Autoresearch Карпати: ИИ-агент провёл 700 экспериментов за 2 дня
Карпати создал autoresearch — скрипт на 630 строк Python, где ИИ-агент сам ставит ML-эксперименты. За две ночи — 700 итераций и 20 улучшений, которые исследователь не замечал месяцами.
7 марта Андрей Карпати, сооснователь OpenAI, бывший руководитель ИИ в Tesla и основатель Eureka Labs, выложил на GitHub скрипт на 630 строк Python. Скрипт запускает ИИ-агента, который самостоятельно ставит эксперименты по обучению нейросетей: формулирует гипотезу, меняет код, тренирует модель, проверяет результат и повторяет. Карпати лёг спать, а через два дня обнаружил: агент провёл 700 экспериментов и нашёл 20 улучшений, которые сам исследователь не замечал месяцами ручной настройки.
Пост в X набрал больше 8,6 миллиона просмотров за два дня. Карпати написал прямо: «Чтобы получить максимум от доступных инструментов, нужно убрать себя из цепочки. Человек — узкое место».
Что конкретно получилось
Autoresearch работает с небольшой языковой моделью на базе GPT-2. Карпати дал агенту тренировочный скрипт и бюджет: 5 минут GPU-времени на каждый эксперимент. Агент читает исходный код, придумывает изменение (другая скорость обучения, глубина архитектуры, метод нормализации), вносит правку, запускает обучение, измеряет результат.
Если validation loss (в bits per byte) улучшился, изменение сохраняется. Если нет, агент откатывает правку и переходит к следующей гипотезе.
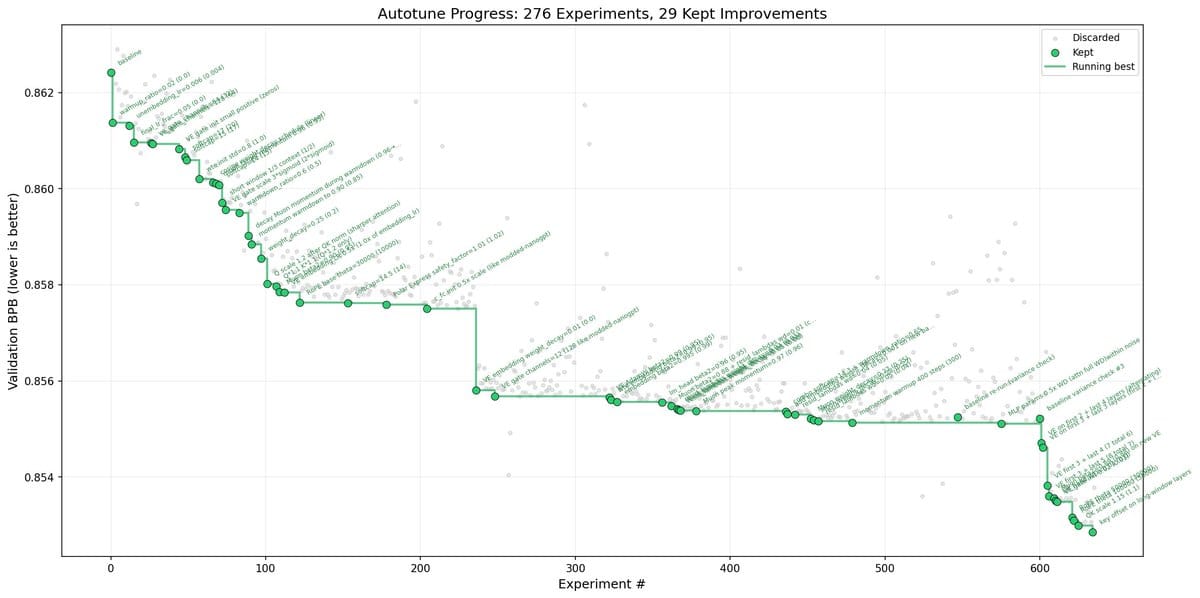
За первую ночь агент провёл 126 экспериментов, loss снизился с 0,9979 до 0,9697. За два дня набралось около 700 итераций и 20 работающих улучшений. Карпати перенёс эти 20 оптимизаций на модель побольше и получил 11% ускорения обучения. Метрика «Time to GPT-2» на лидерборде упала с 2,02 до 1,80 часа.
