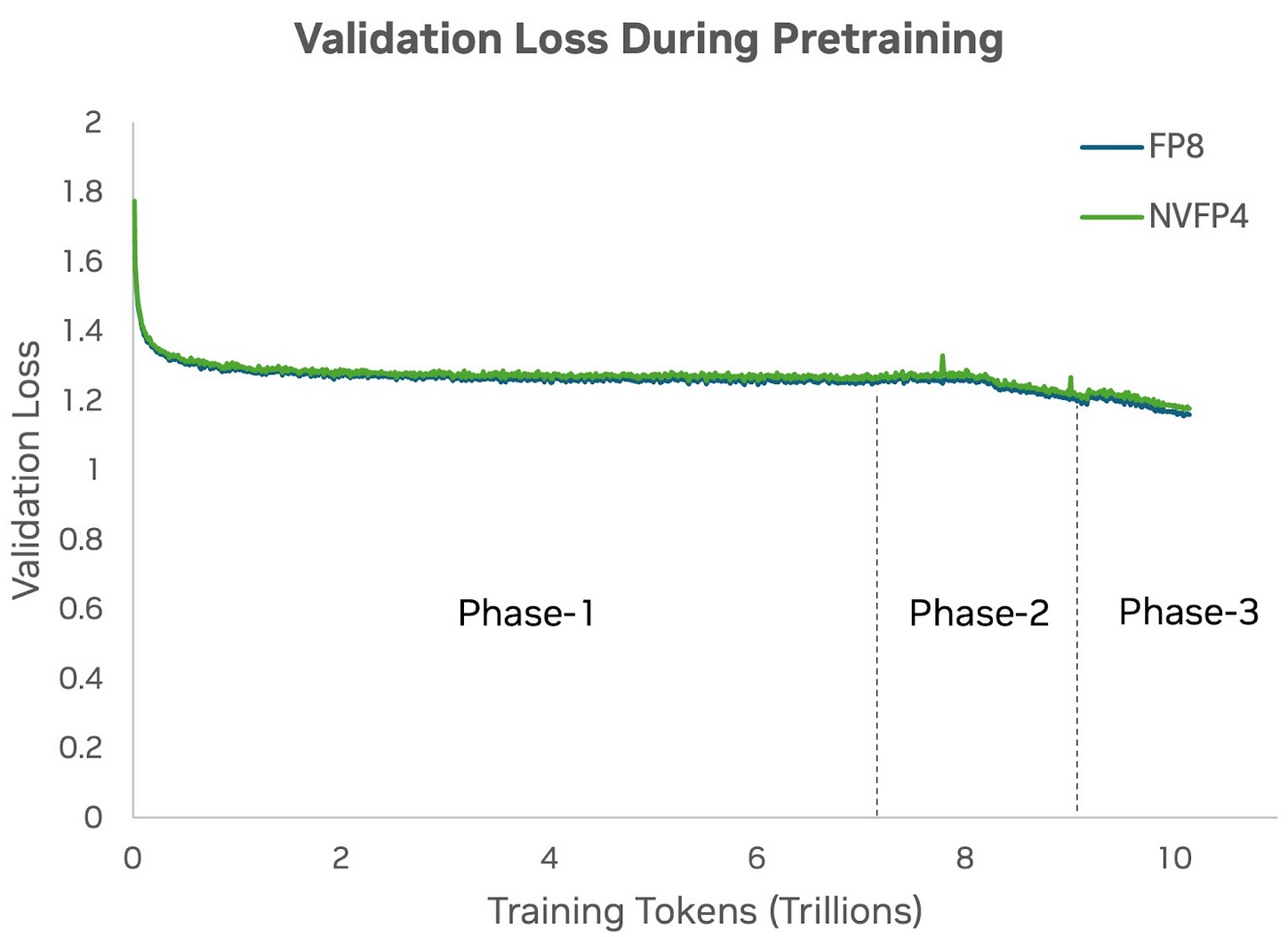
Downstream-метрики тоже не разваливаются. В таблице из препринта NVFP4 почти совпадает с FP8 на MMLU-Pro: 62,58% против 62,62%. На MMLU NVFP4 ниже - 76,57% против 77,36%, зато на GSM8k CoT выше - 92,27% против 89,08%. В кодовых задачах картина хуже: HumanEval+ 57,43% против 59,93%, MBPP+ 55,91% против 59,11%. NVIDIA сама оговаривает, что по coding task NVFP4 немного отстаёт и возможен шум конкретного checkpoint evaluation.
