ByteDance Lance: зачем одной ИИ-модели понимать, генерировать и редактировать медиа
ByteDance Lance показывает, куда движется мультимодальный ИИ: одна модель для понимания, генерации и редактирования медиа. Но это пока research-релиз, а не замена Sora.
ByteDance Lance — свежий исследовательский релиз из команды Intelligent Creation Team. На первый взгляд это ещё одна мультимодальная модель: понимает картинки и видео, генерирует изображения, делает text-to-video и редактирует медиа по инструкции. Но интерес здесь не в списке режимов. Lance показывает, как разработчики пытаются собрать разрозненные медиа-задачи в один контур, а не держать отдельный инструмент под OCR, отдельный генератор картинок и отдельную модель для видео.
По состоянию на 27 мая 2026 года официальная страница проекта описывает Lance как 3B-модель для понимания, генерации и редактирования изображений и видео. Это не продукт уровня Sora или Runway, а исследовательский артефакт: авторы отдельно предупреждают, что качество зависит от промпта, разрешения, длительности ролика, движения и сценария редактирования. Поэтому правильный вопрос звучит не «заменит ли Lance видеогенераторы», а «зачем вообще объединять понимание и генерацию в одной модели».
Если нужен базовый контекст, у нас уже есть отдельный материал про мультимодальные модели. Здесь разберём конкретно ByteDance Lance: что выпущено, как устроена архитектура, где сильные стороны и почему релиз важен для рынка медиа-ИИ.
Что выпустила ByteDance
Lance вышла как открытый исследовательский проект: есть страница проекта, статья на arXiv, код и веса на Hugging Face. Технический отчёт был отправлен на arXiv 18 мая 2026 года и обновлён 20 мая. В репозитории ByteDance указано, что 18 мая команда запустила страницу проекта и выложила начальный код для инференса и веса, 25 мая появился Hugging Face Space, а 26 мая Gradio-интерфейс получил поддержку генерации, редактирования и понимания изображений и видео.
| Параметр | Что известно на 27 мая 2026 года |
|---|---|
| Размер | 3B активных параметров. |
| Задачи | t2i, t2v, image_edit, video_edit, x2t_image, x2t_video. |
| Обучение | С нуля, staged multi-task recipe, бюджет до 128 A100. |
| Разрешение | До 768×768 для изображений и 480p при 12 FPS для видео в опубликованном чекпойнте. |
| Лицензия | Apache-2.0 на Hugging Face. |
| Железо для инференса | Авторы рекомендуют GPU минимум с 40 ГБ VRAM, Python 3.10+ и CUDA 12.4+. |
Эти цифры важны для трезвой оценки. 3B звучит компактно по меркам больших моделей, но это не «запустил на старом ноутбуке и получил видеостудию». 40 ГБ VRAM сразу относит Lance к рабочим станциям и серверным GPU, а не к массовому потребительскому запуску.
Зачем одной модели понимать и генерировать медиа
Обычный стек для работы с медиа часто выглядит как конвейер. Одна модель распознаёт текст на изображении, вторая отвечает на визуальные вопросы, третья генерирует картинку, четвёртая редактирует её, пятая собирает видео. Такой подход удобен, пока задачи изолированы. Но стоит пользователю попросить: «посмотри на этот ролик, пойми, что происходит, и измени сцену без потери стиля», конвейер начинает скрипеть.
Проблема не только в количестве моделей. Разные модели по-разному кодируют контекст, теряют детали между этапами и требуют ручной оркестрации. Unified-подход пытается сделать общий контекст для текста, изображений и видео, чтобы модель не «передавала эстафету» между подсистемами, а держала сцену внутри одной рабочей памяти.
Именно поэтому Lance не стоит сводить к теме нейросетей для генерации видео. Генерация роликов здесь только часть истории. Релиз интереснее как попытка объединить понимание, генерацию и редактирование: от VQA и OCR до text-to-video, image-to-video и многошагового editing.

Как Lance разводит конфликт между пониманием и генерацией
Главная техническая идея в статье — две опоры: unified context modeling и decoupled capability pathways. Если упростить, Lance кладёт текст, изображения и видео в общий interleaved-контекст, но не заставляет одну и ту же внутреннюю дорогу одинаково хорошо решать все задачи.
