ByteDance MMProLong: почему вопросы к длинным документам полезнее OCR
Разбираем ByteDance MMProLong: почему VQA-обучение длинных документов оказалось сильнее OCR-транскрипции и что это значит для PDF-ассистентов.

По состоянию на 27 мая 2026 года ByteDance Seed и HKUST описали MMProLong, исследовательскую мультимодальную модель для длинных документов. Главный вывод работы простой и неприятный для привычного OCR-подхода: если модель нужно научить работать с сотнями страниц, полезнее задавать ей вопросы по документу, чем заставлять переписывать весь текст страниц.
MMProLong построена на Qwen2.5-VL-7B. Авторы расширяли модель с 32K до 128K контекста через продолженное обучение на длинных последовательностях и обучали её на бюджете 5 млрд токенов. Затем проверили перенос на 256K и 512K без дополнительного обучения. Эта работа не превращает MMProLong в готовый продукт ByteDance и не отменяет OCR. Её ценность в рецепте данных: как учить мультимодальные модели искать ответ внутри длинного визуально-текстового контекста.
Для разработчиков PDF-ассистентов, корпоративного поиска и агентных систем это важнее очередной цифры контекстного окна. Большой контекст сам по себе не гарантирует, что модель найдёт нужную страницу, таблицу или подпись к графику. Исследование показывает, что узкое место часто находится в поиске релевантного фрагмента: модель должна понять, где лежит нужный кусок, а уже потом рассуждать над ним.
Что показали ByteDance Seed и HKUST
Работа опубликована на arXiv 13 мая 2026 года под названием Training Long-Context Vision-Language Models Effectively with Generalization Beyond 128K Context. В списке авторов указаны исследователи HKUST и ByteDance Seed; в самой статье отмечено, что часть работы выполнена в ByteDance Seed. Статус статьи указан как work in progress, а страница проекта на первой странице пока помечена как coming soon.
Авторы взяли Qwen2.5-VL-7B как базовую модель. У Toolarium уже есть отдельный обзор линейки Qwen, поэтому здесь важно не путать уровни: MMProLong не новая потребительская функция Qwen и не публичный сервис. Это исследовательский вариант, полученный продолженным обучением для длинного мультимодального контекста.
Экспериментальная постановка выглядит так: модель обучали с максимальной длиной последовательности 131 072 токена, то есть примерно 128K, при фиксированном бюджете 5 млрд токенов. Документный пул включал более 1,5 млн PDF из разных областей. Для синтеза данных выбирались документы на 32-50 страниц, страницы рендерились в изображения, а OCR-эксперт на базе Seed 2.0 разбирал структуру и текстовые блоки.
Почему вопросы оказались полезнее OCR
Классический ход для document AI выглядит логично: сначала распознать текст, затем обучать модель транскрибировать страницы. В длинном мультимодальном контексте такой сигнал оказывается слабым. Полная транскрипция заставляет модель повторять много текста, но плохо учит её находить нужный фрагмент среди десятков страниц.
MMProLong использует другой источник обучающего сигнала. Сначала из документа выбирается связный фрагмент на 8-15 страниц. Затем отдельная модель генерирует пару вопрос-ответ по этому фрагменту. После этого пара возвращается в полный документный контекст, и обучаемая модель должна ответить на вопрос, видя весь документ, а не только короткий отрывок.