Эти числа полезны не как рейтинг модели. Они показывают, что 4-битное обучение уже можно обсуждать как инженерный путь, а не только как лабораторный трюк. Но они не закрывают вопрос масштабирования на модели другого размера, другие архитектуры и другие датасеты.
Ограничения важнее лозунга «4 бита»
Самая честная часть работы NVIDIA - список того, что не перевели в NVFP4. В 12B-конфигурации первые два блока и последние восемь блоков оставили в BF16; это около 16% линейных слоёв. Embeddings, output projection head, normalization layers, non-linearities и attention components тоже остались в исходной точности, обычно BF16 или FP32. Main weights, weight gradients для накопления и optimizer states держались в FP32.
Для редакционного вывода это важнее красивого слова «4-битное». Работа показывает не end-to-end FP4 training, а смешанный рецепт, где NVFP4 забирает наиболее тяжёлые GEMM-операции, а численно чувствительные части остаются в более высокой точности. Такой компромисс и делает результат правдоподобным.
Есть и второй стоп-сигнал. В техническом блоге NVIDIA от 25 августа 2025 года компания прямо описывает NVFP4 training как направление, которое всё ещё находится в research phase. Это не коробочный совет «завтра переводите весь pretraining на FP4», а сигнал для команд, которые уже работают на уровне больших training runs.
Кому это важно сейчас
Если команда занимается обычным fine-tuning, LoRA или адаптацией готовой open-weight модели, NVFP4 pretraining не заменяет привычные инструменты. Там другие узкие места: качество датасета, выбор базовой модели, стоимость inference serving и контроль деградации после дообучения. Для этого лучше смотреть в сторону отдельного материала про fine-tuning LLM и выбор метода дообучения.
Для лабораторий и компаний, которые реально обучают foundation models, история другая. NVFP4 указывает, куда движется экономика training cluster: не только больше GPU и быстрее сеть, но и более агрессивная работа с численными форматами. Если Blackwell/GB300 позволяет ускорять FP4 GEMM, а software stack вроде Transformer Engine прячет часть сложности, команды получают ещё один рычаг для экспериментов на том же бюджете.
Самый сильный практический эффект может быть не в одном гигантском training run, а в количестве попыток. Если команда дешевле прогоняет предварительные эксперименты, она быстрее ищет архитектуру, dataset mix и schedule. Но для этого нужно, чтобы FP4-рецепт был устойчивым, воспроизводимым и понятным в отладке. NVIDIA показала важный шаг, но не сняла эту инженерную работу с пользователя.
Итог
NVFP4 pretraining важен не потому, что «4 бита победили 8 бит». Важен сам факт: NVIDIA публично показала длинный training run на 12B модели и 10 трлн токенов, где NVFP4 близко держится к FP8 по loss и большинству downstream-метрик. Для области, где малая численная ошибка может накапливаться неделями обучения, это серьёзный результат.
Но материал стоит читать трезво. NVFP4 не переводит весь training graph в 4 бита, не доказывает готовность метода для frontier-моделей любого масштаба и не гарантирует кратное снижение полной стоимости обучения. Инженерный смысл рецепта в другом: часть самых дорогих операций в эпоху Blackwell можно делать быстрее и уже по памяти, если оставить чувствительные участки в более высокой точности и принять сложность mixed-precision training.
Источники и дата проверки
Факты, даты, числа и изображения проверены 26 мая 2026 года по первоисточникам и официальным материалам:
- arXiv:2509.25149, Pretraining Large Language Models with NVFP4 - препринт NVIDIA: 12B model, 10T tokens, loss, downstream-таблица, методология mixed precision.
- NVIDIA Technical Blog: NVFP4 Trains with Precision of 16-Bit and Speed and Efficiency of 4-Bit - официальный разбор, опубликован 25 августа 2025 года, источник изображений.
- NVIDIA Transformer Engine: NVFP4 - описание E2M1, E4M3 block scale, FP32 global scale, stochastic rounding и поддерживаемых устройств.
- NVIDIA Tensor Cores - официальное описание Blackwell Tensor Cores, NVFP4 и поддерживаемых precisions.
- MarkTechPost, 18 мая 2026 года - вторичный новостной повод, не основной источник технических характеристик.