«Видеть, как агент делает весь этот рабочий процесс от начала до конца, полностью самостоятельно… это дико», написал Карпати. Агент обнаружил ошибки в масштабировании внимания и регуляризации, которые исследователь пропускал на протяжении двадцати лет работы.
Три примитива «цикла Карпати»
Аналитик Janakiram MSV из The New Stack назвал этот паттерн «Karpathy Loop» и выделил три обязательных компонента:
- Редактируемый файл: единственный файл, который агент может менять. Все изменения видны как git diff, каждый эксперимент фиксируется отдельным коммитом. Пространство поиска остаётся обозримым.
- Скалярная метрика: одно число, по которому агент решает, стало лучше или хуже. Без участия человека, без субъективных оценок.
- Временной лимит: фиксированное время на каждый эксперимент. Удвоение размера модели и уменьшение learning rate тратят одинаковый бюджет и оцениваются на равных условиях.
Но самый интересный файл в репозитории — program.md. Это Markdown-документ, где человек описывает, что агент должен искать, чего менять нельзя и когда остановиться. Лабораторный протокол, написанный до экспериментов, а не после.
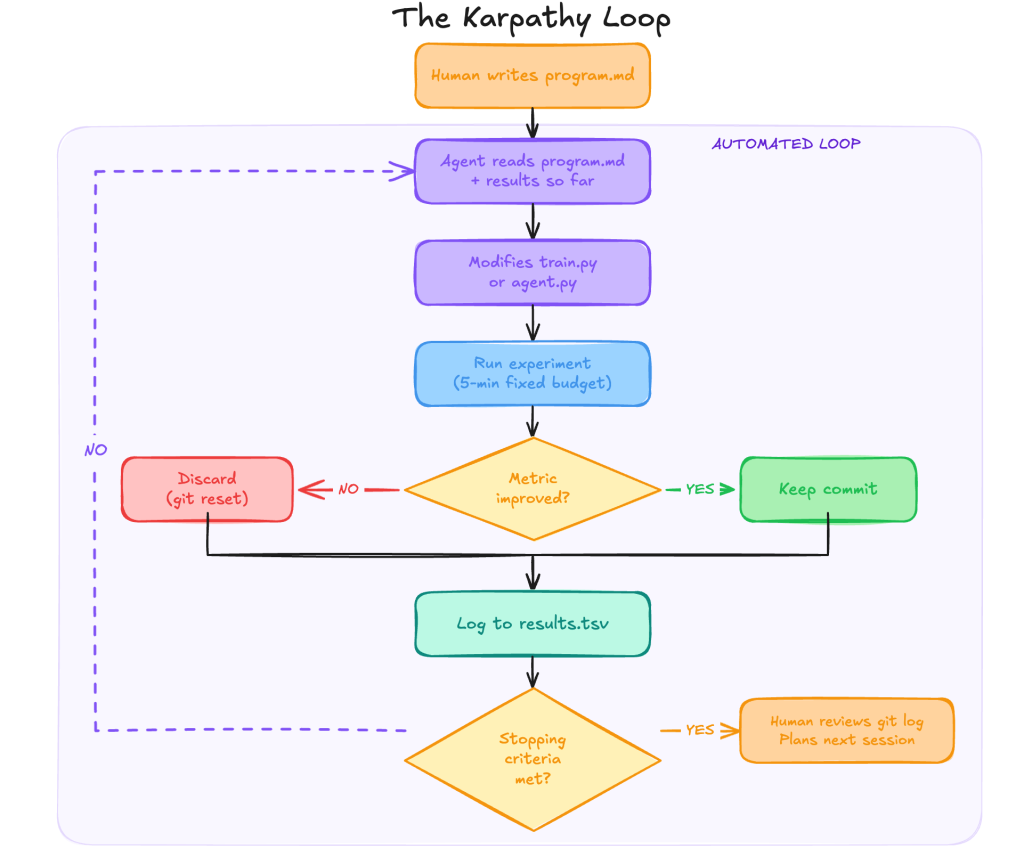
Карпати считает, что написание хорошего program.md важнее, чем написание самого скрипта или настройка агента. Роль исследователя смещается от проведения экспериментов к их проектированию, а это требует более глубокого понимания задачи.