Для понимания медиа модели нужны семантические признаки: что на изображении, где объект, какой текст написан, что произошло в кадре. Для генерации нужны другие представления: VAE-latents, шум, предсказание движения в пространстве изображения или видео. Если всё это смешать без развязки, задачи начинают мешать друг другу. Авторы Lance используют dual-stream mixture-of-experts: часть пути работает на семантическое понимание, часть — на визуальную генерацию.
Отдельная деталь — modality-aware RoPE, или MaPE. Обычный positional encoding помогает модели понимать порядок токенов, но в мультимодальном случае токены не одинаковые: текст, изображение и видео живут в разных пространственных и временных сетках. MaPE нужен, чтобы снизить взаимные помехи между разными визуальными токенами и лучше связать задачи между собой.
Звучит академически, но практический смысл простой: Lance пытается не «прикрутить генератор» к понимающей модели, а учить один мультимодальный контур с разделением ролей внутри.
Бенчмарки: хороший сигнал, но не повод для кликбейта
На странице проекта ByteDance сравнивает Lance с объединёнными моделями и специализированными базовыми моделями на GenEVAL, GEdit-Bench, VBench и MVBench. По опубликованным таблицам Lance выглядит сильнее большинства открытых объединённых подходов, особенно на генерации и редактировании. Но это не означает, что модель готова заменить коммерческие видеосервисы: сравнения ограничены выбранными наборами тестов, разрешениями и условиями запуска.
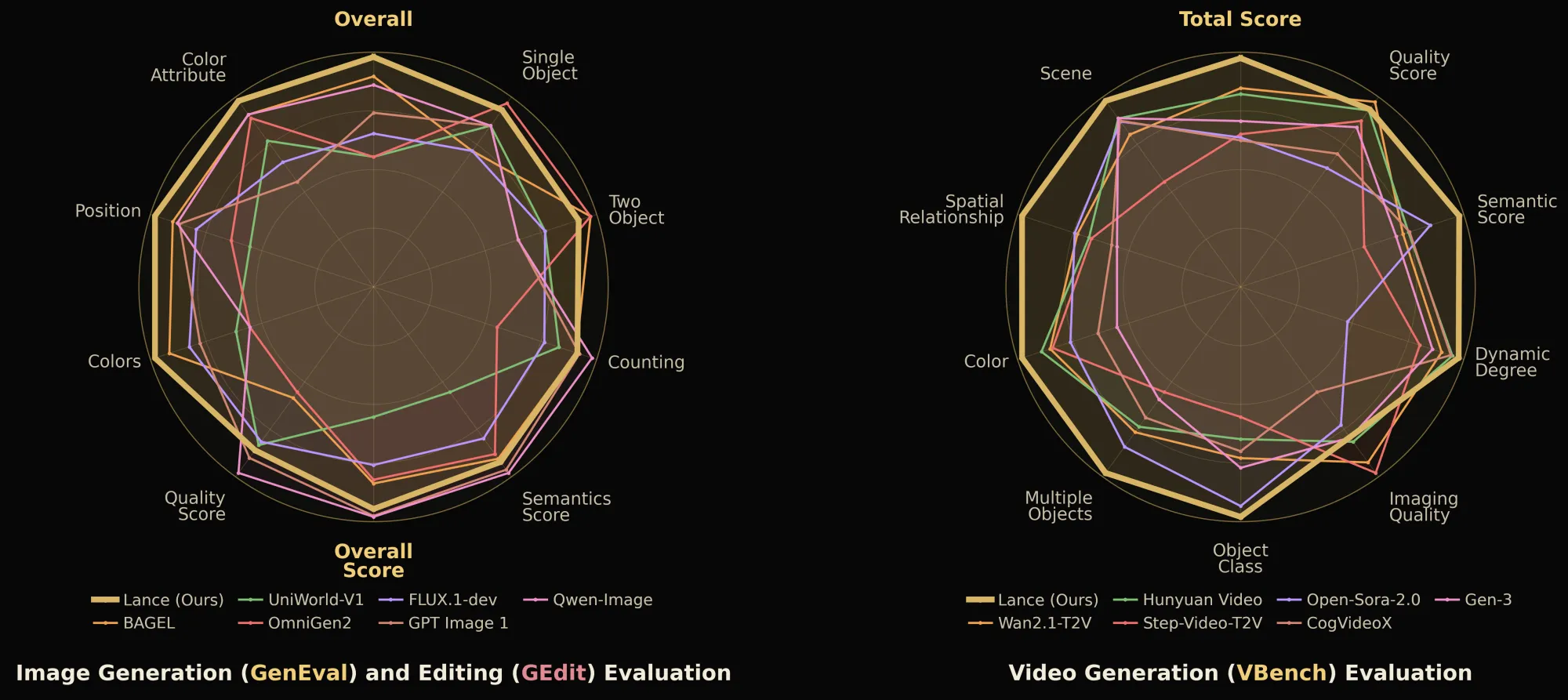
| Тест | Что проверяет | Результат Lance 3B на странице проекта |
|---|---|---|
| VBench | Качество text-to-video по набору визуальных и семантических метрик. | Total Score 85.11, лучший показатель среди перечисленных объединённых моделей. |
| MVBench | Понимание видео: действия, объекты, пространственные и временные категории. | Avg. 62.0, лучший средний показатель среди перечисленных объединённых моделей. |
С этими числами нужна аккуратность. VBench не превращает исследовательский чекпойнт в готовый продукт, а MVBench не покрывает все реальные сценарии видеоаналитики. Тем более авторы сами пишут, что качество может меняться от промпта к промпту. Для разработчиков и исследователей это хороший сигнал; для продуктовых команд — повод тестировать на своих данных, а не верить скриншотам.
Почему Lance попадает в более широкий тренд
