Arcee Trinity-Large-Thinking: открытая модель на 400B
Arcee AI выпустила Trinity-Large-Thinking — модель семейства Trinity с открытыми весами для задач рассуждения. Разбираем характеристики, бенчмарки и ограничения релиза.

Arcee AI выпустила Trinity-Large-Thinking — версию своей большой Trinity-модели с открытыми весами для задач рассуждения. Релиз важен не потому, что это очередная “модель против Claude”, а потому что американский стартап пытается вернуть сильный открытый запуск в область, где последние месяцы много шума создавали китайские Qwen, Kimi, GLM и MiniMax.
По состоянию на 12 апреля 2026 года на странице модели Hugging Face указано: Trinity-Large-Thinking — sparse MoE-модель на 398B параметров, примерно 13B активных параметров на токен, лицензия Apache 2.0, контекст после расширения до 512K. Сравнение с Claude Opus 4.6 тоже есть, но его нужно читать аккуратно: это опубликованные Arcee бенчмарки, а не независимый вердикт “лучше Claude”.

Что именно выпустила Arcee AI
Trinity-Large-Thinking — это не новая базовая модель с нуля, а вариант семейства Trinity-Large, оптимизированный для рассуждений. В карточке модели на Hugging Face Arcee пишет, что модель построена на Trinity-Large-Base и прошла посттренинг с расширенными цепочками рассуждений и обучением с подкреплением для агентных сценариев.
На практике это означает две вещи. Во-первых, модель рассчитана на задачи, где нужно несколько шагов, инструменты и длинный контекст. Во-вторых, она генерирует следы рассуждений в блоках <think>...</think>, и Arcee отдельно предупреждает: эти токены рассуждения нужно сохранять в истории диалога, иначе многошаговый агентный цикл будет работать хуже.
В официальном блоге Arcee релиз описан как “open reasoning model for complex, long-horizon agents and multi-turn tool calling”. Это важная формулировка. Компания продаёт Trinity-Large-Thinking не как универсального победителя всех тестов, а как модель для агентных сценариев: вызов инструментов, планирование, долгие цепочки действий, структурированные ответы.
Характеристики Trinity-Large-Thinking
Основные параметры лучше смотреть не из пересказов, а из Hugging Face и технического отчёта Arcee Trinity Large на arXiv. Там есть небольшая разница в округлении: Hugging Face пишет 398B параметров, сайт Arcee округляет семейство Large до 400B.
| Параметр | Значение | Источник |
|---|---|---|
| Архитектура | Sparse Mixture-of-Experts | Hugging Face / arXiv |
| Всего параметров | 398B в карточке модели, 400B в техническом отчёте и на сайте Arcee | Hugging Face / arXiv / Arcee |
| Активных параметров | примерно 13B на токен | Hugging Face / arXiv |
| Эксперты | 256 экспертов, 4 активных | Hugging Face |
| Контекст | 512K после расширения контекста; Arcee API для Large Thinking указан как 256K BF16 serving | Hugging Face / Arcee Trinity page |
| Лицензия | Apache 2.0 | Hugging Face / блог Arcee |
Слово “открытая” здесь требует оговорки. Весá доступны под Apache 2.0, модель можно скачивать, запускать, дообучать и размещать у себя. Но это не значит, что полностью открыты датасеты, весь процесс обучения и все промежуточные решения. Корректнее говорить “модель с открытыми весами”, а не “полностью открытый ИИ”. Такой же нюанс мы разбирали в материале про открытые и проприетарные модели.
Почему MoE важен для такой модели
398B параметров звучит как тяжёлая модель, которую трудно обслуживать. Но sparse MoE работает иначе: на каждый токен активируется не вся сеть, а небольшая часть экспертов. В Trinity-Large-Thinking это около 13B активных параметров на токен, то есть вычислительная нагрузка ближе к модели среднего размера, хотя общий запас параметров намного больше.
Это не магия и не бесплатная производительность. MoE сложнее обучать и обслуживать: нужно балансировать нагрузку между экспертами, не допускать “схлопывания” отдельных экспертов и следить, чтобы маршрутизация не ломала качество. В техническом отчёте Arcee Trinity Large авторы отдельно описывают SMEBU — стратегию балансировки MoE-нагрузки, которую они ввели для Trinity Large.