Кто уже попробовал
Тобиас Лютке, CEO Shopify, запустил autoresearch на внутренних данных компании. За ночь агент провёл 37 экспериментов и выдал 19% прирост производительности модели.
Hyperspace AI масштабировали идею: 35 автономных агентов на peer-to-peer сети запустили 333 эксперимента за ночь без присмотра. Агенты на слабом железе (CPU, ноутбуки) оказались изобретательнее, потому что не могли давить вычислительной мощностью и вместо этого экспериментировали с инициализацией весов и нормализацией. Когда один агент обнаружил, что инициализация Кайминга снижает loss на 21%, находка распространилась по сети через протокол GossipSub. За 17 часов агенты независимо переоткрыли техники (RMSNorm, tied embeddings), на формализацию которых у исследователей из Google Brain и OpenAI ушло восемь лет.
Harrison Chase, создатель LangChain, адаптировал паттерн для оптимизации ИИ-агентов. В его версии редактируемый файл — agent.py с промптами и инструментами, а метрика — оценка через LangSmith. Шаблон работает с LangChain, Anthropic SDK и чистым Python.
Эрик Сиу, основатель рекламного агентства Single Grain, применил идею к маркетингу. Его расчёт: обычная маркетинговая команда проводит 30 экспериментов в год, а с автономным циклом можно запускать 36 500+. Агент меняет заголовок landing page или тему письма, измеряет конверсию, сохраняет или откатывает.
Почему это не просто AutoML
Критики указали: автоматический поиск гиперпараметров существует давно. Google, Microsoft и другие лаборатории годами используют AutoML для подбора данных, архитектуры и параметров модели.
Карпати ответил: «Neural architecture search в том виде — настолько слабая версия этого, что это отдельная категория. Бесполезная по сравнению. Здесь настоящий LLM пишет произвольный код, учится на предыдущих экспериментах, имеет доступ в интернет. Даже рядом не стоит».
Разница действительно заметная. AutoML опирается на случайные мутации или эволюционные алгоритмы, то есть на перебор вариантов. Autoresearch использует языковую модель, которая читает результаты прошлых запусков, анализирует неудачи и строит осмысленные гипотезы. Это ближе к работе исследователя, чем к случайному поиску.
Где это не работает
Карпати честен насчёт ограничений: «Всё, что ощущается мягче, хуже». Если у задачи нет чёткой измеримой метрики, автономный цикл буксует. Оценка качества текста, дизайна, UX — здесь агенты пока не заменяют человеческое суждение.
Другая проблема — переобучение на тестовых данных. При сотнях экспериментов агент может подогнать параметры под конкретный тестовый набор, а не найти что-то обобщаемое. Карпати признаёт этот риск, но считает его управляемым при правильно выбранной метрике.
Что дальше
«Все фронтирные лаборатории будут это делать. Это финальный босс», написал Карпати. По его словам, масштабирование — вопрос инженерии: рой агентов совместно настраивает маленькие модели, лучшие идеи переносятся на модели побольше, люди участвуют «по краям».
Карпати хочет перейти от одиночного агента-исследователя к целому сообществу: «Цель — эмулировать не одного PhD, а исследовательское сообщество из таких PhD». Для практиков вывод конкретный: любая метрика, которую можно эффективно вычислить, поддаётся автономной оптимизации. Настройка баз данных, маркетинговые A/B-тесты, подбор параметров RAG-пайплайнов. Код открыт, лицензия MIT.