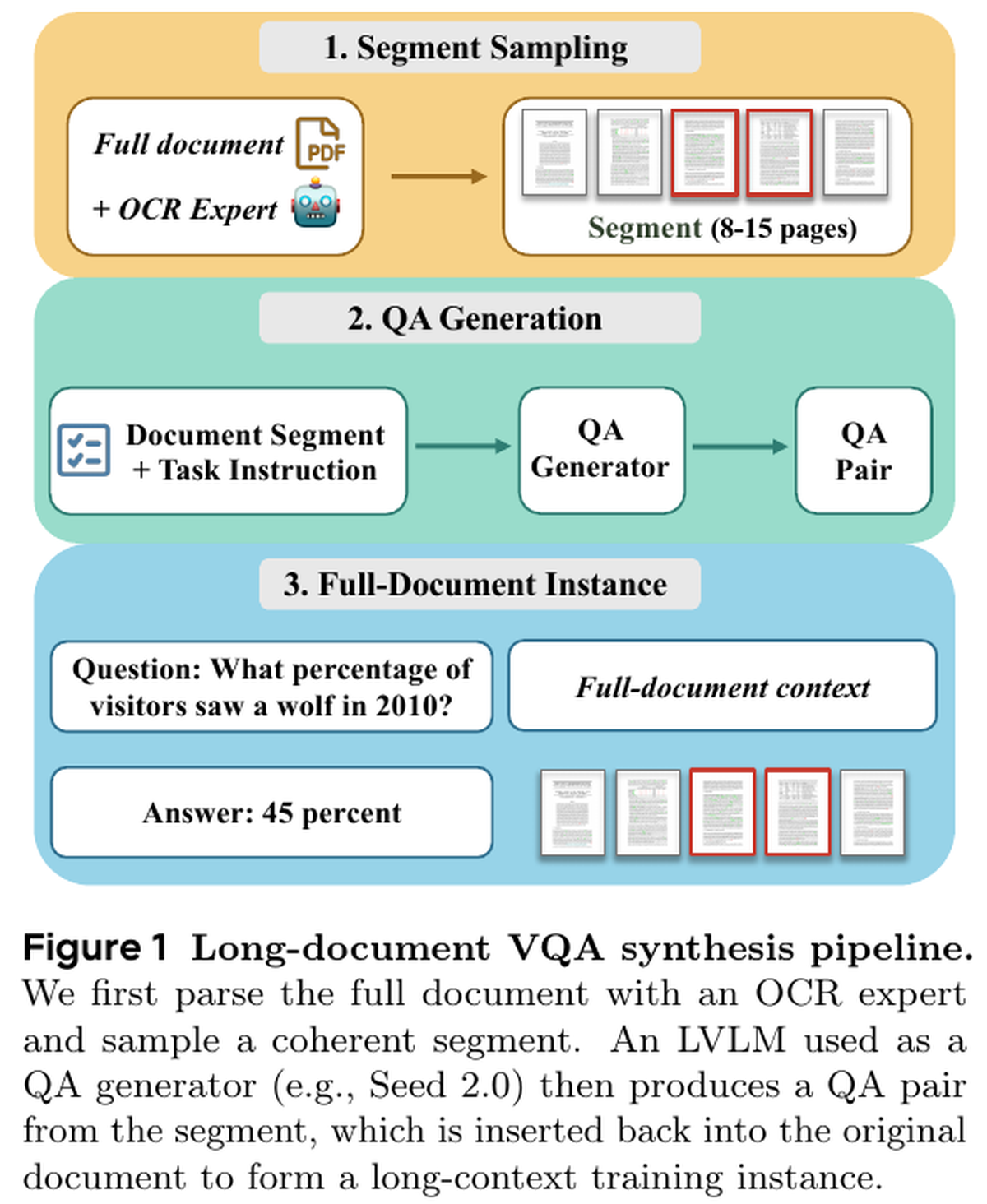
Такой подход ближе к реальному использованию длинных документов. Пользователь редко просит модель переписать все страницы PDF. Чаще он спрашивает: где в договоре условие о штрафе, какие значения указаны в таблице, чем отличаются два раздела отчёта. Для таких задач модель должна не только читать текст, но и отбрасывать отвлекающие страницы.
Авторы отдельно проверили качество сгенерированных пар: из 100 вручную просмотренных QA-примеров 97 оказались полностью корректными, два содержали неверные ответы, один имел неточную разметку доказательных фрагментов. Данные не становятся идеальными, зато у синтетической цепочки появляется понятный уровень шума.