Для читателя практический вывод проще: large MoE-модель может быть большой по общему числу параметров и относительно экономной по активным вычислениям. На этом же принципе строятся многие эксперименты с крупными sparse-моделями; похожий инженерный контекст есть в нашем материале про Streaming Experts и запуск триллионной модели на MacBook.
Что с бенчмарками против Claude Opus
Arcee делает ставку на агентные тесты. В карточке Trinity-Large-Thinking модель сравнивается с Opus-4.6, GLM-5, MiniMax-M2.7 и Kimi-K2.5. На части задач Arcee выглядит сильно: Tau2-Airline — 88.0, Tau2-Telecom — 94.7, PinchBench — 91.9, AIME25 — 96.3. Но общая картина неоднородная.
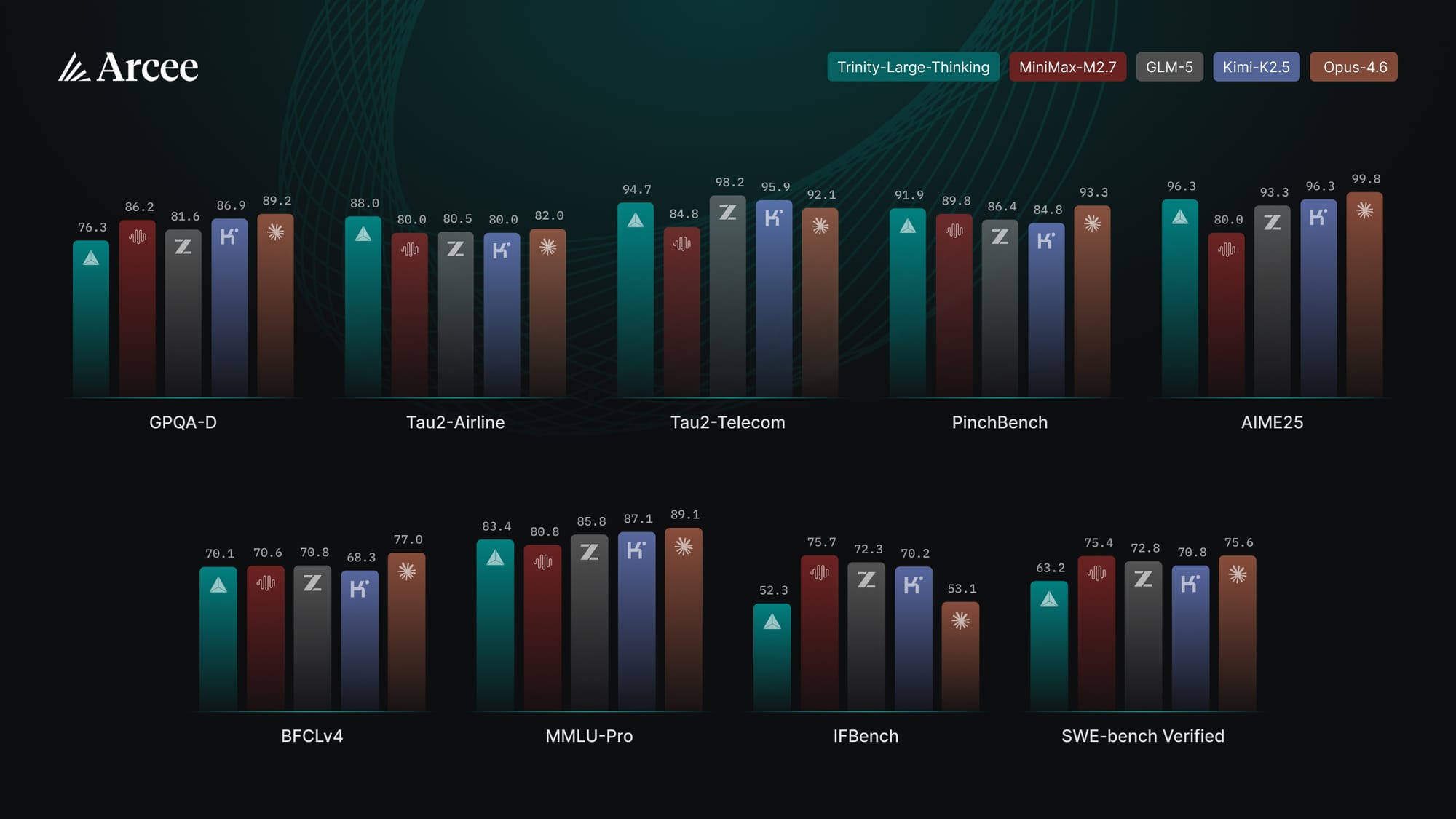
Например, в таблице Hugging Face Trinity-Large-Thinking набирает 91.9 на PinchBench против 93.3 у Opus-4.6. На Tau2-Airline она выше: 88.0 против 82.0. На GPQA-Diamond ситуация обратная: 76.3 у Trinity против 89.2 у Opus-4.6. На SWE-bench Verified Arcee показывает 63.2, а Opus-4.6 — 75.6, причём Arcee уточняет, что все модели оценивались в mini-swe-agent-v2.