ByteDance не одна двигается в сторону моделей, которые умеют переключаться между режимами без отдельного зоопарка подсистем. NVIDIA 19 мая 2026 года представила Nemotron-Labs-Diffusion: tri-mode language model, где одна архитектура объединяет autoregressive decoding, diffusion parallel decoding и self-speculation. По данным NVIDIA, версия 8B декодирует в 5.9 раза больше токенов за forward pass, чем Qwen3-8B, и даёт 4× throughput на SPEED-Bench с SGLang на GB200 GPU.
У Google тот же тренд виден на уровне устройства. В анонсе умных очков на Android XR компания описывает очки с Gemini: перевод речи и текста, навигация, работа с приложениями, снимки и редактирование изображений голосом. Это уже не модель в лаборатории, а попытка спрятать мультимодальный ИИ в повседневный интерфейс.
Lance находится на исследовательском конце этой шкалы. Она не продаёт готовую пару очков и не обещает мгновенный throughput для LLM-инференса. Зато хорошо показывает, куда уходит архитектурная мысль: меньше отдельных моделей, больше общих контекстов, больше режимов внутри одной системы.
Ограничения, которые нельзя прятать
Первое ограничение — статус. Lance — исследовательский артефакт. У проекта есть веса и демо, но авторы не называют его готовой продуктовой моделью. Это значит, что нестабильность качества — не баг в чужом пересказе, а часть текущего состояния релиза.
Второе — железо. Минимум 40 ГБ VRAM для инференса резко сужает аудиторию. Open-source лицензия не равна дешёвому запуску: модель можно изучать, дорабатывать и разворачивать, но комфортный эксперимент всё равно требует серьёзной GPU-памяти.
Третье — видео. Опубликованный чекпойнт обучался до 480p и 12 FPS для генерации видео. Это нормальный исследовательский уровень, но не то, что пользователь ждёт от коммерческого видеоредактора. Если нужен зрелый продуктовый процесс, логичнее смотреть на специализированные сервисы или API. Например, в соседнем материале мы разбирали, как Luma открыла Uni-1.1 API для генерации изображений: там другой угол, больше продуктовой упаковки и меньше академической гибкости.
Итог
ByteDance Lance важна не потому, что «убивает Sora» — такого вывода из источников нет. Она важна как компактный и открытый пример unified media model: одна система пытается понимать, генерировать и редактировать изображения и видео, не разваливая задачу на набор плохо связанных сервисов.
Для исследователей Lance даёт материал для экспериментов с multi-task training, MoE и мультимодальными токенами. Для продуктовых команд — ранний сигнал: интерфейсы будут всё чаще ждать от модели не одного навыка, а связки «понял → изменил → объяснил → продолжил». До стабильного продакшена ещё далеко, но направление видно уже сейчас.