Цифры: VQA растёт, OCR проседает
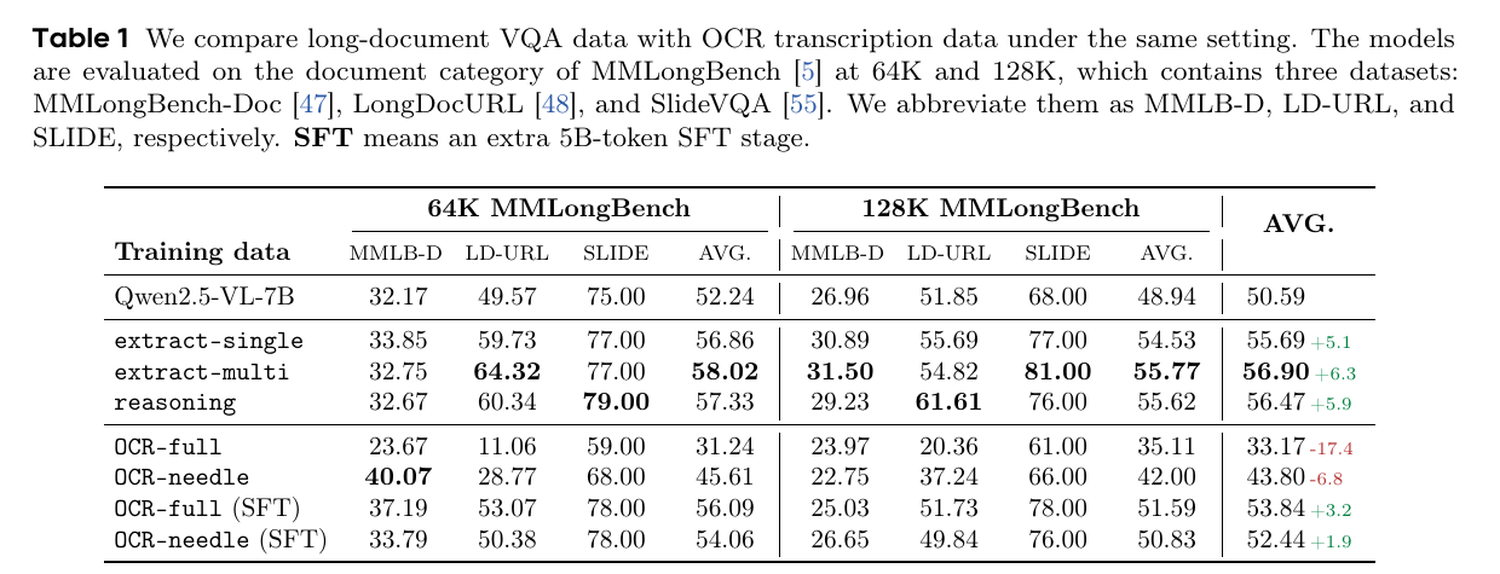
Самый показательный результат находится в сравнении long-document VQA и OCR-транскрипции на MMLongBench при 64K и 128K контекста. Базовая Qwen2.5-VL-7B получила средний результат 50,59. Варианты с вопросами и ответами выросли до 55,69-56,90. Лучшим оказался extract-multi, где вопрос требует собрать факты с нескольких страниц.
OCR-обучение дало обратный эффект. Full-document OCR опустил средний результат до 33,17, то есть на 17,4 пункта ниже базы. Needle-page OCR, где нужно транскрибировать только 1-3 выбранные страницы среди отвлекающих, тоже просел до 43,80. Даже дополнительный SFT-этап на 5 млрд токенов не вывел OCR-варианты на уровень лучших VQA-рецептов.
Отсюда и главный инженерный вывод. Для длинных документов мало научить модель видеть символы. Ей нужен обучающий сигнал, который заставляет искать релевантное место, связывать вопрос с доказательством и отвечать по найденному фрагменту. В статье это описано как смесь с упором на извлечение: больше задач на поиск фактов, меньше задач на сложное рассуждение, но не ноль reasoning, чтобы сохранить разнообразие.