Поэтому честный вывод такой: Arcee заявляет сильный релиз для агентных сценариев, но не доказывает универсальное превосходство над передовыми закрытыми моделями. Если вы выбираете модель для агента, эти цифры интересны. Если вам нужна модель для общих задач рассуждения и научных вопросов, одного PinchBench недостаточно. Более широкий контекст гонки моделей рассуждения есть в нашем разборе o3, DeepSeek-R1 и новой парадигмы рассуждения.
Зачем Arcee делает ставку на агентные сценарии
Arcee явно пишет про долгие агентные сценарии, многоходовой вызов инструментов и оркестрацию инструментов. Это не случайный маркетинговый акцент. В агентных продуктах модель должна не просто ответить на один вопрос, а удерживать цель, вызывать инструменты, возвращаться к контексту и не разваливаться на двадцатом шаге.
Тут Trinity-Large-Thinking пытается занять понятную нишу: не “самая умная модель вообще”, а модель с открытыми весами для команд, которые хотят запускать агентные процессы у себя или через API без полной зависимости от закрытого поставщика. Для стартапов и корпоративных команд это аргумент: веса можно проверять, дообучать, размещать у себя, дистиллировать и контролировать, как формулирует Arcee.

The Decoder добавляет финансовый контекст: по их данным, Arcee потратила около половины привлечённого венчурного капитала на проект Trinity-Large-Thinking. В статье также упоминаются 2048 NVIDIA B300 и 33 дня обучения базовой модели; сам блог Arcee подтверждает масштаб инфраструктуры в формулировке “pretraining on 2048 NVIDIA B300s” и посттренинг на 1152 H100.
Где стоит быть осторожным
В релизе Arcee есть сильные сигналы, но есть и обычные для таких запусков ограничения.
- Бенчмарки опубликованы самим поставщиком модели. Их стоит перепроверять на независимых раннерах и собственных задачах.
- Открытые веса не равны полностью открытому обучению. Лицензия Apache 2.0 на веса не раскрывает автоматически данные и весь процесс обучения.
- 512K контекст в характеристиках не означает, что каждый рабочий запуск будет обслуживать полный 512K без ограничений по цене, задержке и памяти.
- Сравнение с Claude Opus уместно только в рамках конкретных тестов. В GPQA-Diamond, MMLU-Pro и SWE-bench Verified Opus-4.6 в опубликованной таблице Arcee выше.
- Модель со следами рассуждений требует аккуратной интеграции: если в многоходовом сценарии вы выкидываете блоки
<think>из истории, Arcee прямо предупреждает о деградации качества.
Это не отменяет релиз. Наоборот, делает его интереснее: Arcee не просто выложила ещё одну контрольную точку модели, а пытается продать инженерный компромисс — большая MoE-модель, открытые веса, длинный контекст и акцент на агентных задачах.
Что это меняет
Trinity-Large-Thinking показывает, что гонка открытых моделей рассуждения не сводится к Китаю и не заканчивается на DeepSeek, Qwen или Kimi. У американских стартапов тоже есть ставка: не догонять закрытые модели во всём сразу, а выбрать узкую зону, где открытые веса дают продуктовую свободу.
Для разработчика главный вопрос звучит так: нужен ли вам максимум качества в общих задачах рассуждения или контролируемая модель для долгих агентных сценариев? Если второе, Arcee Trinity-Large-Thinking стоит поставить в список тестов. Но закупочное решение лучше принимать не по одной таблице, а по своему набору задач, логам вызова инструментов, стоимости инференса и качеству многоходового поведения.
Сильная модель с открытыми весами — это не замена всей закрытой линейке Anthropic или OpenAI. Это ещё один рычаг. И чем больше таких рычагов появляется за пределами пары крупнейших лабораторий, тем меньше разработчики зависят от чужой дорожной карты.