Зачем нужен баланс длин, а не только 128K
Авторы проверяли не только тип задачи, но и распределение длины обучающих последовательностей. Интуитивно хочется набить обучение примерами около верхней границы 128K. В работе это оказалось не лучшим вариантом. Более сбалансированная смесь разных длин дала стабильнее результат.
Причина в природе задачи. Модель должна искать ключевую информацию на разных расстояниях и позициях, а не выучить один сценарий «ответ всегда где-то в очень длинном хвосте документа». Для PDF-ассистентов это практичный сигнал: датасет из одних гигантских документов может выглядеть впечатляюще, но хуже учить универсальному поиску внутри контекста.
Этот вывод хорошо стыкуется с тем, как работает RAG, но не заменяет его. RAG выносит поиск во внешнюю цепочку: индекс, эмбеддинги, ранжирование, фрагменты. MMProLong показывает внутренний вариант той же проблемы: даже когда весь документ уже помещён в контекст модели, ей всё равно нужно научиться находить нужные куски, а не просто иметь большое окно.
Что получилось у MMProLong
Финальная MMProLong на 64K и 128K получила средний результат 57,70 на long-document VQA против 50,59 у исходной Qwen2.5-VL-7B. Разница составляет 7,11 пункта. Это хороший результат для 7B-модели, но его нельзя продавать как абсолютный рекорд: в таблице есть более сильные закрытые модели, а среди открытых крупных моделей часть результатов выше.
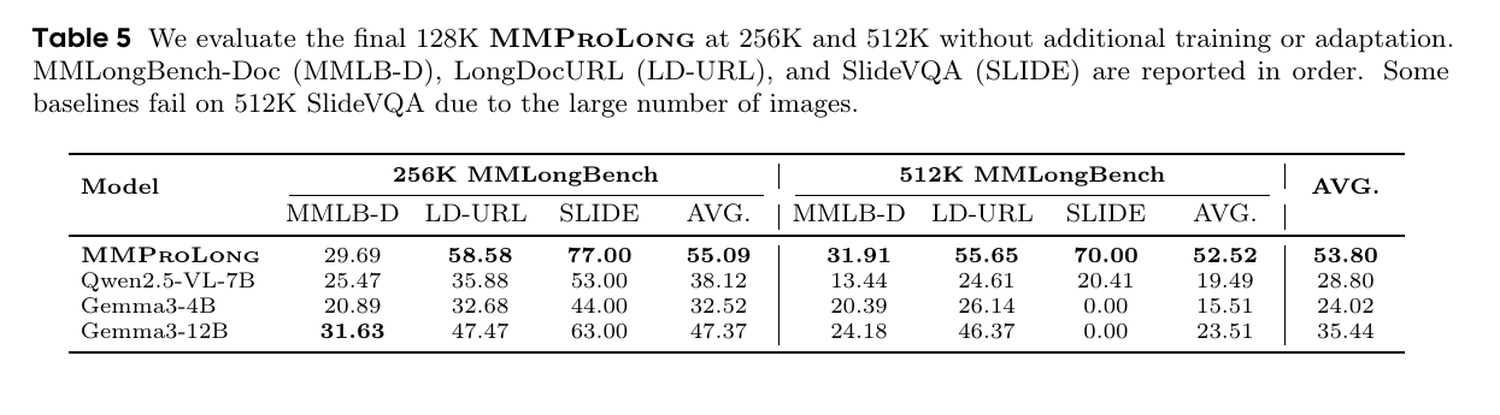
Более интересна проверка за пределами окна обучения. Модель обучалась до 128K, но авторы оценили её на 256K и 512K без дополнительного обучения или адаптации. В этой постановке MMProLong получила средний результат 53,80, а исходная Qwen2.5-VL-7B упала до 28,80. На 512K средний результат MMProLong составил 52,52 против 19,49 у базы.
Авторы также проверили перенос за пределы документного VQA: поиск «иголки» на веб-страницах с изображениями, сжатие длинного визуально-текстового контекста и понимание длинного видео. Например, на MM-NIAH средний балл вырос с 20,0 у Qwen2.5-VL-7B до 49,4 у MMProLong. На видео-бенчмарках прирост скромнее, но есть на всех трёх проверках: Video-MME, MLVU и LongVideoBench.
Что это значит для PDF-ассистентов и агентов
Для прикладных команд вывод не в том, что OCR больше не нужен. OCR по-прежнему нужен для индексации, поиска, нормализации документов, доступности и контроля качества. Исследование бьёт по другой привычке: обучать мультимодальную модель на длинных документах через массовую транскрипцию и ждать, что из этого появится способность отвечать на вопросы.
Если вы строите ассистента по договорам, исследовательским PDF, отчётам, презентациям или длинным веб-страницам, данные для обучения и оценки должны напоминать настоящие запросы. Нужны вопросы с доказательными фрагментами, случаи с несколькими страницами, таблицы, графики, неоднозначные формулировки, отвлекающие разделы. Чем ближе обучающий сигнал к задаче поиска ответа, тем меньше модель учится механически переписывать документ.
Для агентных систем это тоже важно. Длинный след выполнения задачи может включать сообщения, скриншоты, таблицы, страницы документации, логи и промежуточные решения. Если модель не умеет находить релевантный кусок внутри такого следа, увеличение окна превращается в дорогую память с плохим доступом.
Ограничения, о которых нельзя забывать
MMProLong пока исследовательский результат. В статье нет подтверждения публичных весов, API или готового продукта ByteDance для пользователей. На первой странице PDF проектная ссылка помечена как coming soon, а сама работа имеет статус work in progress.
Масштаб тоже ограничен: основная систематическая проверка проводилась на 7B/8B-классе. Авторы прямо пишут, что перенос выводов на 30B, 70B и ещё более длинные окна требует существенно больших затрат. Оценка long-document VQA полагается на проверку ответов другой моделью, а это добавляет стоимость и собственные риски.
Ещё одна тонкость: цифры 256K и 512K не означают, что модель обучали на 512K. Это проверка обобщения за пределами 128K окна обучения. Для продакшена такую способность всё равно нужно проверять на своих документах, железе, формате изображений и критериях качества.
Главное
ByteDance MMProLong интересна не названием и не размером окна, а сдвигом в обучающих данных. Для длинных мультимодальных документов вопрос-ответ по релевантному фрагменту даёт модели более полезный сигнал, чем транскрипция страниц. Модель учится искать доказательство внутри документа, а не просто воспроизводить текст.
Это хороший ориентир для команд, которые делают PDF-ассистентов, RAG-цепочки с визуальными документами и агентов с длинной памятью. Контекстное окно нужно, но без правильной обучающей задачи оно быстро превращается в красивую цифру. MMProLong показывает, что качество длинного контекста начинается с того, какие вопросы модель учится решать.
Читайте также
- Мультимодальные модели: ИИ, который видит, слышит и читает
- Qwen: обзор языковой модели от Alibaba
- RAG: что это и когда он действительно нужен
Источники и проверка фактов
- arXiv: Training Long-Context Vision-Language Models Effectively with Generalization Beyond 128K Context, версия от 13 мая 2026 года, проверено 27 мая 2026 года.
- PDF статьи arXiv:2605.13831, использован для таблиц, диаграмм и чисел экспериментов, проверено 27 мая 2026 года.
- The Decoder: ByteDance study finds that asking LMMs questions beats making it transcribe text for long document training, опубликовано 24 мая 2026 года, проверено 27 мая 2026 года.
- Qwen/Qwen2.5-VL-7B-Instruct на Hugging Face, использован для проверки контекста базовой модели Qwen2.5-VL-7B, проверено 27 мая 2026 года.



